How to tame clouds: examples of practical use. Start
Welcome, dear colleagues.
Some time ago, in anticipation of the prospects for the development of virtualization, we moved from the “VMware hosting” model to providing a cloud-based enterprise-level server infrastructure in the form of a full-fledged virtual data center based on VMware solutions. This was largely made possible by the new VMware vCloud product line ( VMware vSphere , VMware vCenter , VMware vCloud Director , VMware vShield ) whose active beta testers our company used to be.
This product family allows us to provide great opportunities in terms of autonomous management of the infrastructure and its components by the client’s employees themselves. Also, in addition to the previously declared billing model for the ordered resources, we now have the opportunity to offer payment for the actual consumption resources (Pay-as-you-Go), which will undoubtedly be in demand by our potential customers, especially all kinds of Internet projects.
')
To run a solution and get, so to speak, an outside view, we turned to Mikhail Mikheev , a well-known VMware product specialist, who has the VCP title for three generations of this company's products and the VMware vExpert title, with the request of independent expert testing of our cloud.
As a result, a number of author posts were born, revealing aspects of working with IT GRAD, the first public cloud in Russia, implemented on VMware vCloud technology, which we bring to your attention .
Recently, IT-Schnick only hears: "cloud clouds clouds." And what is behind this? What is the specifics? Let's talk about this.
Obviously, for different specialists and different business areas, “cloudiness” can be applied in different ways, and different types of clouds can simply be used. I would like to clarify this issue by speaking some specific points.
So, for the first conversation we define a company: normal. There are a hundred people in the staff, plus minus 50. There is an IT department, a server. Maybe there are only two admins, and servers only for the minimally necessary tasks. Or maybe the infrastructure is already more substantial - everything is fine in networks, there are more servers (both terminal, and any auxiliary to AD, and ip-telephony, etc. Perhaps server virtualization is already being used).
Having defined a company, we will define a situation in which “cloud computing” would be interesting.
First of all, this is a new project. I want to go to the new version of MS Exchange. Or start using terminal servers. Or implement ERP. Or…
We solve the problem according to the classical scheme:
It can be argued that if virtualization is already there, then everything is simpler there - we just add virtual machines and that's it. But even in the case of an already deployed virtual infrastructure, at some point in time resources are no longer enough, and more servers are needed. In some percentage of cases, there are problems due to insufficient resources - flaws in planning or budget cuts.
Alternative scheme - to place a new piece of infrastructure outside its server:
The difference between these options is not so much in the number of steps as in the time of their execution and complexity. The second option is much faster, easier to organize and often more interesting in terms of the number and nature of costs. At the same time, we will need to understand what we need in the form “we need four Windows, communicating with each other over the internal network, and the fifth, which also has access to the public network of our company.” Well, and how much they need approximately the resources - such details as:
We are not interested in the physical infrastructure and resources - “somewhere out there” there are plenty of them, and we are happy to be given exactly as much as we need.
Laying down for fault tolerance often (yes, always, frankly) can be less money, since a large cloud infrastructure is easier to provide redundancy at all levels at the expense of scale.
Of course, besides new opportunities, new problems appear - we can talk about them boldly later.
So, we take a specific task. We will immediately stipulate that the task is not from the category of “imagine, for example, a spherical horse in a vacuum,” but, on the contrary, a concrete one. Maybe this is exactly what you think is irrelevant - but with her example you can show the idea and possibilities. Plus, further examples of other tasks will be given.
So, the task.
Check out what a fancy VDI is. To do this, we want to raise a small VMware vSphere + VMware View infrastructure - first in a test form, then turn it into a small pilot project, and if everything is like it, start using it on a larger scale.

What happens: steps 2 and 3, we probably want to deploy within its infrastructure. But step 1 to deploy "inside" is not always convenient - just need iron. Therefore, step 1 we do something like this (Fig. 2):
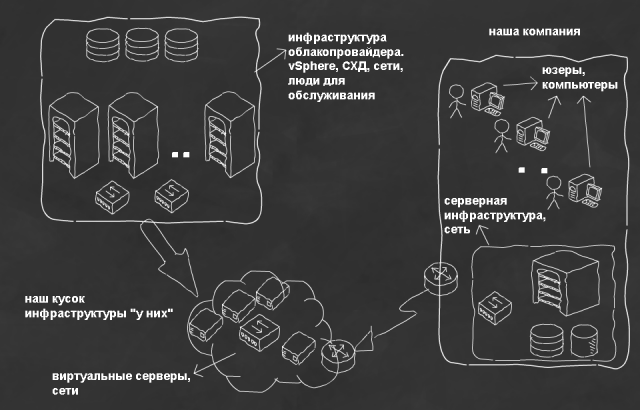
Using the fact that ESX (i) can be launched in VM under ESX (i), we rent the resources for the following virtual machines for the test site of our project:
Some time ago, in anticipation of the prospects for the development of virtualization, we moved from the “VMware hosting” model to providing a cloud-based enterprise-level server infrastructure in the form of a full-fledged virtual data center based on VMware solutions. This was largely made possible by the new VMware vCloud product line ( VMware vSphere , VMware vCenter , VMware vCloud Director , VMware vShield ) whose active beta testers our company used to be.
This product family allows us to provide great opportunities in terms of autonomous management of the infrastructure and its components by the client’s employees themselves. Also, in addition to the previously declared billing model for the ordered resources, we now have the opportunity to offer payment for the actual consumption resources (Pay-as-you-Go), which will undoubtedly be in demand by our potential customers, especially all kinds of Internet projects.
')
To run a solution and get, so to speak, an outside view, we turned to Mikhail Mikheev , a well-known VMware product specialist, who has the VCP title for three generations of this company's products and the VMware vExpert title, with the request of independent expert testing of our cloud.
As a result, a number of author posts were born, revealing aspects of working with IT GRAD, the first public cloud in Russia, implemented on VMware vCloud technology, which we bring to your attention .
Recently, IT-Schnick only hears: "cloud clouds clouds." And what is behind this? What is the specifics? Let's talk about this.
Obviously, for different specialists and different business areas, “cloudiness” can be applied in different ways, and different types of clouds can simply be used. I would like to clarify this issue by speaking some specific points.
So, for the first conversation we define a company: normal. There are a hundred people in the staff, plus minus 50. There is an IT department, a server. Maybe there are only two admins, and servers only for the minimally necessary tasks. Or maybe the infrastructure is already more substantial - everything is fine in networks, there are more servers (both terminal, and any auxiliary to AD, and ip-telephony, etc. Perhaps server virtualization is already being used).
Having defined a company, we will define a situation in which “cloud computing” would be interesting.
First of all, this is a new project. I want to go to the new version of MS Exchange. Or start using terminal servers. Or implement ERP. Or…
We solve the problem according to the classical scheme:
- Justify the project.
- Approve the budget.
- Wait for the servers.
- Start the project.
It can be argued that if virtualization is already there, then everything is simpler there - we just add virtual machines and that's it. But even in the case of an already deployed virtual infrastructure, at some point in time resources are no longer enough, and more servers are needed. In some percentage of cases, there are problems due to insufficient resources - flaws in planning or budget cuts.
Alternative scheme - to place a new piece of infrastructure outside its server:
- Justify the project.
- Sign a contract with the cloud-owner company (in this case, IT-GRAD company).
- Start the project.
The difference between these options is not so much in the number of steps as in the time of their execution and complexity. The second option is much faster, easier to organize and often more interesting in terms of the number and nature of costs. At the same time, we will need to understand what we need in the form “we need four Windows, communicating with each other over the internal network, and the fifth, which also has access to the public network of our company.” Well, and how much they need approximately the resources - such details as:
- configuration of physical servers on which these virtualkeys will work;
- wiring diagram, physical network switching;
- fears "but there is enough / and not extra resources."
We are not interested in the physical infrastructure and resources - “somewhere out there” there are plenty of them, and we are happy to be given exactly as much as we need.
Laying down for fault tolerance often (yes, always, frankly) can be less money, since a large cloud infrastructure is easier to provide redundancy at all levels at the expense of scale.
Of course, besides new opportunities, new problems appear - we can talk about them boldly later.
So, we take a specific task. We will immediately stipulate that the task is not from the category of “imagine, for example, a spherical horse in a vacuum,” but, on the contrary, a concrete one. Maybe this is exactly what you think is irrelevant - but with her example you can show the idea and possibilities. Plus, further examples of other tasks will be given.
So, the task.
Check out what a fancy VDI is. To do this, we want to raise a small VMware vSphere + VMware View infrastructure - first in a test form, then turn it into a small pilot project, and if everything is like it, start using it on a larger scale.
What happens: steps 2 and 3, we probably want to deploy within its infrastructure. But step 1 to deploy "inside" is not always convenient - just need iron. Therefore, step 1 we do something like this (Fig. 2):
Using the fact that ESX (i) can be launched in VM under ESX (i), we rent the resources for the following virtual machines for the test site of our project:
- 1 or 2 virtual machines under ESX (i), 1 vCPU, 4 GB of RAM
- 1 VM under vCenter, 1 vCPU, 2 GB of RAM
- 1 VM under View Server, 1 vCPU, 1 GB of RAM. >> continuation ...
Source: https://habr.com/ru/post/115742/
All Articles