Web Cluster - Real Application Experience
Greetings, dear accomplices!
This article is about how we implemented a web cluster for a news portal (with a peak of visits of 130 thousand unique visitors per day - this is 7 TB of traffic for 3 days - elections and the next two. Now, on average, the cluster distributes 35-40 TB of traffic in month) about how programmers and journalists understand the same tasks in different ways, about how to achieve the same goal, going in different ways.
It will be interesting to those who want to build an easily scalable geographically distributed web cluster, without investing astronomical sums in equipment (and by the standards of television - there will be generally ridiculous sums).
')
I’m more than confident that marketers pushing the uber solutions of freshly released products that have the words “scalable web cluster” or “horizontal infinite scalable web cluster” in their names hate me.
I am more than confident that our customers' competitors will be surprised by the simplicity of the solution we used.
I will not give banal configs, which can be found in any totorial on configuring PHP, Nginx and Firebird (the latter, strictly speaking, has nothing to configure - everything works from a half-kick out of the box) and generally I will talk about the essence decisions, not about which version of PHP is better.
Experienced designers are unlikely to be interested - they already know everything, but those who are just starting their way in the difficult task of designing systems are more difficult than “Hello, World!” Will certainly have something to do - the solution in combat mode will soon be like 2 years at the same time, there were no architectural problems (although the failure of two hard drives on two of the three nodes at once was, but no one noticed anything - the websites were opening a little slower than usual).
So, a couple of words, how it all began. Once upon a time there was a saytik of a group of independent journalists who dreamed of becoming a real television (looking ahead, I’ll say that they did it - they created their own, quite successful television with “blackjack and ...” - hereinafter). Our country is small, nothing terrible happens (and we are happy about it), but once in 4 years we traditionally hold elections to the Parliament.Which already traditionally does not elect the President. (Fear not, politics will not be here, it’s just for a general understanding of the moment).
Of course, in the period before the elections and a little after all the Internet media is very sausage. Some sites are not just lying, they are lying, some periodically trying to give at least a line of text, but the problem is universal and well-known - sites can not cope with the influx of visitors. I'm talking about ordinary text sites. And our customers site was unusual. The fact is that they had a video - news stories, they produced 10 gigabytes per month - at that time, now they create so many videos per day. On top of that (this is the last mention of politics, honestly) these journalists were not particularly loyal to the authorities. They talked and wrote what they wanted.They are quite insolent, right? We always position ourselves as mercenaries - the client proposes a task, we offer its solution. All the rest does not interest us, we maintain neutrality.
We were faced with a task - to offer a solution for news sites, which would not only allow us to withstand the influx of 50-100 thousand visitors, but would also be geographically scattered around the world and controlled from amobile bunker of any point in the Universe of the planet. Of course, the geographical spread of cluster nodes remained with us. As a result, we proposed the following scheme (the artist is none of me, you excuse me):
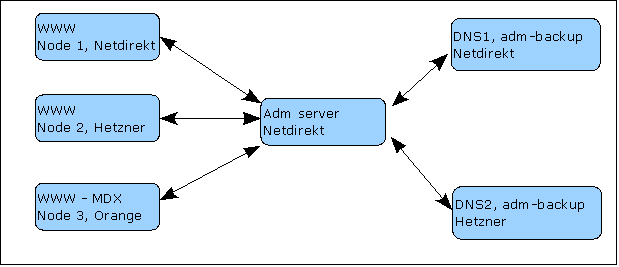
(This is a simplified scheme for November, later on almost all servers were transferred to Hetzner, since Netdirekt had a channel sausage at the time. Now they have a much better situation with the network).
Ordinary visitors see one of the 3 servers, and at the same time, we made so that the “light” content in the form of text and pictures was pulled by all visitors from Moldova from one of the 3, and the “heavy” content (video) was pulled from server located at your local provider. External visitors simply did not see the Moldavian mirror and all content was pulled from one of the German servers.
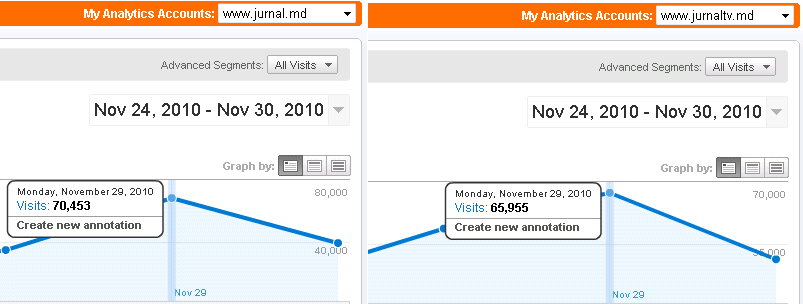
This is what we did with the visitors as a result (each part of the portal has its own counter):
This scheme allows you to change the management server at any time, checks the availability of cluster nodes itself, scales easily - Amazon EC was also considered a backup, moreover, Amazon EC was even used for video streaming for about 4 months, but it was decided to move the streaming nodes to the German Hetzner at the high cost of traffic.
Immediately 2 weeks before the “X” hour, we took backup servers and kept them ready (but users didn’t see them, since keeping the server active is somewhat cheaper than using it in combat mode - only because of the traffic).
How does all this work? Very simple - silently and around the clock;).
On the management server (as I mentioned, the portal has 2 large “sections”: news as text with pictures and news as text digest and video — 2 servers are de facto used, but for simplicity I have portrayed one) usually referred to as a content management system.
The main task of this server is to allow journalists to add news. Once at a certain time (3-5 minutes), a script is launched that creates ... an offline copy of the site. Of course, only pages that are modified or that need to be rebuilt due to crosslinks and dependencies are generated.
This is very easy to implement using generators (sequense) and cascading triggers in Firebird — the procedure only requires changes to the main page of the site, and cascading triggers update all dependencies by marking each page that needs to be updated. The mark is set not in the form of the 1/0 flag, but in the form of a unique number obtained on the basis of the generator. The script for creating an offline version at start-up recognizes the new value of the generator, reads the value of this generator from its previous launch and re-creates all pages in the resulting range. At the same time, since we use the Firebird transaction mechanism — the script doesn’t give a damn what changes occur during its execution — that is, We always create a holistic and consistent version of the site, so that reporters would not do this.
Thus, we create a master copy of the portal (or two portals, if you wish - text and video). The script (as well as the admin itself) is written in PHP and uses ADODB to work with Firebird - so you can simply rebuild it at the request of the customer *.
(* But we are going to get rid of ADODB soon in all our future projects - its versatility only hurts, as the normal database engine that allows you to use all the features of the Firebird SQL server (as well as the others) is not implemented there - for example , it is impossible to catch exceptions when selecting from selective procedures, there is no flexible transaction management and in general, these classes have too many AI - I prefer to decide for myself when I want to roll back the transaction, and when to confirm.)
The only thing that had to be changed in the Firebird settings is the value of the cache size of the database pages - since the number of connections to the database is very small (rarely more than 50-60 simultaneous connections), then the number of pages was experimentally increased to 2048 (we use the Classic option , for Super architecture, this value can be easily increased 10 times, since there is a common page cache. In the upcoming version of Firebird 3.0, the developers promise one SMP-friendly architecture with a shared cache, so that it can be quite useful to use large values for astroek page cache).
Then, with the help of the usual rsync, the difference of changes is spread over the mirrors, which are the usual nodes for the distribution of statics based on Nginx. I think it is not necessary to tell what a 4-core server with 12 GB of RAM is capable of when distributing static alone? ;-)
At the same time, 10% of the channel of each node (this is just 10 or 100 megabits, depending on the specific connection) is reserved for synchronization. Synchronization takes place in 2 stages - first “heavy” content is synchronized - pictures and video, then - text (html / xml / js).
Sometimes (when channels are loaded from the managing server to the mirrors), the visitor may see small discrepancies in the form of unloading pictures and / or video clips - as the round-robin DNS is used, the user can receive the page text from one mirror, and link to the video from another . This does not prevent the portal from working - the text is always there, and a picture or video will be announced sooner or later.
Since there are dynamic forms on the websites - for example, a subscription to the newsletter - these forms are processed by a separate dedicated server (it is not shown in the diagram, but essentially it does not change). Even if we assume that all visitors at the same time break down to subscribe to the news and this server "lies down" - nothing bad will happen - the forms are loaded in the iframe and the lack of these forms is not reflected in the availability of news.
Adding a new node is simple - first a new mirror is synchronized with the main copy (this happens in parallel with the normal operation of the synchronizer), then the record is added to the DNS and ... no one notices anything.
Deleting a node is easier - it simply removes the record from the DNS. Adding and deleting is quite amenable to automation (that's exactly what we did with the part that was responsible for web streaming about 1000 megabit streams on Amazom EC), but if you suddenly decide to repeat this, I advise you to first calculate how much the primary data synchronization takes (we have it 2 Gigabytes for the “light version of the portal” and about 1 Terabyte for the video, stored only for the last few months).
That is why the dynamic addition / deletion of nodes from the spare pool was removed after some time of the project’s work - the content takes up too much and the script is too paranoid - the nodes are removed at every connection problem with them.
Separately, it is worth mentioning the calculations display news. I got the impression that a favorite activity of journalists (besides writing / filming reports) is a measure of the number of visitors to one or another news item. We had to spend about a liter of blood and a kilometer of nerves in order to convince the journalistic fraternity that it was not necessary to display the changes in the meters in real time.
Programmers are well aware that finding out how many people are currently reading an article is simply impossible, you can only count the number of requests for an article from the server, for journalists it’s the same thing. :)
To count the views, we contacted Kiril Korinsky (also known as catap ), who kindly agreed to add the URL counting feature to his Nginx branch. Well, after that everything is simple - all nodes are periodically polled and page counts are taken into account in the properties of the page itself. Since the counters (ie, the values themselves) are stored in separate files (now it is one file per news item, soon we plan to make a group of counters in one file in order to reduce the number of files themselves) - then during synchronization, it’s not the site page that is transferred entirely, but only a file counter. With a large number of files, this creates an additional load on the disk subsystem - therefore, using the same approach, immediately think about how to split the counters into groups - we stopped at splitting the counters by news type and date - the files are relatively small and over time they stop changing , as the old news practically no one is interested.
In short, the advantages of the solution we used:
Well, a couple of minuses, so that not everything seemed so cloudless:
And literally a little pinch of experience, which will allow to diversify the fresh porridge of everyday life.
To store the offline copy of the site, we use the JFS file system. It has also proven itself very well when working with many small files and when working with large files (in my experience, XFS can almost instantly delete a file 200-300GB in size).
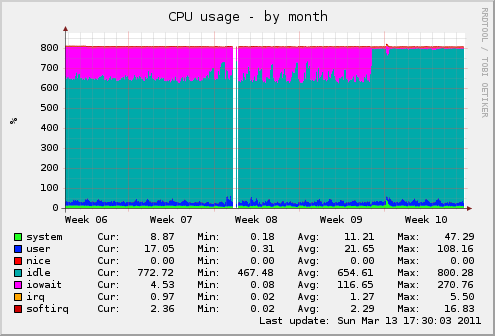
So - by default, the file system was mounted with the default settings. But since we have a lot of files over time, disk operations began to slow down a bit. Since we do not need the last file access time, I added the “noatime” option to the file system mount options. That's what happened - the moment of adding, I think, you define it yourself:
I repeat briefly - for stable operation in normal mode it is used:
Cluster nodes are scattered geographically and are located at different providers.
In the case of expected events that attract a large number of visitors - additional servers are connected to distribute content.
About 40TB of traffic is consumed per month, the total amount of content is just over 1 Terabyte, video content is stored for about 3 months.
I will be happy to answer questions habrasoobschestva.
This article is about how we implemented a web cluster for a news portal (with a peak of visits of 130 thousand unique visitors per day - this is 7 TB of traffic for 3 days - elections and the next two. Now, on average, the cluster distributes 35-40 TB of traffic in month) about how programmers and journalists understand the same tasks in different ways, about how to achieve the same goal, going in different ways.
It will be interesting to those who want to build an easily scalable geographically distributed web cluster, without investing astronomical sums in equipment (and by the standards of television - there will be generally ridiculous sums).
')
I’m more than confident that marketers pushing the uber solutions of freshly released products that have the words “scalable web cluster” or “horizontal infinite scalable web cluster” in their names hate me.
I am more than confident that our customers' competitors will be surprised by the simplicity of the solution we used.
I will not give banal configs, which can be found in any totorial on configuring PHP, Nginx and Firebird (the latter, strictly speaking, has nothing to configure - everything works from a half-kick out of the box) and generally I will talk about the essence decisions, not about which version of PHP is better.
Experienced designers are unlikely to be interested - they already know everything, but those who are just starting their way in the difficult task of designing systems are more difficult than “Hello, World!” Will certainly have something to do - the solution in combat mode will soon be like 2 years at the same time, there were no architectural problems (although the failure of two hard drives on two of the three nodes at once was, but no one noticed anything - the websites were opening a little slower than usual).
So, a couple of words, how it all began. Once upon a time there was a saytik of a group of independent journalists who dreamed of becoming a real television (looking ahead, I’ll say that they did it - they created their own, quite successful television with “blackjack and ...” - hereinafter). Our country is small, nothing terrible happens (and we are happy about it), but once in 4 years we traditionally hold elections to the Parliament.
Of course, in the period before the elections and a little after all the Internet media is very sausage. Some sites are not just lying, they are lying, some periodically trying to give at least a line of text, but the problem is universal and well-known - sites can not cope with the influx of visitors. I'm talking about ordinary text sites. And our customers site was unusual. The fact is that they had a video - news stories, they produced 10 gigabytes per month - at that time, now they create so many videos per day. On top of that (this is the last mention of politics, honestly) these journalists were not particularly loyal to the authorities. They talked and wrote what they wanted.
We were faced with a task - to offer a solution for news sites, which would not only allow us to withstand the influx of 50-100 thousand visitors, but would also be geographically scattered around the world and controlled from a
(This is a simplified scheme for November, later on almost all servers were transferred to Hetzner, since Netdirekt had a channel sausage at the time. Now they have a much better situation with the network).
Ordinary visitors see one of the 3 servers, and at the same time, we made so that the “light” content in the form of text and pictures was pulled by all visitors from Moldova from one of the 3, and the “heavy” content (video) was pulled from server located at your local provider. External visitors simply did not see the Moldavian mirror and all content was pulled from one of the German servers.
This is what we did with the visitors as a result (each part of the portal has its own counter):
This scheme allows you to change the management server at any time, checks the availability of cluster nodes itself, scales easily - Amazon EC was also considered a backup, moreover, Amazon EC was even used for video streaming for about 4 months, but it was decided to move the streaming nodes to the German Hetzner at the high cost of traffic.
Immediately 2 weeks before the “X” hour, we took backup servers and kept them ready (but users didn’t see them, since keeping the server active is somewhat cheaper than using it in combat mode - only because of the traffic).
How does all this work? Very simple - silently and around the clock;).
On the management server (as I mentioned, the portal has 2 large “sections”: news as text with pictures and news as text digest and video — 2 servers are de facto used, but for simplicity I have portrayed one) usually referred to as a content management system.
The main task of this server is to allow journalists to add news. Once at a certain time (3-5 minutes), a script is launched that creates ... an offline copy of the site. Of course, only pages that are modified or that need to be rebuilt due to crosslinks and dependencies are generated.
This is very easy to implement using generators (sequense) and cascading triggers in Firebird — the procedure only requires changes to the main page of the site, and cascading triggers update all dependencies by marking each page that needs to be updated. The mark is set not in the form of the 1/0 flag, but in the form of a unique number obtained on the basis of the generator. The script for creating an offline version at start-up recognizes the new value of the generator, reads the value of this generator from its previous launch and re-creates all pages in the resulting range. At the same time, since we use the Firebird transaction mechanism — the script doesn’t give a damn what changes occur during its execution — that is, We always create a holistic and consistent version of the site, so that reporters would not do this.
Thus, we create a master copy of the portal (or two portals, if you wish - text and video). The script (as well as the admin itself) is written in PHP and uses ADODB to work with Firebird - so you can simply rebuild it at the request of the customer *.
(* But we are going to get rid of ADODB soon in all our future projects - its versatility only hurts, as the normal database engine that allows you to use all the features of the Firebird SQL server (as well as the others) is not implemented there - for example , it is impossible to catch exceptions when selecting from selective procedures, there is no flexible transaction management and in general, these classes have too many AI - I prefer to decide for myself when I want to roll back the transaction, and when to confirm.)
The only thing that had to be changed in the Firebird settings is the value of the cache size of the database pages - since the number of connections to the database is very small (rarely more than 50-60 simultaneous connections), then the number of pages was experimentally increased to 2048 (we use the Classic option , for Super architecture, this value can be easily increased 10 times, since there is a common page cache. In the upcoming version of Firebird 3.0, the developers promise one SMP-friendly architecture with a shared cache, so that it can be quite useful to use large values for astroek page cache).
Then, with the help of the usual rsync, the difference of changes is spread over the mirrors, which are the usual nodes for the distribution of statics based on Nginx. I think it is not necessary to tell what a 4-core server with 12 GB of RAM is capable of when distributing static alone? ;-)
At the same time, 10% of the channel of each node (this is just 10 or 100 megabits, depending on the specific connection) is reserved for synchronization. Synchronization takes place in 2 stages - first “heavy” content is synchronized - pictures and video, then - text (html / xml / js).
Sometimes (when channels are loaded from the managing server to the mirrors), the visitor may see small discrepancies in the form of unloading pictures and / or video clips - as the round-robin DNS is used, the user can receive the page text from one mirror, and link to the video from another . This does not prevent the portal from working - the text is always there, and a picture or video will be announced sooner or later.
Since there are dynamic forms on the websites - for example, a subscription to the newsletter - these forms are processed by a separate dedicated server (it is not shown in the diagram, but essentially it does not change). Even if we assume that all visitors at the same time break down to subscribe to the news and this server "lies down" - nothing bad will happen - the forms are loaded in the iframe and the lack of these forms is not reflected in the availability of news.
Adding a new node is simple - first a new mirror is synchronized with the main copy (this happens in parallel with the normal operation of the synchronizer), then the record is added to the DNS and ... no one notices anything.
Deleting a node is easier - it simply removes the record from the DNS. Adding and deleting is quite amenable to automation (that's exactly what we did with the part that was responsible for web streaming about 1000 megabit streams on Amazom EC), but if you suddenly decide to repeat this, I advise you to first calculate how much the primary data synchronization takes (we have it 2 Gigabytes for the “light version of the portal” and about 1 Terabyte for the video, stored only for the last few months).
That is why the dynamic addition / deletion of nodes from the spare pool was removed after some time of the project’s work - the content takes up too much and the script is too paranoid - the nodes are removed at every connection problem with them.
Separately, it is worth mentioning the calculations display news. I got the impression that a favorite activity of journalists (besides writing / filming reports) is a measure of the number of visitors to one or another news item. We had to spend about a liter of blood and a kilometer of nerves in order to convince the journalistic fraternity that it was not necessary to display the changes in the meters in real time.
Programmers are well aware that finding out how many people are currently reading an article is simply impossible, you can only count the number of requests for an article from the server, for journalists it’s the same thing. :)
To count the views, we contacted Kiril Korinsky (also known as catap ), who kindly agreed to add the URL counting feature to his Nginx branch. Well, after that everything is simple - all nodes are periodically polled and page counts are taken into account in the properties of the page itself. Since the counters (ie, the values themselves) are stored in separate files (now it is one file per news item, soon we plan to make a group of counters in one file in order to reduce the number of files themselves) - then during synchronization, it’s not the site page that is transferred entirely, but only a file counter. With a large number of files, this creates an additional load on the disk subsystem - therefore, using the same approach, immediately think about how to split the counters into groups - we stopped at splitting the counters by news type and date - the files are relatively small and over time they stop changing , as the old news practically no one is interested.
In short, the advantages of the solution we used:
- Using static sites as nodes of a web cluster allows you to reduce the administration of the entire cluster to several routine tasks - updating the operating system of nodes and paying for traffic. The same item allows geographically scattering cluster nodes, which, together with GEO-DNS, can be considered generally as some kind of analogue of the content delivery network (CDN) - in fact, this is it.
- Using the transactional mechanism of the database and transferring the logic to the database itself allows you to always have a holistic and logically consistent version of the site - however, I would be very surprised if the "slice" of data from the server would be logically incomplete.
- If the expected influx of visitors - a simple increase in cluster nodes, you can easily cope with it. In our case, the full commissioning of a new node took just over an hour for the text part of the portal and about a day (you cannot shove a non-pushed one) for the video. If you put up with partial synchronization of sites and the rest is “topped up” in the background - then the input of a new node for video can also be reduced to an hour.
- The administrative server can be made from any of the nodes (if necessary) - simply deploy the backup database (in compressed form about a hundred megabytes). The rest of the content is already there.
Well, a couple of minuses, so that not everything seemed so cloudless:
- The solution is not suitable for cases when there are parts of the site that different users need to see differently, i.e. when according to the condition of the problem the pages are generated personally for each user. In our case, this turned out to be unnecessary.
- Visitor counters are updated with a delay of about half an hour. Tolerant, but you have to convince the client in this for a long time.
- Most of the problems are caused by synchronization with the local mirror - our providers still do not sell traffic at a price of 7 euros per terabyte, and if they provide 100 honest megabytes to the world, then at very inadequate prices.
- Design a less paranoid tracking system for cluster nodes - ours turned out to be too sensitive, we had to switch the addition and removal of nodes into manual mode.
And literally a little pinch of experience, which will allow to diversify the fresh porridge of everyday life.
To store the offline copy of the site, we use the JFS file system. It has also proven itself very well when working with many small files and when working with large files (in my experience, XFS can almost instantly delete a file 200-300GB in size).
So - by default, the file system was mounted with the default settings. But since we have a lot of files over time, disk operations began to slow down a bit. Since we do not need the last file access time, I added the “noatime” option to the file system mount options. That's what happened - the moment of adding, I think, you define it yourself:
I repeat briefly - for stable operation in normal mode it is used:
- 3 servers for content distribution
- 2 servers for admin
- 2 servers for DNS and tracking systems for other servers.
Cluster nodes are scattered geographically and are located at different providers.
In the case of expected events that attract a large number of visitors - additional servers are connected to distribute content.
About 40TB of traffic is consumed per month, the total amount of content is just over 1 Terabyte, video content is stored for about 3 months.
I will be happy to answer questions habrasoobschestva.
Source: https://habr.com/ru/post/115373/
All Articles