Is it practical to use the prefix increment operator ++ it for iterators instead of postfix it ++
I nevertheless decided to figure out if it makes sense when working with iterators to write ++ an iterator, and not an iterator ++. My interest in this issue arose not from the love of art, but from practical considerations. We have long wanted to develop PVS-Studio not only in the direction of searching for errors, but also in the direction of issuing hints on code optimization. Issuing a message that it is better to write ++ iterator is quite appropriate in terms of optimization.
But how relevant is this recommendation in our time? In ancient times, for example, it was advised not to repeat the calculations. It was considered good form instead:
X = A + 10 + B; Y = A + 10 + C;
write like this:
TMP = A + 10; X = TMP + B; Y = TMP + C;
Now such petty manual optimization is meaningless. The compiler will cope with this task as well. Only extra code clutter.
Note for especially pedantic. Yes, it is better not to repeat the calculations and to calculate long expressions that are used several times separately. I say that there is no point in optimizing simple cases like what I have brought.
')
We were distracted. The question on the agenda is whether the advice is not out of date to use the prefix increment for operators instead of postfix increment. Should I clog the head with another subtlety. Perhaps the compiler has long been able to optimize the postfix increment.
At the beginning there is a little theory for those who are not familiar with the topic under discussion. The rest can scroll a little text down.
The prefix increment operator changes the state of the object and returns itself in the already modified form. The prefix increment operator in an iterator class for working with std :: vector might look like this:
_Myt & operator ++ ()
{// preincrement
++ _ Myptr;
return (* this);
} In the case of postfix increment, the situation is more complicated. The state of the object should change, but it will return the previous state. There is an additional temporary object:
_Myt operator ++ (int)
{// postincrement
_Myt _Tmp = * this;
++ * this;
return (_Tmp);
} If we only want to increase the value of the iterator, it turns out that the prefix form is preferred. Therefore, one of the tips for micro-optimization programs is to write “for (it = a.begin (); it! = A.end; ++ it)” instead of “for (it = a.begin (); it! = A .end; it ++) ". In the latter case, an unnecessary temporary object is created, which reduces performance.
In more detail all this can be read in the book by Scott Meyers “The most effective use of C ++. 35 new recommendations for improving your programs and projects ”(Rule 6. Distinguish the prefix form of increment and decrement operators) [1].
The theory is over. Let's go to practice. Does it make sense in the code to replace the postfix increment with the prefix one?
size_t Foo (const std :: vector <size_t> & arr)
{
size_t sum = 0;
std :: vector <size_t> :: const_iterator it;
for (it = arr.begin (); it! = arr.end (); it ++)
sum + = * it;
return sum;
} I understand that you can go into the field of philosophy. Like, then maybe the container will not be a vector, but another class, where iterators are very complex and heavy objects. When copying an iterator, you need to make a new connection to the database, or something like that. Therefore, you should always write ++ it.
But it is in theory. But having encountered such a loop in practice somewhere in the code, does it make sense to replace it ++ with ++ it? Wouldn't it be better to rely on a compiler, which even without us will guess that an extra iterator can be thrown away?
The answers will be strange, but their reason will become clear from further experiments.
Yes, you need to replace it ++ with ++ it.
Yes, the compiler will optimize and there will be no difference what increment to use.
I chose the “average compiler” and created a test project for Visual Studio 2008. It has two functions that count the sum using it ++ and ++ it, as well as measuring their running time. Download the project here . The code of the functions whose speed was measured:
1) Postfix increment. iterator ++.
std :: vector <size_t> :: const_iterator it; for (it = arr.begin (); it! = arr.end (); it ++) sum + = * it;
2) Prefix increment. ++ iterator.
std :: vector <size_t> :: const_iterator it; for (it = arr.begin (); it! = arr.end (); ++ it) sum + = * it;
The speed of the release version:
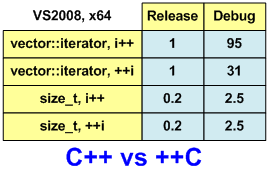
iterator ++. Total time: 0.87779
++ iterator. Total time: 0.87753
This is the answer to the question whether the compiler can optimize the postfix increment. Can. If you look at the implementation (assembly code), you can see that both functions are implemented by an identical set of instructions.
And now let's answer the question, why then it is worth changing it ++ to ++ it. Let's measure the speed of the Debug version:
iterator ++. Total time: 83.2849
++ iterator. Total time: 27.1557
Writing code so as to slow down 30, and not 90 times, is quite practical.
Of course, for many, the speed of debugging (debug) versions is not so important. However, if the program does something significant in time, then such a slowdown can be critical. For example, in terms of unit tests. So it makes sense to optimize the speed of the debug version.
Additionally, I conducted an experiment, what will happen if I use the good old size_t for indexing. This, of course, does not apply to the topic under consideration. I understand that iterators cannot be compared with indexes, and that these are higher-level entities. But still, out of curiosity, I wrote and measured the speed of the following functions:
1) Classical index type size_t. i ++.
for (size_t i = 0; i! = arr.size (); i ++) sum + = arr [i];
2) Classic type index size_t. ++ i.
for (size_t i = 0; i! = arr.size (); ++ i) sum + = arr [i];
The speed of the release version:
iterator ++. Total time: 0.18923
++ iterator. Total time: 0.18913
The speed of work in the debug version:
iterator ++. Total time: 2.1519
++ iterator. Total time: 2.1493
As expected, the speed of i ++ and ++ i coincided.
Note. The code with size_t works faster compared to iterators due to the fact that there is no check for overrun of the array. The loop with iterators can be made as fast in the Release version by typing "#define _SECURE_SCL 0".
To make it easier to evaluate the results of speed measurements, I will present them in the form of a table (Figure 1). I recalculated the results, taking as a unit the running time of the Release version with iterator ++. And a little more rounded numbers for simplicity.
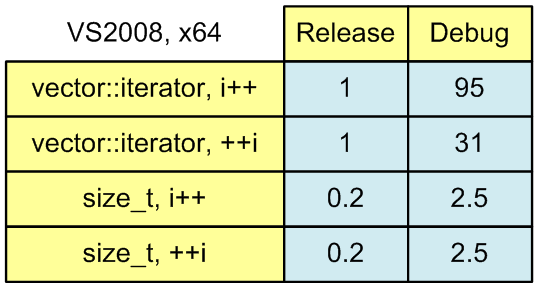
Figure 1. The running time of the sum calculation algorithms.
Everyone can make conclusions for themselves. They depend on the type of tasks. For myself, I did the following:
- I was convinced of the feasibility of such a micro-optimization. In PVS-Studio, it is worthwhile to implement a search for a postfix iterator increment if its previous state is not used. Some programmers will find this functionality useful. And the rest, if it interferes, will always be able to disable this diagnostics in the settings.
- I will always write ++ it. I've done it before. But he did it "just in case." Now I see the benefits of this, since it is important for me to regularly launch debug versions. Of course, in general, the work time ++ it will have a very small effect. But if such small optimizations are not done in different places, then it will be too late. Profiler does little to help. Slow places will be “smeared with a thin layer” throughout the code.
- I notice that more and more time the PVS-Studio analyzer spends inside various functions of the classes std :: vector, std :: set, std :: string and so on. This time is growing and growing, as more and more new diagnostic rules appear, and it is convenient to write them just using STL. So I think, whether that most terrible time has come when the program has its own specialized classes of strings, arrays, and so on. But this is about my ... You do not listen to me! I say seditious things ... Shhh ...
PS
Now someone will say that premature optimization is evil [2]. When optimization is needed, you must take a profiler and look for bottlenecks. I know all this. And I have not had any specific bottlenecks for a long time. But when you wait for the tests to finish within 4 hours, you begin to think that winning even 20% of the speed is already good. And this optimization is made up of iterators, the size of structures, sometimes the rejection of STL or Boost, and so on. I think some developers will understand me well.
Bibliographic list
- Meyers S. The most effective use of C ++. 35 new recommendations for improving your programs and projects: Trans. from English - M .: DMK Press, 2000. - 304 pp., Ill. (A series for programmers). ISBN 5-94074-033-2. BBK 32.973.26-018.1.
- Elena Sagalaeva. Premature optimization. http://alenacpp.blogspot.com/2006/08/blog-post.html
UPDATE: After the article " Learning benchmarking correctly (including iterators) " I corrected the project code, made new measurements and corrected the article a little. There are no changes for the Release versions, but Debug showed a strong difference. However, this does not affect the correctness of the article, its content and conclusions.
Source: https://habr.com/ru/post/113661/
All Articles