Having fun with hashes
Hey. I want to show you a little trick. First you need to download the archive with two files . Both are the same size and the same md5 sum. Check no cheating there. The md5 hash of both is equal to ecea96a6fea9a1744adcc9802ab7590d. Now run the program good.exe and you will see the following on the screen. 
Try running the evil.exe program.
Something went wrong? Want to try it yourself?
In fact, there is nothing new in all this. In fact, this effect is achieved through methods for quickly searching for collisions for a hash function developed back in 2004–2006. If anyone knows, a collision is two different data sets that have the same hash value. So, in 2004, a group of Chinese researchers developed an algorithm based on differential cryptoanalysis, allowing for a relatively short time to find two different random data blocks, 128 bytes each, having the same md5 sum. And although this algorithm at one time produced the effect of an exploded bomb, its speed left much to be desired. But already in 2006, the Czech cryptographer Vlastimil Klima offered to search for collisions a new method that allows you to find a different pair of random 128 byte blocks with one md5 sum on a personal computer in less than a minute.
You may ask, but what will give us the possession of such a pair of messages, not only are they short (128 bytes in total), so also, in addition, and random ones, i.e. the method does not allow for a given message to pick up another one with an identical hash. However, this opens a huge scope for various kinds of attacks on executable files. And the reason for this is the following feature of any hash function: The hash function is iterative in nature. This means that when the hash is calculated, the message is divided into blocks, a compression function is applied to each block, depending on some variable called the initialization vector. The result of this function will be the initialization vector for the next block. The result of the function after working with the last block will be the final hash value of our message.
')
Schematically it can be represented as follows:
s i + 1 = f (s i , M i ), where s i is the initialization vector for the i-th block.
The Vlastimil Klima method allows for any given value of s i to pick up two 128-byte blocks M, M` and N, N` such that f (f (s, M), M ') = f (f (s, N), N ').
Thus, using this technique, you can construct two files with the same md5 sum, but having different 128 bytes in the middle.
M 0 , M 1 , ..., M i-1 , M i , M i + 1 , M i + 2 , ..., M n ,
M 0 , M 1 , ..., M i-1 , N i , N i + 1 , M i + 2 , ..., M n .
Please note that the hashes of both of these files match, because distinct blocks M i , M i + 1 and
N i , N i + 1 will return the same value as s i + 2 , since f (f (s, M i ), M i + 1 ) = f (f (s, N i ), N i + 1 ), and since all subsequent data are identical, the subsequent values of the compression function for both files will be the same.
We now turn from things abstract and remote to a practical question. Suppose we have an executable file M 0 , M 1 , X, X, ..., M n . But based on it, we can create two different files M 0 , M 1 , N 1 , N 1 , ..., M n and M 0 , M 1 , N 2 , N 1 , ..., M n (simply change the blocks X to N 1 and N 2 ). If blocks N 1 and N 2 are collisions, then the hash sum of these files will be the same.
Now imagine that this executable file has the following structure:
if (X == X) then {good_program} else {evil_program}
That's actually the whole secret of this focus.
Now let's talk a little about how to do it yourself.
Step one: write a double bottom program.
Please pay particular attention to the variables str1 and str2. They serve so that they can be quickly found in the hex editor and replaced with the necessary data.
The main function, depending on the contents of the variables s, causes a good or bad version of the program.
Step Two: After compiling the program, you will need to work a bit with the hex editor in order to find our str1 and str2 strings in the .exe file. Copy the resulting .exe file. Let the copy be called the "cropped version." Open the copy in the hex editor and find the str1 and str2 lines in it. Delete all data going after the first 64 bytes of the first of the lines. The last lines of the resulting file will look like this: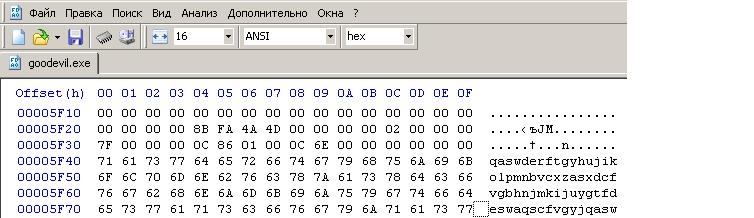 . Save this file.
. Save this file.
Step Three: The file created in the second step will serve as a so-called prefix for searching for collisions. To find a conflict with a given prefix, you need to download the fastcoll program from here (Thanks to its author Marc Stevens). Sources are here .
Run the program with the –p parameter. As a prefix, specify the “cropped version”. As a result, the program will create two files “trimmed version_msg1” and “trimmed version_msg2”.
Step Four: Create another copy of your program. Let the original be called good.exe, and a copy of evil.exe. Open the msg1 and msg2 files in the hex editor. First, replace the block in which str2 is stored with the data from the str1 block. Let them now have the same information. After that, copy the last 128 bytes from the msg1 file and paste them into your good file as shown in the figure.

Please note that indents should correspond to the following parameters: the first block is inserted right where the “cropped version” file ends, the second block is located 96 bytes from the first. Important: insert the same blocks. This will be a good version of our program. Save the good.exe file and open the evil.exe file. Blocks in the evil.exe file will need to be inserted in the same places as in good.exe, the only difference is that we take the first block from the msg2 file and the second one from the msg1 file. This difference will provide us with the failure to comply with the condition of the program if (s == s2) and, accordingly, will launch the evil version of the program.
Step Five: Profit! Compare md5 sums of files, enjoy the result.
Bibliography:
1. A wonderful site with a description of this method.
2. Vlastimil Klima website
3. The site of the author of the program findcoll
Try running the evil.exe program.
Something went wrong? Want to try it yourself?
About hashes and collisions
In fact, there is nothing new in all this. In fact, this effect is achieved through methods for quickly searching for collisions for a hash function developed back in 2004–2006. If anyone knows, a collision is two different data sets that have the same hash value. So, in 2004, a group of Chinese researchers developed an algorithm based on differential cryptoanalysis, allowing for a relatively short time to find two different random data blocks, 128 bytes each, having the same md5 sum. And although this algorithm at one time produced the effect of an exploded bomb, its speed left much to be desired. But already in 2006, the Czech cryptographer Vlastimil Klima offered to search for collisions a new method that allows you to find a different pair of random 128 byte blocks with one md5 sum on a personal computer in less than a minute.
You may ask, but what will give us the possession of such a pair of messages, not only are they short (128 bytes in total), so also, in addition, and random ones, i.e. the method does not allow for a given message to pick up another one with an identical hash. However, this opens a huge scope for various kinds of attacks on executable files. And the reason for this is the following feature of any hash function: The hash function is iterative in nature. This means that when the hash is calculated, the message is divided into blocks, a compression function is applied to each block, depending on some variable called the initialization vector. The result of this function will be the initialization vector for the next block. The result of the function after working with the last block will be the final hash value of our message.
')
Schematically it can be represented as follows:
s i + 1 = f (s i , M i ), where s i is the initialization vector for the i-th block.
The Vlastimil Klima method allows for any given value of s i to pick up two 128-byte blocks M, M` and N, N` such that f (f (s, M), M ') = f (f (s, N), N ').
Thus, using this technique, you can construct two files with the same md5 sum, but having different 128 bytes in the middle.
M 0 , M 1 , ..., M i-1 , M i , M i + 1 , M i + 2 , ..., M n ,
M 0 , M 1 , ..., M i-1 , N i , N i + 1 , M i + 2 , ..., M n .
Please note that the hashes of both of these files match, because distinct blocks M i , M i + 1 and
N i , N i + 1 will return the same value as s i + 2 , since f (f (s, M i ), M i + 1 ) = f (f (s, N i ), N i + 1 ), and since all subsequent data are identical, the subsequent values of the compression function for both files will be the same.
What does this give us
We now turn from things abstract and remote to a practical question. Suppose we have an executable file M 0 , M 1 , X, X, ..., M n . But based on it, we can create two different files M 0 , M 1 , N 1 , N 1 , ..., M n and M 0 , M 1 , N 2 , N 1 , ..., M n (simply change the blocks X to N 1 and N 2 ). If blocks N 1 and N 2 are collisions, then the hash sum of these files will be the same.
Now imagine that this executable file has the following structure:
if (X == X) then {good_program} else {evil_program}
That's actually the whole secret of this focus.
How to make yourself
Now let's talk a little about how to do it yourself.
Step one: write a double bottom program.
#include <stdafx.h>
#include<iostream>
#include < string >
using namespace std;
// str1 str2 X.
static char *str1= "qwertyuioplkjhgfdaszxcvbnmkjhgfdsaqwertyuikjh"\
"gbvfdsazxdcvgbhnjikmjhbgfvcdsazxdcfrewqikolkjnhgfqwertyuioplkjh"\
"gfdaszxcvbnmkjhgfdsaqwertyuikjhgbvfdsazxdcvgbhnjikmjhbgfvcdsa"\
"zxdcfrewqikolkjnhgfq123" ;
static char *str2= "qaswderftgyhujikolpmnbvcxzasxdcfvgbhnjmkijuy"\
"gtfdeswaqscfvgyjqaswderftgyhujikolpmnbvcxzasxdcfvgbhnjmkijuyg"\
"tfdeswaqscfvgyjqaswderftgyhujikolpmnbvcxzasxdcfvgbhnjmkijuygt"\
"fdeswaqscfvgyjqwertyuikja2" ;
int good()
{
int a;
std::cout<< "Good, nice programme!" ;
std::cin>>a;
return 0;
}
int bed()
{
int a;
for ( int i=0; i<1000; i++)
{
std::cout<< "Evil, evil code!" ;
}
std::cin>>a;
return 0;
}
int _tmain( int argc, _TCHAR* argv[])
{
// s s2
string s=str1;
string s2=str2;
s.erase(0,56);
s.erase(128,8);
s2.erase(0,64);
if (s==s2) {
return good();
} else {
return bed();
}
return 0;
}
* This source code was highlighted with Source Code Highlighter .Please pay particular attention to the variables str1 and str2. They serve so that they can be quickly found in the hex editor and replaced with the necessary data.
The main function, depending on the contents of the variables s, causes a good or bad version of the program.
Step Two: After compiling the program, you will need to work a bit with the hex editor in order to find our str1 and str2 strings in the .exe file. Copy the resulting .exe file. Let the copy be called the "cropped version." Open the copy in the hex editor and find the str1 and str2 lines in it. Delete all data going after the first 64 bytes of the first of the lines. The last lines of the resulting file will look like this:
. Save this file.Step Three: The file created in the second step will serve as a so-called prefix for searching for collisions. To find a conflict with a given prefix, you need to download the fastcoll program from here (Thanks to its author Marc Stevens). Sources are here .
Run the program with the –p parameter. As a prefix, specify the “cropped version”. As a result, the program will create two files “trimmed version_msg1” and “trimmed version_msg2”.
Step Four: Create another copy of your program. Let the original be called good.exe, and a copy of evil.exe. Open the msg1 and msg2 files in the hex editor. First, replace the block in which str2 is stored with the data from the str1 block. Let them now have the same information. After that, copy the last 128 bytes from the msg1 file and paste them into your good file as shown in the figure.
Please note that indents should correspond to the following parameters: the first block is inserted right where the “cropped version” file ends, the second block is located 96 bytes from the first. Important: insert the same blocks. This will be a good version of our program. Save the good.exe file and open the evil.exe file. Blocks in the evil.exe file will need to be inserted in the same places as in good.exe, the only difference is that we take the first block from the msg2 file and the second one from the msg1 file. This difference will provide us with the failure to comply with the condition of the program if (s == s2) and, accordingly, will launch the evil version of the program.
Step Five: Profit! Compare md5 sums of files, enjoy the result.
Bibliography:
1. A wonderful site with a description of this method.
2. Vlastimil Klima website
3. The site of the author of the program findcoll
Source: https://habr.com/ru/post/113127/
All Articles