How does cloud billing work?
When we created the cloud, writing billing was one of the hardest tasks. We decided to follow the path of maximum separation of components and weak linking. Thanks to this, the whole process is divided into several independent components: collecting information about the resource consumption of the virtual machine components, storing this information, debiting customers' accounts, storing the history of debiting funds (somewhere near the replenishment history and written paper invoices, etc. d.)
As you can see, there are two big stages: collecting information about consumption (at this stage there is still no money, but there are bytes, seconds, requests) and the process of turning them into money (as well as everything related to this - writing off, storing history) .
Here is a teaser - a weekly chart of total customer debits:
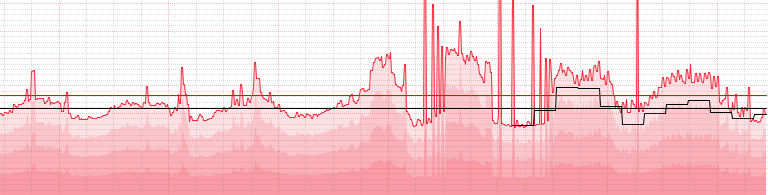
')
It is between “consumption” and “write-off of money” that the weakest link is found. For each client-owned object, we store fields with one or more counted resources. As previously described, memory and processor time is an attribute of the virtual machine, disk operations vbd, disk storage vdi, network vif.
The system that collects information turned out to be naturally distributed. The service itself is called consumption. The data of this service is stored in the ha-cluster in the centralized b / d (so that when the machine is migrated / restarted between the cloud nodes, the statistics continue to be considered another service, but to the same database).
The service of writing off money is “closer” to the base with money and is completely independent of the other components, it takes consumption, price, balance and issues a new balance and write-off at the output, without thinking about anything else. It receives data from the service via SCAPI (I will write a lot about it when we present it to the public, while this is only an internal means of interaction between the components).
When we made the system, it was decided once and for all to abandon fractional kopecks on the client's account. The minimum write-off unit is a penny. To do this, we introduced a simple rule: the funds for the resource are written off only when they run to a penny and it is written off so that fractional kopecks do not exist (that is, there remains a small unpaid balance). At the moment, the service of write-offs runs through the machines once a minute, although nothing prevents (except for issues of excessive server load) to do it at any speed. When a client sees resource consumption in the “0” box, it usually means that the resource has not yet counted at least one per penny.
At the same time, as is clear, the idea of “writing off only whole kopecks” has nothing to do with the metering accuracy in the service consumption, where accuracy is determined by the size of int64 (therefore, we refused nanoseconds in favor of microseconds for processor time) and the meaning of the value (for example, the base value for RAM, we have kilobytes, not bytes, because it is impossible to allocate less kilobytes, more precisely, four kilobytes - the size of the memory page).
Of course, no "traffic is rounded up to megabytes in a big way" and other inventions. How many thought - so much thought. From this consumption is deducted for the whole amount of rubles / kopecks, this is what is written off from the client's account. The balance will be summarized with subsequent consumption and will be written off at the same time.
Later, when transmitting by the “list”, the values are enlarged, although the accuracy is not lost, since the integration does not affect the adders. For interest, here's a chain of aggregations for CPU time: xen: nanosecond; consumption: microsecond; service charges: second; web interface: hour
As you can see, there are two big stages: collecting information about consumption (at this stage there is still no money, but there are bytes, seconds, requests) and the process of turning them into money (as well as everything related to this - writing off, storing history) .
Here is a teaser - a weekly chart of total customer debits:
')
It is between “consumption” and “write-off of money” that the weakest link is found. For each client-owned object, we store fields with one or more counted resources. As previously described, memory and processor time is an attribute of the virtual machine, disk operations vbd, disk storage vdi, network vif.
The system that collects information turned out to be naturally distributed. The service itself is called consumption. The data of this service is stored in the ha-cluster in the centralized b / d (so that when the machine is migrated / restarted between the cloud nodes, the statistics continue to be considered another service, but to the same database).
The service of writing off money is “closer” to the base with money and is completely independent of the other components, it takes consumption, price, balance and issues a new balance and write-off at the output, without thinking about anything else. It receives data from the service via SCAPI (I will write a lot about it when we present it to the public, while this is only an internal means of interaction between the components).
When we made the system, it was decided once and for all to abandon fractional kopecks on the client's account. The minimum write-off unit is a penny. To do this, we introduced a simple rule: the funds for the resource are written off only when they run to a penny and it is written off so that fractional kopecks do not exist (that is, there remains a small unpaid balance). At the moment, the service of write-offs runs through the machines once a minute, although nothing prevents (except for issues of excessive server load) to do it at any speed. When a client sees resource consumption in the “0” box, it usually means that the resource has not yet counted at least one per penny.
At the same time, as is clear, the idea of “writing off only whole kopecks” has nothing to do with the metering accuracy in the service consumption, where accuracy is determined by the size of int64 (therefore, we refused nanoseconds in favor of microseconds for processor time) and the meaning of the value (for example, the base value for RAM, we have kilobytes, not bytes, because it is impossible to allocate less kilobytes, more precisely, four kilobytes - the size of the memory page).
Of course, no "traffic is rounded up to megabytes in a big way" and other inventions. How many thought - so much thought. From this consumption is deducted for the whole amount of rubles / kopecks, this is what is written off from the client's account. The balance will be summarized with subsequent consumption and will be written off at the same time.
Later, when transmitting by the “list”, the values are enlarged, although the accuracy is not lost, since the integration does not affect the adders. For interest, here's a chain of aggregations for CPU time: xen: nanosecond; consumption: microsecond; service charges: second; web interface: hour
Source: https://habr.com/ru/post/112617/
All Articles