Fulview Or Fulview Notes: About the Benefits and Harm of the Complete BGP Table
On any near-net forum, it is easy to find with a dozen branches about the choice of equipment for BGP peering with the ability to “keep two, three, five, twenty-five full views”. Most of these branches are poured into holivars on Cisco vs. Juniper or something worse. Offline, their development often resembles a cartoon of six caps from one ovichichiny. In general, it is funny.
And it is extremely rare to discuss the need for this very fullview.
Do not worry, I will not tell everything from the beginning. I am sure that the majority of readers are well aware of the contents of my theoretical introduction. Those who wish can safely skip it. However, I regularly encounter some uncertainty about people who are fully competent in practical matters when it comes to the following. So still, let's synchronize the terms a little bit before discussing the materiel.
')
Anything that does not directly concern the topic of the Internet BGP table, in particular IGP, MPLS, VRF / VPN, etc., is left behind the brackets.
Fulview is practically the Yellow Pages directory for the entire Internet. Only “Yellow Pages”, and not your personal notebook. The principal difference here is that, in addition to the resolution of the letters in the numbers, for which the Internet does not serve full-view, but the DNS-periodic directories give us the opportunity to know about the appearance and disappearance of objects. We need to somehow find out that one or another address is generally on the Internet. Moreover, if suddenly it is available to us only through link A, and through B is unavailable - we also want to know about it. This is the reachability signaling. Let's not get too deep into going into abstraction, just note the importance of being aware that ricability and routing are different things.
Routing (routing) - finding the best way to transfer traffic for a given direction. This process is a little like searching in the telephone directory, but rather related to the city map: if the same xxxx address is available to us through link A and link B, you need to decide where to send the packets.
Suppose that the reader is familiar with the IP protocol and is aware of what the prefix is, why it is long, and what the longest match rule is about .
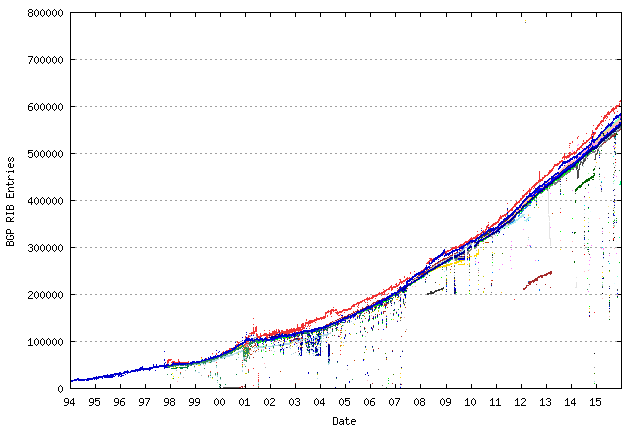
So, as can be seen from the famous graph shown above with bgp.potaroo.net , the complete Internet routing table (hereinafter, this is mainly about IPv4, although almost everything except numbers is also true for IPv6) now contains almost 350 thousand entries. This number is growing exponentially and fairly quickly. Each of the entries is, in fact, a route: the destination IP prefix (a subnet with a mask), a nextop (the next node aka "where to send"), and there are various other parameters that determine the value of this route. When there are two (received from different routers-neighbors) route for one prefix, these attributes are used. They determine which nextop will be used for transmission.
Example:
Here are three routes to the 8.8.8.0/24 prefix received from three different neighbor routers. For some reason — by the way, in this case non-trivial — the first of them was chosen the best (in the example the reason is not shown). Do not be confused by the fact that all three routes have the same nextop: the data is taken from a very specific router that does not send transit traffic. And yes, the router-neighbor and nextop are not the same thing.
Routes between routers are advertised using the BGP protocol, which is, well, almost RSS broadcasting (may theorists forgive me for blasphemous comparison). Actually, the term Full View is popular mainly here, foreign colleagues often say Full BGP, Full Table or Full Feed.
That is, the protocol itself is nothing complicated - just a way of automated data exchange wrapped in the best programming traditions in something like containers, which the protocol standard allows for more or less flexibility to expand as needed. The mechanisms for finding the best path (routing) and controlling connectivity (ricability) are fairly simple, if not to say primitive. In particular, BGP believes that traffic is not transmitted between routers, but between enlarged entities: autonomous systems (AS, pronounced "a-es") and knows almost nothing about their internal structure - the path through two transit speakers, each of which includes say, ten internal hops (routers), BGP considers it more profitable than going through five speakers, each of which has two hop inside. In addition, BGP knows almost nothing about link throughput; in our approximation, we can assume that this aspect is not at all taken into account when choosing a route.
Compared to other protocols, it is not too fast in detecting changes in connectivity and, as we have just seen, is not always optimally looking for the best paths. However, this is all - not only a minus, but also a plus of BGP, since it is precisely because of its relative straightness and the “enlargement of smears” that the protocol is well adapted to transmit a large amount of routing information.
So, a table of 340 thousand records with a bunch of attributes is quite a lot. But such tables usually need at least two ("Menshe ne was by the time of islam", but more on that later). Just storing all this stuff requires many hundreds of megabytes of memory, and in addition to transferring and keeping in memory, the tables need to be “cheated”, resulting in a set of the best (active) routes.
For example. One router-neighbor announced to us that he knows the route to, say, Google, and another neighbor also announced it. Now we know that Google is available to us through each of its neighbors (richness) and we want to decide which of the two routes to use for packet transmission (routing). To do this, BGP compares the readings (different attributes of the routes: Local Preference, AS-PATH, and others) and makes a decision (according to some criteria that do not have any value now), which, let's say, is better through the first neighbor. And so for each prefix. Thus, from several tables (each of which consists of 340 thousand records) received from different neighbors, one table is compiled for 340 thousand active routes:
Or the same plus IPv6 on Juniper:
The construction of several still uncompliant BGP feeds (to be more precise, not only them, but also data from other protocols) is called RIB (routing information base). It is usually stored in the most ordinary RAM and is processed by the most ordinary processor. Accordingly, it is precisely these two elements that are required when it comes to the number of full BGP tables that can be crammed into the RIB. The total number of records here is defined as the sum of all routes received from neighbors: two full views — almost 700 thousand prefixes, three for one million, etc.
Memory under RIB with several fullviews is necessary not so much that a lot, but hundreds of megabytes - units of gigabytes (depending on the number of full views, implementation, and many other aspects). Sometimes the processor also doesn’t have to be very sweet, especially in implementations that have a BGP scanner . For example, an updown of a session through which a complete table is transmitted, on other platforms, can lead to a 100% processor load somewhere for half an hour.
However, it is clear that gigabytes of memory and gigahertz processor frequency have long ceased to be something special. And even in the context of network equipment, manufacturers of which are famous for the ability to sell conventional, like a computer, DRAM at the price of spacecraft, pretending that 2 GB is the pinnacle of progress, the figures are not that scary looking. Participants mentioned at the beginning of the topic forum discussions quite often come to precisely this conclusion. Like, the main memory more. This statement, in general, is true, but unfortunately it does not end there.
Let's see what happens with fullview further. But before one more small, but very important remark.
Then this “compiled” table of active routes is used to transmit traffic. It is called FIB (forwarding information base), and the number of entries in it, roughly speaking, is equal to the number of entries in one fullview (340 thousand). Everything is much more interesting with her.
Most modern routers capable of transmitting traffic at speeds from a couple of gigabits per second or higher are “hardware”. Their hardware is that the FIB and its attributes are placed not in the usual, but in a special, roughly speaking, “fast” switching memory (SRAM, TCAM, RLDRAM, etc.), which is addressed by special packet processing processors. This memory - perhaps the most expensive resource in the router. And the possible sophistication of working with it is certainly the most important factor influencing the price of iron.
For example, a switch to 24 gigabit ports, capable of transmitting traffic with terrible force (at the same time at the full speed of all interfaces), now costs a couple of thousand dollars or even cheaper. It is also quite “hardware”, and most likely the processor power and the amount of RAM in it are enough to easily thresh four full views in the RIB. Moreover, often the software in it supports many different complex features. However, a “full-fledged router,” capable of doing what seems to be the same, costs fifteen times more. This is because, in addition to all sorts of marketing subtleties at the switch, you can put10-15 thousand routes into the switching table, and the set of available actions with this table is significantly narrower. For example, if for each packet you need to search for an entry in the FIB more than once, but two or three (this is needed more often than you think), then the switches for $ 2,000 cannot do this.
There are also software boxes (performance, roughly speaking, up to gigabit-two), in which, respectively, FIB, like RIB, is stored in a regular RAM. They, in general, often have too much of it stored, but about this some other time - the main thing is that it (the RAM) is not rubber. Moreover, programmatic search by array with finding the best match (longest match) - well, obviously, the slower the more in the array of elements, the algorithm does not look for.
Now we have to answer the question in the heading about the benefits and harms of fullview. To do this, first a little more philosophical.
In the dynamic transfer of routes, there are two opposing principles (the word “principle” here means not “persuasion” or “inclination”, but rather a technical technique used for its intended purpose) for working with route information: detailing and aggregation. That is, either the detail: many long prefixes, or brevity: the representation of several long prefixes in the form of one shorter.
Generally speaking, it is already clear that there is a lot of harm from detailing: every schoolchild knows that the more information, the harder it is to store it and the more expensive it is to operate. At the time of software routers and youth, IP thesis about the need to minimize the number of routes was an axiom that could not be discussed. In order to combat the decline in performance from the swelling of RIB and FIB, a lot of interesting things were invented. For example, countless and merciless types of arias and LSA in OSPF or such a thing as MPLS (yes, it’s not for the sake of VPN or TE was invented), Cisco Express Forwarding and other things of different usefulness, including hardware forwarding itself.
Aggregation (summation) is a whole little science connected with competent segmentation, choice of address plan, ability to manage all sorts of IGP-arias, manual dexterity when writing routing rules, etc. For example, I refer to the book “Principles of designing corporate IP networks” A. Retany, D. Slice and R. White (Cisco Press).
The extreme case of aggregation is the default route (“default”): 0.0.0.0/0, meaning “everything, besides that, there are obvious routes”.
Unfortunately, the Internet is such a thing, to which all this brilliant art of aggregation is poorly applicable. Principles of independence from geography, lack of centralized management, administrative isolation of autonomous systems, minimization of damage area in case of failures, etc., result in neighboring prefixes, for example 212.90.0.0/19 and 212.90.32.0/19, unless belong to the same autonomous system (and here, too, it is far from always possible), it can not be represented as an aggregated prefix 212.90.0.0/18 with general parameters. In the general case, such a summation can lead to the appearance of hooks or “black holes”.
However, italics “in the general case” is not without purpose. The obvious exception is the aforementioned default route. Actually, it is used as a route to the Internet (and not only) in cases when we do not have any fullview. That is, it is practically the only possible alternative to fullview: in general, to spit on the entire internal structure of the Internet. Let's take a look at when this is possible, and what is the difference between the default-based and full table fording.
With default everything is clear: everything for which there are no specific (own) routes, a helmet to the provider (uplink) aka on the Internet. And what, in essence, gives us here a fullview? It gives you the opportunity to make decisions about choosing a link for poslyki package, based on the knowledge not about the Internet as a whole, but about its individual resources. First of all, an example: the xxxx / x route is accessible via links A and B, and the yyyy / y route is available only via link B. If so, then traffic to yyyy / y can only be sent via B (richnessability). Secondly, we will be able to influence the correspondence between destination prefixes and neighbors through which we will send traffic. Google will send traffic through provider A, and Yandex through B (routing).
Why it may be necessary?
The first, indisputable case is the presence of both upstream or equal (uplink, IX) and downstream (clients) AC-neighbors. That is, when our autonomous system is transit, and clients are connected to it, who also announce something to us. It is impossible to use a default here by definition, since we are in such a case not on the outskirts, but in the “middle” of the Internet. The presence of aggregation of routes here can lead to hooks. Therefore, providers have to keep a complete table on all routers that transmit Internet traffic based on IP headers. We’ll make a reservation that the options “the need for invention are cunning” are also possible here, but firstly, their discussion goes beyond the topic, and secondly, they are rather difficult to operate with industrial network mastabs. Therefore, although variations on this topic are not so rare in life, very often their use in provider autonomy introduces more problems than good.
The next, more interesting task for us is to balance the load in such a way that traffic via the Internet is either optimal from the point of view of BGP (which, as we found out, is not always accurate in the choice ) in the ways that we want (and will configure) . Both desires can be quite legitimate if you really have a lot of outgoing (once again outgoing! ) Traffic from your AU (gigabit or more), and there is an economic expediency in complex manipulations. As a rule, this happens either with providers with transit autonomous systems, which still fall under the case described above, or with large data centers, which, by the way, are also likely to have customers with their own speakers. And even if not, even here individual knowledge of the routes for each prefix (which gives fullview) does not interfere (see, for example, the user of the shapa about his “war” with Golden).
If your speaker system is not a transit infrastructure for sale, but a corporate network, even with its small (by world standards) data center, you most likely have very little outgoing traffic (tens to hundreds of megabits), and tasks like sending traffic to Google by one route, and Yandex to others - you almost certainly do not have (if only for the sake of curiosity). The maximum you need for outgoing traffic here is to balance it either evenly or in some necessary proportion between several Internet links. Contrary to popular belief, fullview is not needed for this and is even harmful - see below.
The third is a slightly more interesting and relatively unobvious case - fullview, as an informational “help”. You often want to know with which speakers you have the most intensive traffic exchange. In some cases, including when full traffic is not needed to transmit traffic, I want to take statistics to evaluate various kinds of traffic trends.. In these cases, fullview is used by mechanisms like NetFlow to obtain additional information about traffic (outbound and inbound). But it should be noted that the implementation of such monitoring requires some experience and understanding of what the equipment should be able to do, where that full view should be stored, what it is fraught with, and how to correctly interpret the statistics obtained. In short, this is an advance topic that goes beyond the topic. In addition, if your traffic is not gigabit, then most likely you do not need it. Another option on this topic is the console output shown above, taken from special routers that do not send transit traffic. They keep fullview only to be able to analyze it.
A common misconception is the opinion that if you have your own speaker and address block, then you must take the full table. This is exactly what a delusion.
As mentioned above, the most dubious case (it’s also the most massive and richest in non-brilliant implementations) is the corporate network, which the speaker needs to own its block of addresses, so that, in turn, it does not depend on the providers when reserving the Internet resources (public servers, VPN hubs, etc.). The main task here is to make it possible to receive incomingfrom the Internet traffic when one of the external connections is lost. We recall the rule stating that traffic is transmitted towards routing information. Question: why do we need fullview, if we are talking about incoming traffic? Answer: Yes, why not need it.
Well, but if we refuse fullview, then how are we going to send outgoing traffic? Yes, as usual! We write the routing rule, and even better agree with the provider (usually this is not a problem), so as not to force the equipment on trifles (and in the ideal case, the ORF mechanism is invented for this), and accept only the default route from each provider. Then either we use only one of the routes, and the second is kept as a reserve (in case the first one falls off) and we allow all outgoing traffic via one link, or we set up load balancing: uniform or even in the given proportion using the BGP bandwidth community, if your equipment it can do this (remember the conversation about the difference between routers and L3 switches). All the same, if there are not two providers, but three, five, twenty, one hundred and twenty.
Some (in general, the only) disadvantage of this approach is that, together with the “granular” routing, we also gave up control over ricability: you will not have signaling connectivity with specific resources on the Internet. Separate fullview prefixes are information directly from the resource to which you need to send traffic. And the default is most often generated by your provider (well, or your provider’s ISP, which is better), and it may happen that you receive a default from the provider, but in fact there is no Internet connection with it (the provider). Here you have the illustration of the "black hole" as a consequence of the aggregation of routes.
First of all, this is still not a very big risk: in any case, the security level of your providers' infrastructure should be much higher than yours. If the described situation occurs often, then this is a reason to think about changing the provider. Secondly, with two Internet links and a “main-reserve” scheme (I’ll remind you that we’re talking only about outgoing traffic), you can additionally make sure: well, for example, get a couple of Google and Yandex-like prefixes from the main provider and write an aggregate rule default only if specified routes are normal.
Are you afraid that Vkontakte will be available only through one provider, and Odnoklassniki only through another? Such a challenge for you business critic? Scary, and want to defend? Want to talk about it with a guide? Does it think so too and is ready to spend money? - Congratulations (first of all your equipment supplier). Not?- well, for you just below will be the final paragraph.
In cases where you need connectivity not with an abstract Internet, but with specific resources, the addresses of which (usually tens to hundreds) are known, for example, when it comes to terminating static tunnels for VPN with branches, you can (and even need) in addition to default, also take routes from these providers to these resources (remote points). The ORF would be especially relevant here, but somehow it is not very popular.
And why, in fact, not fullview? Why soared with all this reasoning? Well, we take it ourselves, and all the cases?
Firstly, balancing outgoing traffic in the right proportion when you have a full view in your hands, it is many times more difficult and dreary (a completely uninteresting occupation). By default, balancing works on the principle of how the card will fall. Let's say you rent a wide channel from an ISP easier and cheaper and a lower channel from an ISP is cooler and more expensive. So, if you do not take special measures, most of the outgoing traffic will get into a narrow channel and (possibly) overload it: connectivity from the “cool” provider is better, and BGP, which knows nothing about the bandwidth of your links, will think that most of the internet is “closer” to you through a narrow channel. Although from the point of view of user experience, it’s probably all the same what route to send traffic to, the main thing is that there is no overload. Having the same two defaults without fullview and the correct router,it is possible to indicate the proportion explicitly at all: at least 30% are sent to the channel even more, 70% to the channel wider.
Secondly for economic reasons: a corporate network with a full-fledged large hardware router is often not affordable. Therefore, if you need high performance (gigabits), you can use those relatively cheap switches that can hold only a few thousand prefixes in the FIB.
However, often in corporate networks for BGP-peering is used less productive, but much more multifunctional software boxes. And usually the same box is at the same time a border router, border state-firewall, does nat, all internal routing, and sometimes, God forgive me, checks traffic for viruses, filters URLs, washes dishes, cooks porridge, erases, strokes and nurses children . And all this stuff is kept in her RAM, which, as I have already noted, is still not rubber, and is processed by a common processor, which is also not a workhorse. There are also several feeds with fullview in such a box - somehow nothing. Yes, do not just do it!
In fact, fullview has one important and often decisive advantage, which I still bashfully kept silent about. Many people think it's cool. It's one thing when show route summary shows 7 routes, and quite another when 700 thousand. What corporate network does not dream of becoming a camera?
The answers are as follows (choose which one you like more):
And it is extremely rare to discuss the need for this very fullview.
A bit of "theory"
Do not worry, I will not tell everything from the beginning. I am sure that the majority of readers are well aware of the contents of my theoretical introduction. Those who wish can safely skip it. However, I regularly encounter some uncertainty about people who are fully competent in practical matters when it comes to the following. So still, let's synchronize the terms a little bit before discussing the materiel.
')
Anything that does not directly concern the topic of the Internet BGP table, in particular IGP, MPLS, VRF / VPN, etc., is left behind the brackets.
Routing and reachability
Fulview is practically the Yellow Pages directory for the entire Internet. Only “Yellow Pages”, and not your personal notebook. The principal difference here is that, in addition to the resolution of the letters in the numbers, for which the Internet does not serve full-view, but the DNS-periodic directories give us the opportunity to know about the appearance and disappearance of objects. We need to somehow find out that one or another address is generally on the Internet. Moreover, if suddenly it is available to us only through link A, and through B is unavailable - we also want to know about it. This is the reachability signaling. Let's not get too deep into going into abstraction, just note the importance of being aware that ricability and routing are different things.
Routing (routing) - finding the best way to transfer traffic for a given direction. This process is a little like searching in the telephone directory, but rather related to the city map: if the same xxxx address is available to us through link A and link B, you need to decide where to send the packets.
Suppose that the reader is familiar with the IP protocol and is aware of what the prefix is, why it is long, and what the longest match rule is about .
So, as can be seen from the famous graph shown above with bgp.potaroo.net , the complete Internet routing table (hereinafter, this is mainly about IPv4, although almost everything except numbers is also true for IPv6) now contains almost 350 thousand entries. This number is growing exponentially and fairly quickly. Each of the entries is, in fact, a route: the destination IP prefix (a subnet with a mask), a nextop (the next node aka "where to send"), and there are various other parameters that determine the value of this route. When there are two (received from different routers-neighbors) route for one prefix, these attributes are used. They determine which nextop will be used for transmission.
Example:
rviews@route-server.as8218.eu> show route 8.8.8.8 inet.0: 343453 destinations, 1643368 routes (343453 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both / * The active (i.e. best in terms of BGP) route is marked with an asterisk, only it is used to transmit traffic * /> 8.8.8.0/24 * [BGP / 170] 6w2d 06:12:47, MED 200, localpref 3200, from 83.167.56.18AS path: 15169 I > to 83.167.56.240 via ge-0/0 / 0.0[BGP / 170] 4w1d 04:00:53, MED 200, localpref 3200, from 83.167.56.6AS path: 15169 I > to 83.167.56.240 via ge-0/0 / 0.0[BGP / 170] 4w2d 04:00:03, MED 200, localpref 3200, from 83.167.56.5AS path: 15169 I > to 83.167.56.240 via ge-0/0 / 0.0 [...]
Here are three routes to the 8.8.8.0/24 prefix received from three different neighbor routers. For some reason — by the way, in this case non-trivial — the first of them was chosen the best (in the example the reason is not shown). Do not be confused by the fact that all three routes have the same nextop: the data is taken from a very specific router that does not send transit traffic. And yes, the router-neighbor and nextop are not the same thing.
Routes between routers are advertised using the BGP protocol, which is, well, almost RSS broadcasting (may theorists forgive me for blasphemous comparison). Actually, the term Full View is popular mainly here, foreign colleagues often say Full BGP, Full Table or Full Feed.
That is, the protocol itself is nothing complicated - just a way of automated data exchange wrapped in the best programming traditions in something like containers, which the protocol standard allows for more or less flexibility to expand as needed. The mechanisms for finding the best path (routing) and controlling connectivity (ricability) are fairly simple, if not to say primitive. In particular, BGP believes that traffic is not transmitted between routers, but between enlarged entities: autonomous systems (AS, pronounced "a-es") and knows almost nothing about their internal structure - the path through two transit speakers, each of which includes say, ten internal hops (routers), BGP considers it more profitable than going through five speakers, each of which has two hop inside. In addition, BGP knows almost nothing about link throughput; in our approximation, we can assume that this aspect is not at all taken into account when choosing a route.
Compared to other protocols, it is not too fast in detecting changes in connectivity and, as we have just seen, is not always optimally looking for the best paths. However, this is all - not only a minus, but also a plus of BGP, since it is precisely because of its relative straightness and the “enlargement of smears” that the protocol is well adapted to transmit a large amount of routing information.
So, a table of 340 thousand records with a bunch of attributes is quite a lot. But such tables usually need at least two ("Menshe ne was by the time of islam", but more on that later). Just storing all this stuff requires many hundreds of megabytes of memory, and in addition to transferring and keeping in memory, the tables need to be “cheated”, resulting in a set of the best (active) routes.
For example. One router-neighbor announced to us that he knows the route to, say, Google, and another neighbor also announced it. Now we know that Google is available to us through each of its neighbors (richness) and we want to decide which of the two routes to use for packet transmission (routing). To do this, BGP compares the readings (different attributes of the routes: Local Preference, AS-PATH, and others) and makes a decision (according to some criteria that do not have any value now), which, let's say, is better through the first neighbor. And so for each prefix. Thus, from several tables (each of which consists of 340 thousand records) received from different neighbors, one table is compiled for 340 thousand active routes:
route-server> show ip bgp summary BGP router identifier 12.0.1.28, local AS number 65000 BGP table version is 22316128, main routing table version 22316128339895 network entries using 41127295 bytes of memory // Active prefixes: 340 thousand 6244036 path entries using 324689872 bytes of memory // Total prefixes: 6.2 million420973/58130 BGP path / bestpath attribute entries using 58936220 bytes of memory 82551 BGP AS-PATH entries using 2164884 bytes of memory 150 BGP community entries using 3600 bytes of memory 0 BGP route-map cache entries using 0 bytes of memory 0 BGP filter-list cache entries using 0 bytes of memory BGP using 426921871 total bytes of memory Dampening enabled. 1728 history paths, 1519 dampened paths BGP activity 3285644/2945748 prefixes, 85118539/78874498 paths, scan interval 60 secs [...]
Or the same plus IPv6 on Juniper:
rviews@route-server.as8218.eu> show route summary Autonomous system number: 8218 Router ID: 83.167.63.120inet.0: 343437 destinations, 1643129 routes (343437 active, 0 holddown, 0 hidden)Direct: 3 routes, 3 active Local: 1 routes, 1 activeBGP: 1642930 routes, 343238 activeStatic: 2 routes, 2 active IS-IS: 193 routes, 193 active [...]inet6.0: 4796 destinations, 20733 routes (4796 active, 0 holddown, 0 hidden)Direct: 4 routes, 4 active Local: 2 routes, 2 activeBGP: 20577 routes, 4640 activeStatic: 1 routes, 1 active IS-IS: 149 routes, 149 active
The construction of several still uncompliant BGP feeds (to be more precise, not only them, but also data from other protocols) is called RIB (routing information base). It is usually stored in the most ordinary RAM and is processed by the most ordinary processor. Accordingly, it is precisely these two elements that are required when it comes to the number of full BGP tables that can be crammed into the RIB. The total number of records here is defined as the sum of all routes received from neighbors: two full views — almost 700 thousand prefixes, three for one million, etc.
The first conclusion. To load a fullview, if you have only one session with the outside world - nonsense. Possession of this array of information will not give anything except the load on the equipment, since the traffic can be transferred only in one way: "Adam, this is Eve, choose your wife." Imagine that Adam would have decided to first analyze 340 thousand parameters of Eve - where would we be now? There are rare exceptions to this rule, but if you don’t know which, then they are definitely not your case.
Memory under RIB with several fullviews is necessary not so much that a lot, but hundreds of megabytes - units of gigabytes (depending on the number of full views, implementation, and many other aspects). Sometimes the processor also doesn’t have to be very sweet, especially in implementations that have a BGP scanner . For example, an updown of a session through which a complete table is transmitted, on other platforms, can lead to a 100% processor load somewhere for half an hour.
However, it is clear that gigabytes of memory and gigahertz processor frequency have long ceased to be something special. And even in the context of network equipment, manufacturers of which are famous for the ability to sell conventional, like a computer, DRAM at the price of spacecraft, pretending that 2 GB is the pinnacle of progress, the figures are not that scary looking. Participants mentioned at the beginning of the topic forum discussions quite often come to precisely this conclusion. Like, the main memory more. This statement, in general, is true, but unfortunately it does not end there.
Let's see what happens with fullview further. But before one more small, but very important remark.
Route information is always transmitted to meet the traffic that commutes on its basis. That is, on the basis of fullview, traffic coming from your AU is transmitted . In spite of all the evidence of this thesis, its practical significance is far from always fully realized.
Forvading
Then this “compiled” table of active routes is used to transmit traffic. It is called FIB (forwarding information base), and the number of entries in it, roughly speaking, is equal to the number of entries in one fullview (340 thousand). Everything is much more interesting with her.
Lyrical digression. Generally speaking, Full View (as opposed to Full BGP Feed) is just a FIB. That is, in most cases it would be more correct to say not “I need a router capable of holding three fullviews”, but “I need a router capable of holding three feasts with fullview”.
And, by the way, the signature on the ordinate axis on the great and terrible picture given at the beginning of the post is incorrect. This is not a RIB, but an FIB. The title on the inside page of this is also hinted at.
Most modern routers capable of transmitting traffic at speeds from a couple of gigabits per second or higher are “hardware”. Their hardware is that the FIB and its attributes are placed not in the usual, but in a special, roughly speaking, “fast” switching memory (SRAM, TCAM, RLDRAM, etc.), which is addressed by special packet processing processors. This memory - perhaps the most expensive resource in the router. And the possible sophistication of working with it is certainly the most important factor influencing the price of iron.
For example, a switch to 24 gigabit ports, capable of transmitting traffic with terrible force (at the same time at the full speed of all interfaces), now costs a couple of thousand dollars or even cheaper. It is also quite “hardware”, and most likely the processor power and the amount of RAM in it are enough to easily thresh four full views in the RIB. Moreover, often the software in it supports many different complex features. However, a “full-fledged router,” capable of doing what seems to be the same, costs fifteen times more. This is because, in addition to all sorts of marketing subtleties at the switch, you can put
There are also software boxes (performance, roughly speaking, up to gigabit-two), in which, respectively, FIB, like RIB, is stored in a regular RAM. They, in general, often have too much of it stored, but about this some other time - the main thing is that it (the RAM) is not rubber. Moreover, programmatic search by array with finding the best match (longest match) - well, obviously, the slower the more in the array of elements, the algorithm does not look for.
The second conclusion. When selecting a hardware router for BGP-peering with fullview, ask the seller about the maximum FIB size. If the seller does not know - reason to think about his competence . Possible options:If the seller can consult you more or less confidently about the size of the RIB - how many peers with fullviews you can keep on the chosen device - this is a sure sign of the seller who knows what he is selling. If he is also able to support the conversation about the difference between large L3 switches from full-fledged routers and is ready to tell you about the possible consequences of using large switches for BGP peering, you are on the right path, it remains to agree with him about the price.
- <500 thousand for IPv4 - it’s better not to take it today. The time is not far off when this will be short. But there is also IPv6.
- ~ 500 thousand - this figure is popular for the so-called. large L3-switches, the ones who have a lot of dope, and a set of switching procedures rather mediocre. Although there are pleasant exceptions. “Large” from “small” switches here differ in the first place by the size of the box and the precedence of the model in the line, secondly and mainly by the size of the switching memory: rarely does the “small”
24-port switch support half a million entries in the FIB. So, although the switching memory of the “big” L3 switches seems to be enough for today's full view, they almost never can do complex stuff with the package (actually, this is their main difference from routers). On the one hand, if you really want to, they can be used for this task, on the other hand, it would be better not to. Very much there are all sorts of nuances. In short, think and torture the seller thoroughly before buying a L3 switch for BGP peering with fullview.- a million and more is a worthy figure.
Practical reasoning
Now we have to answer the question in the heading about the benefits and harms of fullview. To do this, first a little more philosophical.
Aggregation vs. detailing
In the dynamic transfer of routes, there are two opposing principles (the word “principle” here means not “persuasion” or “inclination”, but rather a technical technique used for its intended purpose) for working with route information: detailing and aggregation. That is, either the detail: many long prefixes, or brevity: the representation of several long prefixes in the form of one shorter.
Aggregation
Generally speaking, it is already clear that there is a lot of harm from detailing: every schoolchild knows that the more information, the harder it is to store it and the more expensive it is to operate. At the time of software routers and youth, IP thesis about the need to minimize the number of routes was an axiom that could not be discussed. In order to combat the decline in performance from the swelling of RIB and FIB, a lot of interesting things were invented. For example, countless and merciless types of arias and LSA in OSPF or such a thing as MPLS (yes, it’s not for the sake of VPN or TE was invented), Cisco Express Forwarding and other things of different usefulness, including hardware forwarding itself.
Aggregation (summation) is a whole little science connected with competent segmentation, choice of address plan, ability to manage all sorts of IGP-arias, manual dexterity when writing routing rules, etc. For example, I refer to the book “Principles of designing corporate IP networks” A. Retany, D. Slice and R. White (Cisco Press).
The extreme case of aggregation is the default route (“default”): 0.0.0.0/0, meaning “everything, besides that, there are obvious routes”.
Detailing
Unfortunately, the Internet is such a thing, to which all this brilliant art of aggregation is poorly applicable. Principles of independence from geography, lack of centralized management, administrative isolation of autonomous systems, minimization of damage area in case of failures, etc., result in neighboring prefixes, for example 212.90.0.0/19 and 212.90.32.0/19, unless belong to the same autonomous system (and here, too, it is far from always possible), it can not be represented as an aggregated prefix 212.90.0.0/18 with general parameters. In the general case, such a summation can lead to the appearance of hooks or “black holes”.
However, italics “in the general case” is not without purpose. The obvious exception is the aforementioned default route. Actually, it is used as a route to the Internet (and not only) in cases when we do not have any fullview. That is, it is practically the only possible alternative to fullview: in general, to spit on the entire internal structure of the Internet. Let's take a look at when this is possible, and what is the difference between the default-based and full table fording.
Who and why do we need fullview?
With default everything is clear: everything for which there are no specific (own) routes, a helmet to the provider (uplink) aka on the Internet. And what, in essence, gives us here a fullview? It gives you the opportunity to make decisions about choosing a link for poslyki package, based on the knowledge not about the Internet as a whole, but about its individual resources. First of all, an example: the xxxx / x route is accessible via links A and B, and the yyyy / y route is available only via link B. If so, then traffic to yyyy / y can only be sent via B (richnessability). Secondly, we will be able to influence the correspondence between destination prefixes and neighbors through which we will send traffic. Google will send traffic through provider A, and Yandex through B (routing).
Why it may be necessary?
The first, indisputable case is the presence of both upstream or equal (uplink, IX) and downstream (clients) AC-neighbors. That is, when our autonomous system is transit, and clients are connected to it, who also announce something to us. It is impossible to use a default here by definition, since we are in such a case not on the outskirts, but in the “middle” of the Internet. The presence of aggregation of routes here can lead to hooks. Therefore, providers have to keep a complete table on all routers that transmit Internet traffic based on IP headers. We’ll make a reservation that the options “the need for invention are cunning” are also possible here, but firstly, their discussion goes beyond the topic, and secondly, they are rather difficult to operate with industrial network mastabs. Therefore, although variations on this topic are not so rare in life, very often their use in provider autonomy introduces more problems than good.
Conclusion three. If your speaker system is in transit, then you probably cannot do without fullview. However, you probably yourself know all this. About MPLS and BGP-free core, I think, I heard something too. If not, these are your keywords for further consideration.
The next, more interesting task for us is to balance the load in such a way that traffic via the Internet is either optimal from the point of view of BGP (which, as we found out, is not always accurate in the choice ) in the ways that we want (and will configure) . Both desires can be quite legitimate if you really have a lot of outgoing (once again outgoing! ) Traffic from your AU (gigabit or more), and there is an economic expediency in complex manipulations. As a rule, this happens either with providers with transit autonomous systems, which still fall under the case described above, or with large data centers, which, by the way, are also likely to have customers with their own speakers. And even if not, even here individual knowledge of the routes for each prefix (which gives fullview) does not interfere (see, for example, the user of the shapa about his “war” with Golden).
If your speaker system is not a transit infrastructure for sale, but a corporate network, even with its small (by world standards) data center, you most likely have very little outgoing traffic (tens to hundreds of megabits), and tasks like sending traffic to Google by one route, and Yandex to others - you almost certainly do not have (if only for the sake of curiosity). The maximum you need for outgoing traffic here is to balance it either evenly or in some necessary proportion between several Internet links. Contrary to popular belief, fullview is not needed for this and is even harmful - see below.
The third is a slightly more interesting and relatively unobvious case - fullview, as an informational “help”. You often want to know with which speakers you have the most intensive traffic exchange. In some cases, including when full traffic is not needed to transmit traffic, I want to take statistics to evaluate various kinds of traffic trends.. In these cases, fullview is used by mechanisms like NetFlow to obtain additional information about traffic (outbound and inbound). But it should be noted that the implementation of such monitoring requires some experience and understanding of what the equipment should be able to do, where that full view should be stored, what it is fraught with, and how to correctly interpret the statistics obtained. In short, this is an advance topic that goes beyond the topic. In addition, if your traffic is not gigabit, then most likely you do not need it. Another option on this topic is the console output shown above, taken from special routers that do not send transit traffic. They keep fullview only to be able to analyze it.
When can I do without fullview?
A common misconception is the opinion that if you have your own speaker and address block, then you must take the full table. This is exactly what a delusion.
As mentioned above, the most dubious case (it’s also the most massive and richest in non-brilliant implementations) is the corporate network, which the speaker needs to own its block of addresses, so that, in turn, it does not depend on the providers when reserving the Internet resources (public servers, VPN hubs, etc.). The main task here is to make it possible to receive incomingfrom the Internet traffic when one of the external connections is lost. We recall the rule stating that traffic is transmitted towards routing information. Question: why do we need fullview, if we are talking about incoming traffic? Answer: Yes, why not need it.
Well, but if we refuse fullview, then how are we going to send outgoing traffic? Yes, as usual! We write the routing rule, and even better agree with the provider (usually this is not a problem), so as not to force the equipment on trifles (and in the ideal case, the ORF mechanism is invented for this), and accept only the default route from each provider. Then either we use only one of the routes, and the second is kept as a reserve (in case the first one falls off) and we allow all outgoing traffic via one link, or we set up load balancing: uniform or even in the given proportion using the BGP bandwidth community, if your equipment it can do this (remember the conversation about the difference between routers and L3 switches). All the same, if there are not two providers, but three, five, twenty, one hundred and twenty.
Some (in general, the only) disadvantage of this approach is that, together with the “granular” routing, we also gave up control over ricability: you will not have signaling connectivity with specific resources on the Internet. Separate fullview prefixes are information directly from the resource to which you need to send traffic. And the default is most often generated by your provider (well, or your provider’s ISP, which is better), and it may happen that you receive a default from the provider, but in fact there is no Internet connection with it (the provider). Here you have the illustration of the "black hole" as a consequence of the aggregation of routes.
First of all, this is still not a very big risk: in any case, the security level of your providers' infrastructure should be much higher than yours. If the described situation occurs often, then this is a reason to think about changing the provider. Secondly, with two Internet links and a “main-reserve” scheme (I’ll remind you that we’re talking only about outgoing traffic), you can additionally make sure: well, for example, get a couple of Google and Yandex-like prefixes from the main provider and write an aggregate rule default only if specified routes are normal.
Are you afraid that Vkontakte will be available only through one provider, and Odnoklassniki only through another? Such a challenge for you business critic? Scary, and want to defend? Want to talk about it with a guide? Does it think so too and is ready to spend money? - Congratulations (first of all your equipment supplier). Not?- well, for you just below will be the final paragraph.
In cases where you need connectivity not with an abstract Internet, but with specific resources, the addresses of which (usually tens to hundreds) are known, for example, when it comes to terminating static tunnels for VPN with branches, you can (and even need) in addition to default, also take routes from these providers to these resources (remote points). The ORF would be especially relevant here, but somehow it is not very popular.
Harm from Fulview
And why, in fact, not fullview? Why soared with all this reasoning? Well, we take it ourselves, and all the cases?
Firstly, balancing outgoing traffic in the right proportion when you have a full view in your hands, it is many times more difficult and dreary (a completely uninteresting occupation). By default, balancing works on the principle of how the card will fall. Let's say you rent a wide channel from an ISP easier and cheaper and a lower channel from an ISP is cooler and more expensive. So, if you do not take special measures, most of the outgoing traffic will get into a narrow channel and (possibly) overload it: connectivity from the “cool” provider is better, and BGP, which knows nothing about the bandwidth of your links, will think that most of the internet is “closer” to you through a narrow channel. Although from the point of view of user experience, it’s probably all the same what route to send traffic to, the main thing is that there is no overload. Having the same two defaults without fullview and the correct router,it is possible to indicate the proportion explicitly at all: at least 30% are sent to the channel even more, 70% to the channel wider.
Secondly for economic reasons: a corporate network with a full-fledged large hardware router is often not affordable. Therefore, if you need high performance (gigabits), you can use those relatively cheap switches that can hold only a few thousand prefixes in the FIB.
However, often in corporate networks for BGP-peering is used less productive, but much more multifunctional software boxes. And usually the same box is at the same time a border router, border state-firewall, does nat, all internal routing, and sometimes, God forgive me, checks traffic for viruses, filters URLs, washes dishes, cooks porridge, erases, strokes and nurses children . And all this stuff is kept in her RAM, which, as I have already noted, is still not rubber, and is processed by a common processor, which is also not a workhorse. There are also several feeds with fullview in such a box - somehow nothing. Yes, do not just do it!
Conclusion four. If the autonomous system is not transit (you are not a provider and you do not have clients with your speakers) and you cannot clearly state for yourself why you need a full view, you do not need a full view.
What if you really want?
In fact, fullview has one important and often decisive advantage, which I still bashfully kept silent about. Many people think it's cool. It's one thing when show route summary shows 7 routes, and quite another when 700 thousand. What corporate network does not dream of becoming a camera?
The answers are as follows (choose which one you like more):
- And rightly so, do not deny yourself the pleasure. Vendors and sellers of routers will be very happy with this. I hope that your employer will also support you in this (financially).
- BGP-, : . , () (), , , . .
- , , , route- (, , , ).
Source: https://habr.com/ru/post/113906/
All Articles