Text analyzer: recognition of authorship (start)

Good afternoon, dear habrazhiteli. I have long wanted to publish my “Text Analyzer” ( [1] ) under the GPL-license. Finally, got his hands. The “text analyzer” is a research project that I developed for three years in the 3rd, 4th and 5th year of university courses. The main goal was to create a text recognition algorithm using Hamming or Hopfield neural networks. The idea was this: these neural systems recognize patterns, and the task of pattern recognition can be reduced to the task of identifying authorship. For this it is necessary to collect statistics for each text, and the more different criteria, the better: frequency analysis of letters, analysis of word / sentence / paragraph lengths, frequency analysis of two-letter combinations, and so on. The neural system could reveal the characteristics of which texts are most similar. Work was - shaft. A lot of code, cunning algorithms, OOP, design patterns. In addition to the main task, I also implemented another know-how: “Euphony map”. As planned, this map should show all the bad and well-sounding places, highlighting them in color. The criteria for evaluating euphony should be set in some universal way, for example, by rules. For this purpose, I even developed a special graphical language, RRL (Resounding Rules Language). Work was - shaft. A lot of code, cunning algorithms, OOP, design patterns. The result was a large and complex program, albeit with an ugly interface. With this project, I even won the thesis contest, got 1 and 3 places at university conferences, as well as 2nd place at the international scientific and practical.
More than two years have passed, and I hardly remember how it works. Let's try together to find out what is under the
(The article has a sequel and ending .)
')
Article structure:
- Authorship analysis
- Introducing the code
- TAuthoringAnalyser internals and text storage
- Leveling by state machine on strategies
- Collection of frequency characteristics
- Hamming neural network and authorship analysis
Additional materials:
- Sources of the Text Analyzer Project (Borland C ++ Builder 6.0)
- Testing the Hamming Neural System in Excel ( [xls] )
- Conversion table for the spacecraft splitting the text into levels ( [xls] )
- Calculation of the sound of individual letters ( [xls] )
- Presentation of the graduation project "Text Analyzer" ( [ppt] )
- Presentation of the “Euphony Card” project ( [ppt] )
- All these materials are compressed ( [zip] , [7z] , [rar] )
1. Analysis of authorship
Need to:
- Download sample texts and “key” text (unknown authorship);
- identify comparable sample texts:
- break texts into words, sentences, paragraphs,
- make blocks of the same length from words, sentences, paragraphs for each text,
- select only comparable blocks of the same size for the levels “words”, “sentences”, “paragraphs”;
- collect statistics on these three levels;
- upload data to the Hamming neurosystem;
- conduct image recognition with its help;
- identify sample texts on all three levels that are closest to the key text in terms of characteristics. Probably, the authors of these texts belong to the key text.
Here are some conclusions to draw from the plan:
- There will be work with large amounts of data, up to megabytes - depending on the texts.
- Texts can be quite different sizes: from stories to multivolume novels. Therefore, it is necessary to somehow ensure the basic comparability of different works.
- Paragraph 2 is needed to improve recognition accuracy, to differentiate the process by levels and to ensure basic comparability of texts.
- Parsing words, sentences, and paragraphs is a task for a finite state machine.
- There may be a lot of statistics, I would like them to be assembled in a universal way, so that you can always add some more collection algorithms.
- The Hamming neurosystem works only with certain information, which means that it is necessary to convert the collected data into a form that it understands.
2. Familiarity with the code
To “warm up”, we first consider the main form class - TAuthoringAnalyserTable ( [cpp] , [h] ). (If the “warm-up” is not needed, you can go directly to the next section.) The form itself is terrible, usability, one might say, at zero. But we are interested in the code, not the button-shaped.
At the beginning of the cpp-file we see instantiated classes:
Copy Source | Copy HTML TVCLControllersFasade VCLFasade; // 1 - VCL TAnalyserControllersFasade AnalyserFasade; // 2 - TVCLViewsContainer ViewsContainer; // 3 -
Copy Source | Copy HTML TVCLControllersFasade VCLFasade; // 1 - VCL TAnalyserControllersFasade AnalyserFasade; // 2 - TVCLViewsContainer ViewsContainer; // 3 -Copy Source | Copy HTML TVCLControllersFasade VCLFasade; // 1 - VCL TAnalyserControllersFasade AnalyserFasade; // 2 - TVCLViewsContainer ViewsContainer; // 3 -Copy Source | Copy HTML TVCLControllersFasade VCLFasade; // 1 - VCL TAnalyserControllersFasade AnalyserFasade; // 2 - TVCLViewsContainer ViewsContainer; // 3 -
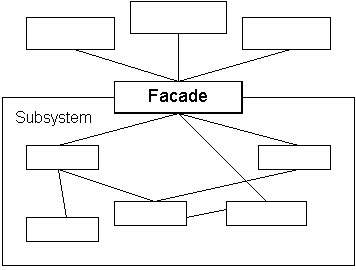
Here, the pattern “Facade” is applied to (1) and (2) (Facade, [1] , [2] , [3] , [4] ). Inside the facade class (1) there is a large interface for working with visual components of the VCL. It is there that the reactions to pressing the buttons “Load text” are written, to update the list of texts, and in general to any event from the form. The form accesses these functions, not knowing what will happen. The facade hides all unnecessary from the form. But, in fact, VCLFasade ( [cpp] , [h] ) only links the events from the forms and algorithms; it does not have these algorithms, but they lie somewhere further in another facade - (2), AnalyzerFasade ( [cpp] , [h] ). Class (1) just redirects calls to object (2) and does additional work, such as filling in the “List” visual component. Yes, such a monstrous construction: the object (1) knows about the object (2) and its functions. How does he know? In the constructor of the main form, just below, there is a parametrization of the first facade by the second:
Copy Source | Copy HTML
- // .......
- VCLFasade. SetAnalyserControllersFasade (& AnalyzerFasade); // Parameterization of one object by another.
- // .......
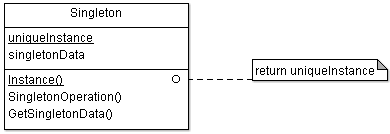
Now I am no longer sure that class (1) is “Facade”, perhaps it is something else, or just like that. It would be nice to place the facades in the “Singleton” pattern (Singleton, [1] , [2] , [3] , [4] ). Unfortunately, two years ago I did not think of it. Not that the program has suffered, no, everything works as it should work. But we lose some of the opportunities associated with the Loner Pattern. After all, we can not create multiple entry points into one subsystem? Can not. It would be worth banning it.
What else is interesting in the designer of the main form?
Copy Source | Copy HTML
- // .......
- VCLFasade. SetViewsContainer (& ViewsContainer); // The view container is passed to the facade (1).
- VCLFasade.SetAuthoringAnalyserTable ( this ); // and pointer to the main form.
- / * Note: It can be concluded that somewhere there are cyclic inclusions of h-files and, <br/> perhaps, predestination. Of course, this is bad, but so it happened then. * /
- // Parameterization of the facade (2) reporting system:
- AnalyzerFasade.SetAuthoringAnalysisReporter (& AnalysisReporter);
- AnalyzerFasade.SetResoundingAnalysisReporter (& AnalysisReporter);
- // .......
And then - a large sheet for filling the container of visual components (controls). An element (for example, a button) is taken from a form and entered into a container, and in its own group:
Copy Source | Copy HTML
- // .......
- TVCLViewsContainer * vc = & ViewsContainer; // To abbreviate the name.
- vc-> AddViewsGroup (cCurrentTextInfo); // Create a group of components, cCurrentTextInfo - the text name of the group.
- vc-> AddView (cCurrentTextInfo, LCurrentTextNumber); // LCurrentTextNumber, LCurrentTextAuthor,
- vc-> AddView (cCurrentTextInfo, LCurrentTextAuthor); // LCurrentTextTitle, etc. are pointers to visual components.
- vc-> AddView (cCurrentTextInfo, LCurrentTextTitle); // For example: TLabel * LCurrentTextNumber;
- vc-> AddView (cCurrentTextInfo, CLBTextsListBox);
- vc-> AddView (cCurrentTextInfo, MSelectedTextPreview);
- vc-> AddViewsGroup (cKeyTextInfo); // Create another group.
- vc-> AddView (cKeyTextInfo, LKeyTextNumber);
- vc-> AddView (cKeyTextInfo, LKeyTextAuthor);
- vc-> AddView (cKeyTextInfo, LKeyTextTitle);
- vc-> AddView (cKeyTextInfo, CLBTextsListBox);
- // ...and so on...
A rather curious approach, although not very clear. Controls are transferred to the container (3), which in turn is transferred to the facade (1). There, obviously, controls are somehow used. After reviewing the TVCLViewsContainer ( [cpp] , [h] ) and TVCLView ( [h] ) classes, it becomes clear that everything that is done with controls is Update, Show / Hide, Enable / Disable, and in groups. You can completely update one group, hide another, knowing only the name ... For what it was needed, now I can only guess. This approach breaks encapsulation, since you can do anything with controls, even deletion. They are put out of the brackets of their form than risk being modified.
There is nothing interesting in the class of the main form, so let's take a closer look at the class (2) ( [cpp] , [h] ). This second facade is already real, no joke, except that the name is written in S, not C (Facade is the correct spelling of the word, as it is given everywhere, including in GOF ( [1] , [2] , [3 ] )). The class simplifies working with analysis subsystems by hiding the real classes behind the interfaces. And there are three real classes:
Copy Source | Copy HTML
- class TAnalyserControllersFasade
- {
- TTextsController _TextsController;
- TAuthoringAnalyser _AuthoringAnalyser;
- TResoundingMapAnalyser _ResoundingAnalyser;
- // .......

The simple functions of the TAnalyserControllersFasade class address the more complex functions of the three real classes, but the client does not know anything about this complexity. It simplifies development and use. Load texts (LoadAsPrototype (), LoadAsKeyText () functions), load analyzer settings (LoadResoundingAnalysisRules ()), run the analysis (DoAnalysis () function), and it works in some magic way somewhere there. If we take a closer look at the DoAnalysis () function, we will see that the necessary analysis is invoked by textual name. It's good. The bad thing is that paired with the facade is not a very extensible solution. If I wanted to carry out some other analysis, such as a grammar check, I would need to add a fourth real class — GrammarAnalyser — and register some additional functions in the facade. And if I write a super-universal text analysis tool, and I have such analyzers - darkness? Then we would have to invent uniform interfaces, raise an abstraction over analyzers, make algorithms that are changeable at run-time ... It would turn out very ... very much. Fortunately, I suffer a little less mania of gigantism, and it was not required at that time.
3. Insides TAuthoringAnalyser and storing texts
Let's look at the class TAuthoringAnalyser ( [cpp] , [h] ) - a real class that makes a real analysis of authorship. Already at the very beginning of the h-file monstrous typedef's are evident:
Copy Source | Copy HTML
- class TAuthoringAnalyser : public TAnalyser
- {
- public :
- typedef map < TTextString , ParSentWordFSM :: TCFCustomUnitDivisionTreeItem, less < TTextString >> TTextsParSentWordTrees;
- typedef map < TUInt , TRangeMapsEqualifer :: TEqualifiedMapsContainer, less < TUInt >> TLeveledEqualifiedMaps;
- typedef map < TUInt , TFrequencyTablesContainer , less < TUInt >> TLeveledFrequencyContainers;
- typedef map < TUInt , TTextString , less < TUInt >> TIndexToAliasAssociator ;
- typedef map < TUInt , TIndexToAliasAssociator , less < TUInt >> TLeveledIndexToAliasAssociators;
- // <Unsafe code> // Note: why this code is not safe, it’s unlikely to be remembered ...
- typedef map < TUInt , TResultVector , less < TUInt >> TLeveledResultVectors;
- // </ Unsafe code>
- // .......

These types are needed to store all intermediate data, calculations, results. Thus, TTextsParSentWordTrees contains, obviously, structural text trees: “All text -> paragraphs -> sentences -> words”; TLeveledFrequencyContainers contains the frequency characteristics of texts distributed over levels, and so on. You may also notice that all built-in types ( [h] ) are overridden. TUInt == unsigned int, TTextString == AnsiString. It is hard to imagine when it could be useful. Redefined types, of course, can be changed in a flash without making changes to the project files, but how often do such situations occur? When it suddenly turns out that the 32-bit integer is missing? When suddenly AnsiString stopped satisfying us, and we wanted std :: string? Too hypothetical situation, and happens primarily with a poorly designed program. Anyway, the types are redefined, they don’t really hinder, they don’t help much, and you have to get used to it.
Slightly lower in the protected section of our facade analyzer, objects of these and other types are declared:
Copy Source | Copy HTML
- // .......
- private :
- TTextsConfigurator * _AllTextsConfigurator;
- TTextsConfigurator _AnalysedTextsConfigurator;
- TTextsParSentWordTrees _Trees;
- TLeveledEqualifiedMaps _LeveledEqualifiedMaps;
- TLeveledFrequencyContainers _FrequencyContainers;
- TLeveledIndexToAliasAssociators _IndexToAliasAssociators;
- // .......
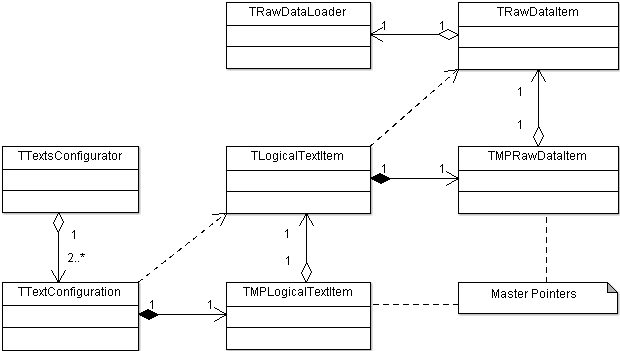
The TTextsConfigurator class has a complex structure. Its task is to download, store and provide texts - without deep copying. A program would be good if texts, being transmitted in parameters, were completely copied. Then there would be no memory, no processor time. Therefore, TTextsConfigurator provides access via pointers. It is believed that once downloaded, the text is always available. The “Text Configurator” also stores additional information: is the text a sample or is it key; whether the text is activated or not (in the program you can exclude texts from analyzes), who is the author, what is the name, etc. How this is implemented can be viewed in the classes TTextsConfigurator ( [cpp] , [h] ), TTextConfiguration ( [cpp] , [h] ) and TTextDataProvider ( [cpp] , [h] ). It is in this order that the objects of these classes are invested in each other, and we get a kind of matryoshka. The idea was to separate the logical and physical representation of the text, as well as to provide the ability to download raw data from different sources, without knowing anything about the sources or the format in which the text is stored. Therefore, the loader "raw data" can be changed. Among other things, it uses the “Smart Pointer” pattern (TMPRawDataItem and TMPLogicalTextItem classes) in its “Master Pointer” feature ( [1] , [2] ). There is also a hierarchy of classes that allows you to abstract from the physical representation of texts. All this hardly suited me; Perhaps I did extra work, but I gained a lot of experience and positive emotions.
Source: https://habr.com/ru/post/114186/
All Articles