Examples of xpath requests to html
Xpath is a language for querying an xml or xhtml document element. Like SQL, xpath is a declarative query language. To get the data of interest, you just need to create a query that describes this data. All the "black" work for you will perform the interpreter language xpath.
Very comfortable, isn't it? Let's see what features xpath offers to access web page nodes.
I bring to your attention a small laboratory work, during which I will demonstrate the creation of xpath requests to a web page. You will be able to repeat the requests I have cited and, most importantly, you will try to fulfill your own. I hope that thanks to this article will be equally interesting to beginners and programmers familiar with xpath xml.
For the laboratory, we need:
- web page xhtml;
- Mozilla Firefox browser with add-ons;
- firebug ;
- firePath ;
(you can use any other browser with visual support for xpath)
- a little time.
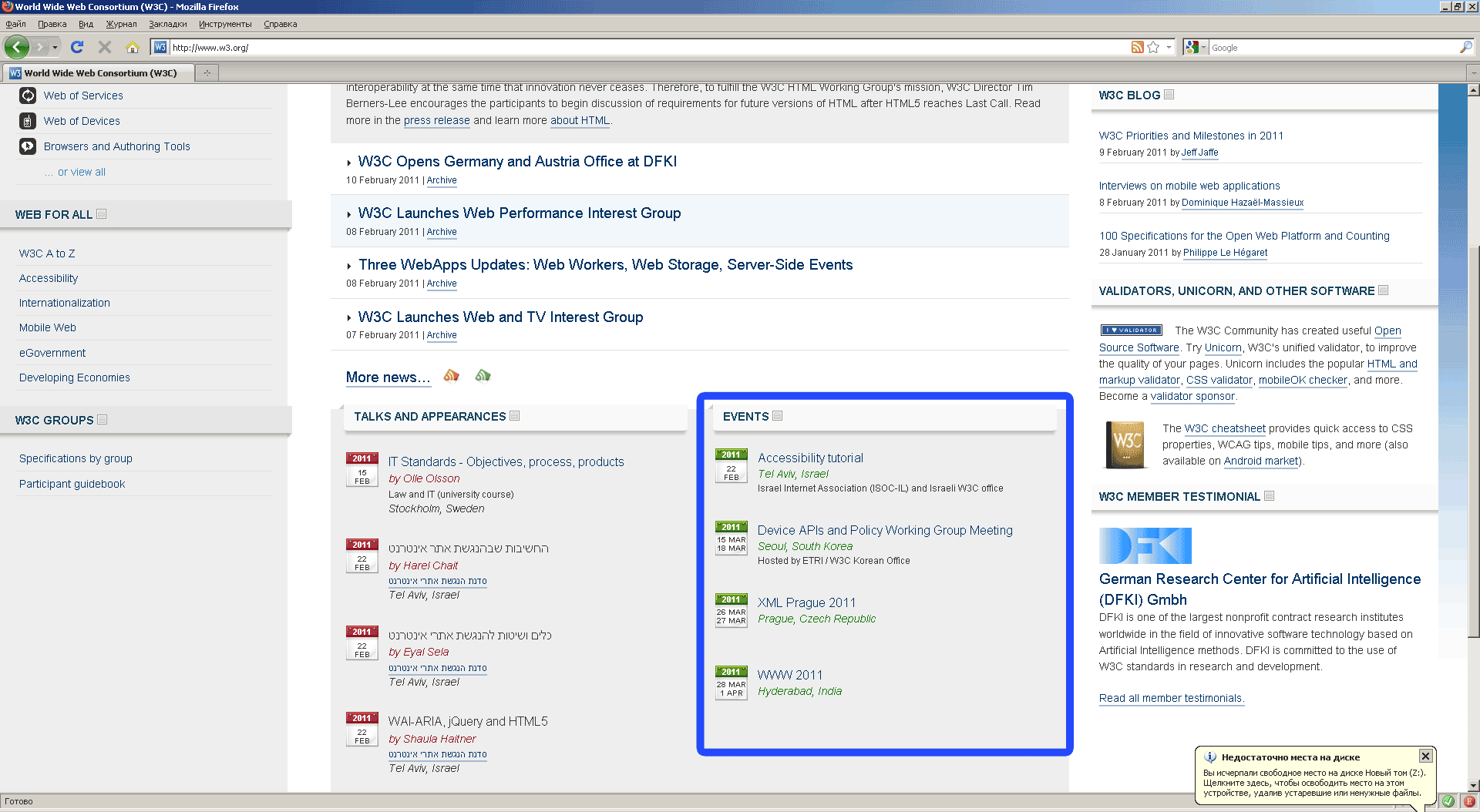
As a web page for the experiment, I propose the main page of the website of the world wide web consortium (' http://w3.org '). It is this organization that develops the xquery languages (xpath), the xhtml specification, and many other Internet standards.
')
Obtain information about the consortium conferences from the xhtml-code of the w3.org main page using xpath queries.
Let's start writing xpath requests.
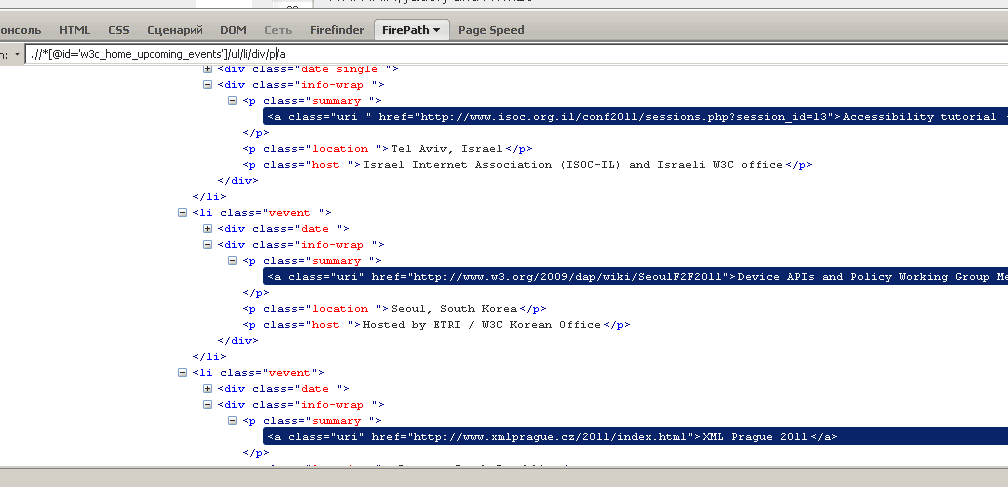
Open the Firepath tab in FireBug, select the element for analysis with the selector, click: Firepath created a xpath request to the selected element.
If you selected the title of the first event, the request will be as follows:
After removing the extra indexes, the request will match all elements of the “title” type.
Firepath highlights items that match the query. You can see in real time which document nodes match the request.
Go ahead. We create requests to search for conference venues and their sponsors either by using the selector or by modifying the first request.
Request for information on conference venues:
So we get a list of sponsors:
Let's go back to the created queries and see how they work.
Consider in detail the first request

In this query, I highlighted three parts to demonstrate the capabilities of xpath. (The division into parts is sensible)
First part
.// - recursive descent to zero or more hierarchy levels from the current context. In our case, the current context is the document root.
The second part of
* - any item
[@ id = 'w3c_home_upcoming_events'] is a predicate based on which we search for a node that has the id attribute equal to 'w3c_home_upcoming_events'. XHTML element identifiers must be unique. Therefore, the query “any item with a specific ID” must return the only node we are looking for.
We can replace * with the exact name of the div node in this query.
Thus, we descend through the document tree to the node we need div [@ id = 'w3c_home_upcoming_events']. We absolutely do not care what nodes the DOM tree consists of and how many levels of hierarchy remain above.
The third part
/ ul / li / div / p / a –xpath path to a specific element. The path consists of the steps of addressing and the condition of checking nodes (ul, li, etc.). Steps are separated by a "/" (slash).
It is not always possible to access a node of interest using a predicate or addressing steps. Very often at the same level of the hierarchy there are as many nodes of the same type as possible and it is necessary to select “only the first” or “only the second” nodes. For such cases, collections are provided.
The xpath collections allow you to access an item by its index. The indices correspond to the order in which the elements were presented in the original document. The sequence number in the collections is counted from one.
Based on the fact that the “venue” is always the second paragraph after the “conference title”, we get the following request:
Where p [2] is the second element in the set for each node of the list / ul / li / div.
Similarly, we can get a list of sponsors by asking:
In XPath there are many functions for working with items within the collection. I will give only some of them.
last ():
Returns the last item in the collection.
Query
The first () function is not provided. To access the first element, use the index "1".
text ():
Returns the test content of the item.
position () and mod:
position () - returns the position of the element in the set.
mod is the remainder of the division.
By combining these functions we can get:
- not even
- even elements:
Comparison operations
Full feature list
Try to get:
- even URL links from the left menu “Standards”;
- headlines of all news, except the first from the main page of w3c.org.
In a simple example, we saw the capabilities of xpath for accessing web page nodes.
Xpath is an industry standard for accessing xml and xhtml elements, xslt transformations.
You can use it to parse any html page. If the source html-code contains significant errors in the markup, pass it through tidy . Errors will be corrected.
Try to abandon regular expressions when parsing web pages in favor of xpath.
This will make your code easier, more understandable. You will make fewer mistakes. Reduce debugging time.
Firepath add-on Mozzilla Firefox
Brief annotation of the language in Wikipedia
A good xpath reference. Do not pay attention to the fact that it is for the .NET Framework. Xpath works the same in all environments, except for a couple of specific functions.
Xpath 1.0 specification
Specification xpath 1.0 in Russian
XQuery 1.0 and XPath 2.0
Tidy
PHP5 tidy :: repairFile
Very comfortable, isn't it? Let's see what features xpath offers to access web page nodes.
Creating a request for web page nodes
I bring to your attention a small laboratory work, during which I will demonstrate the creation of xpath requests to a web page. You will be able to repeat the requests I have cited and, most importantly, you will try to fulfill your own. I hope that thanks to this article will be equally interesting to beginners and programmers familiar with xpath xml.
For the laboratory, we need:
- web page xhtml;
- Mozilla Firefox browser with add-ons;
- firebug ;
- firePath ;
(you can use any other browser with visual support for xpath)
- a little time.
As a web page for the experiment, I propose the main page of the website of the world wide web consortium (' http://w3.org '). It is this organization that develops the xquery languages (xpath), the xhtml specification, and many other Internet standards.
')
Task
Obtain information about the consortium conferences from the xhtml-code of the w3.org main page using xpath queries.
Let's start writing xpath requests.
First xpath request
Open the Firepath tab in FireBug, select the element for analysis with the selector, click: Firepath created a xpath request to the selected element.
If you selected the title of the first event, the request will be as follows:
.//*[@id='w3c_home_upcoming_events']/ul/li[1]/div[2]/p[1]/aAfter removing the extra indexes, the request will match all elements of the “title” type.
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p/aFirepath highlights items that match the query. You can see in real time which document nodes match the request.
Go ahead. We create requests to search for conference venues and their sponsors either by using the selector or by modifying the first request.
Request for information on conference venues:
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[2]So we get a list of sponsors:
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[3]Xpath syntax
Let's go back to the created queries and see how they work.
Consider in detail the first request
In this query, I highlighted three parts to demonstrate the capabilities of xpath. (The division into parts is sensible)
First part
.// - recursive descent to zero or more hierarchy levels from the current context. In our case, the current context is the document root.
The second part of
* - any item
[@ id = 'w3c_home_upcoming_events'] is a predicate based on which we search for a node that has the id attribute equal to 'w3c_home_upcoming_events'. XHTML element identifiers must be unique. Therefore, the query “any item with a specific ID” must return the only node we are looking for.
We can replace * with the exact name of the div node in this query.
div[@id='w3c_home_upcoming_events']Thus, we descend through the document tree to the node we need div [@ id = 'w3c_home_upcoming_events']. We absolutely do not care what nodes the DOM tree consists of and how many levels of hierarchy remain above.
The third part
/ ul / li / div / p / a –xpath path to a specific element. The path consists of the steps of addressing and the condition of checking nodes (ul, li, etc.). Steps are separated by a "/" (slash).
Xpath collections
It is not always possible to access a node of interest using a predicate or addressing steps. Very often at the same level of the hierarchy there are as many nodes of the same type as possible and it is necessary to select “only the first” or “only the second” nodes. For such cases, collections are provided.
The xpath collections allow you to access an item by its index. The indices correspond to the order in which the elements were presented in the original document. The sequence number in the collections is counted from one.
Based on the fact that the “venue” is always the second paragraph after the “conference title”, we get the following request:
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[2]Where p [2] is the second element in the set for each node of the list / ul / li / div.
Similarly, we can get a list of sponsors by asking:
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[3]Some hpath functions
In XPath there are many functions for working with items within the collection. I will give only some of them.
last ():
Returns the last item in the collection.
Query
ul/li/div/p[last()] - returns the last paragraphs for each node of the list "ul".The first () function is not provided. To access the first element, use the index "1".
text ():
Returns the test content of the item.
.//a[text() = 'Archive'] - we get all the links with the text “Archive”.position () and mod:
position () - returns the position of the element in the set.
mod is the remainder of the division.
By combining these functions we can get:
- not even
ul/li[position() mod 2 = 1] elements ul/li[position() mod 2 = 1]- even elements:
ul/li[position() mod 2 = 0]Comparison operations
- <- logical "less"
- > - logical "more"
- <= - logical "less than or equal to"
- > = - logical "greater than or equal to"
ul/li[position() > 2] , ul/li[position() <= 2] - list items starting from the 3rd number and vice versa.Full feature list
On their own
Try to get:
- even URL links from the left menu “Standards”;
- headlines of all news, except the first from the main page of w3c.org.
PHPath in PHP5
$dom = new DomDocument(); $dom->loadHTML( $HTMLCode ); $xpath = new DomXPath( $dom ); $_res = $xpath->query(".//*[@id='w3c_home_upcoming_events']/ul/li/div/p/a"); foreach( $_res => $obj ) { echo 'URL: '.$obj->getAttribute('href'); echo $obj->nodeValue; } Finally
In a simple example, we saw the capabilities of xpath for accessing web page nodes.
Xpath is an industry standard for accessing xml and xhtml elements, xslt transformations.
You can use it to parse any html page. If the source html-code contains significant errors in the markup, pass it through tidy . Errors will be corrected.
Try to abandon regular expressions when parsing web pages in favor of xpath.
This will make your code easier, more understandable. You will make fewer mistakes. Reduce debugging time.
Resources
Firepath add-on Mozzilla Firefox
Brief annotation of the language in Wikipedia
A good xpath reference. Do not pay attention to the fact that it is for the .NET Framework. Xpath works the same in all environments, except for a couple of specific functions.
Xpath 1.0 specification
Specification xpath 1.0 in Russian
XQuery 1.0 and XPath 2.0
Tidy
PHP5 tidy :: repairFile
Source: https://habr.com/ru/post/114772/
All Articles