Dark matter of the internet
Sometimes I open a torrent client window and just watch how it distributes files ... It is fascinating even more than defragmentation or geysers and volcanoes in a three-liter jar with homemade kvass. After all, I help many strangers to me to download the files they need. My home computer is a small server, the resources of which I share with the entire Internet. Probably, similar feelings encourage thousands of volunteers around the world to participate in projects like folding @ home.
Not a single file server would have coped with the volume of distribution that is provided by millions of small computers around the world, using only a small part of their resources. If I could just as easily share resources with any site I liked! If the costs of hosting with the growth of the audience grew not linearly, but logarithmically, due to the “voluntary botnet” from visitors' computers. How much less advertising would I see? How many interesting startups would get rid of headaches about scaling? How many non-commercial projects could cease to depend on the benevolence of patrons? And how much more difficult it would be for the cybercriminals or the special services of DDoS to have such a site!
Now in the world there are more than one and a half billion computers connected to the Internet. Of these, about 500 million have a broadband connection. If we assume that the average age of a home computer is about two years, then we can assume that it has a simple dual-core processor, 1 -2 gigabytes of memory and a 500 gigabyte screw. For definiteness, suppose also that the average speed of a broadband connection is 10 megabits / sec.
Is it a lot or a little? What happens if we manage to get to this hidden mass of resources? Let's estimate by eye. Suppose that if you leave these computers turned on around the clock, then at least three-quarters of their resources will be idle (this is more than a cautious estimate, the average server load of 18% appears on Wikipedia!). If you boot the computer properly, it will increase the power consumption, say 70 watts per computer, or 50 kilowatt-hours per month. With an average price of electricity in the world of about 10 cents per kilowatt-hour - this is $ 5 per month. Plus, there is the issue of increased wear. The question is quite controversial, most components of serious manufacturers hopelessly become obsolete much earlier than they break, besides, it is believed that constant on-off and associated heating-cooling and other transients result in resource development faster than round-the-clock work. Nevertheless, we will include in the calculation the extra $ 150 for repairs, smeared, say, for 4 years of operation. This is just over 3 dollars a month. Total - $ 8 per month or $ 100 per year of additional expenses. On the other hand, if three-quarters of the resources for which we had already paid at the time of buying a computer are now idle, then at an average price of $ 500, we throw away $ 375 in a landfill. If we consider that we spent these 375 immediately, then when allocating this amount for 4 years of operation, we get exactly the same $ 100 per year. Perhaps, it is worth mentioning that a computer, even when it uses 10% of its power, consumes not 10 times less electricity, but only two times. But we will not be crushed. After all, 99% of people who have a computer at home and high-speed Internet belong to the “golden billion”, so plus or minus a few dollars a month do not play a big role.
')
So let's put it all together. 1 gigabyte of memory, one and a half cores at 1.5 - 2 gigahertz, 350 gigs per screw, 7 megabit / s channel multiply by half a billion:
A critical reader (and I hope there are most of them here) may require prooflinks to all the numbers in the previous paragraph. I risked not to bring them, as there would be several dozen references to disparate pieces of statistics of varying degrees of reliability over the past few years, which would have clogged the text. For disclosing the topic of the article, the order of magnitudes is important, so special accuracy is not needed. Nevertheless, if someone has a ready-made reliable statistics from the same opera, and it is very different from my figures, I will be glad to see it.
So much of this ocean of resources remains untapped. How to get to her? Is it possible to make the site availability with a sharp increase in attendance grow, and not fall, as it happens in file-sharing networks? Is it possible to create a system that would allow me to give some of my computer’s free resources to an interesting startup to help it get on its feet? The first steps in this direction are already being taken, but, like any first steps, we cannot call them particularly successful. Any distributed systems are an order of magnitude more complicated than centralized ones with comparable functionality. Explain what a hyperlink to a file that is stored somewhere on the server, you can even child. But to understand how DHT works, not every adult can.
The biggest problem that we have to deal with when “smearing” a site across an indefinite number of client computers is dynamic content. Distributed storage and distribution of static pages is not much different from the distribution of any other files. The issue of integrity and authenticity of pages is solved with the help of hashes and digital signatures. Unfortunately, the era of static sites on pure HTML ended earlier than distributed networks and protocols matured and widely distributed. The only niche where there are no other alternatives is anonymous encrypted networks like FreeNet or GNUnet . In them to create a normal web server with a permanent address is impossible by definition. " Sites " in these networks consist of a set of static pages or messages, combined into forums . In addition, the more traffic is encrypted and anonymized, the faster the bandwidth of such networks tends to zero, and the response time to infinity. Most people are not ready to tolerate such inconveniences for the sake of anonymity and privacy. Such networks remain the lot of geeks, political dissidents and any evil spirits like pedophiles. When I began to write about privacy, the paragraph has grown so much and so strongly protruded from the surrounding text that I designed it with a separate topic. So here's a lyrical digression .
A little closer to our topic is the Osiris project . It focuses on the creation of distributed sites - "portals", and not on anonymous file sharing and messages. Although anonymity is also there more than enough. So that irresponsible Anonymus does not foul the portals with flood and spam, a reputation accounting system is used, which can work in a “monarchical” mode - the owner of the portal assigns a reputation, and all visitors participate in the “anarchistic” mode. The project is relatively young, the authors are Italians, most of the documentation has not yet been translated even into English (not to mention Russian), so the Wikipedia article will probably be more content than the official site.
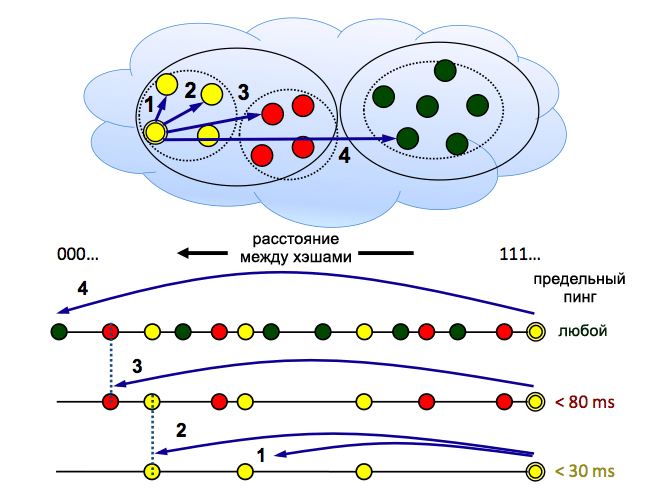
Much more interesting is the distributed caching system and CDN. Many have heard about Coral CDN . Although the Coral distributed network is based on PlanetLab servers and not on user computers, its architecture is of great interest. One of the main features of the network is to help small sites at peak times under the slashdot or habra effect. Enough to add to the right of the URL of the resource "magic words" .nyud.net, and all traffic will go through Coral. When accessing a link, the network searches for the necessary resource by request hash, using a modified DHT version - sloppy DHT. The word “sloppy” means that information about peers is “blurred” over several nodes with a close hash value, reducing the load on the node closest to the resource hash (if you did not understand anything in the last sentence, then here is the understandable language of the basics of Distributed Hash architecture Table). In addition, Coral splits the hash table into clusters, depending on the ping between the nodes, in order to reduce the response time - because if you download the movie you can wait a minute for DHT to find enough peers, then when the page loads, the extra few seconds are annoying. Here is a more detailed description .
Two more small steps towards distributed websites are BitTorrent DNA and FireCoral. DNA is based on BitTorrent, and is designed to distribute heavy content. It requires the installation of a downloader on the client machine that actually downloads files or videos. The principle of the loader is not much different from the usual torrent pump, except that streaming video is always loaded sequentially so that you can start watching without waiting for the full load. Downloaded files are cached and distributed to other clients. I have come across DNA loaders a couple of times when I downloaded some drivers. It works all so far only under Windows.
FireCoral is the younger relative of the Coral CDN, an add-on for FireFox that should work on the basis of client computers, not PlanetLab servers. I didn’t manage to really drive him, because at the time of writing this article only 1404 people downloaded this add-on. And he used it as much as 1 person in the last 24 hours.
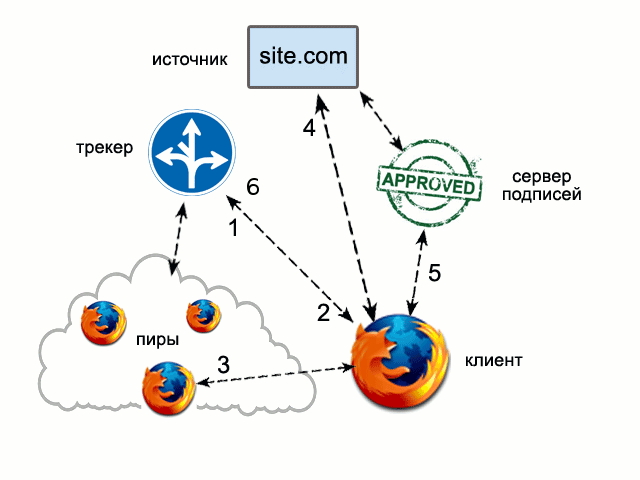
Here is a detailed description of the FireCoral architecture . In a nutshell: FireCoral intercepts HTTP requests, and if there is nothing suitable in the browser cache, it accesses the tracker (1). The tracker either informs (2) the peer addresses to the client, which have the necessary file in the cache (3), or sends it to the source server, if the query has not yet been cached, or the cache version is expired (4). The authenticity of everything FireCoral downloaded from peers is certified by a digital signature provided by a trusted signature server (5). Having completed the processing of the request, FireCoral informs the tracker that it now also has a copy (6).
The disadvantages of existing distributed caching systems are obvious and quite significant. Caching occurs without the participation (moreover, without the knowledge!) Of the server. This makes it difficult to collect visitor statistics, control the distribution of content and creates potential security risks for both the server and the client. From the point of view of the site, such a P2P network is very similar to an open proxy server . To cope with these difficulties is possible only if the site knows about the existence of a distributed cache and controls it. In terms of the FireCoral architecture, this means that the source server simultaneously serves as both a tracker and a trusted signature server. If now the web server independently does all the work on customer service, then in such an architecture it remains only for the role of "supervisor" who manages the feasts that do all the dirty work.
Even more possibilities appear if not only the web server cooperates with the P2P network, but also the clients explicitly help a specific site. That is, they not only share the content they have downloaded for themselves, but allow the site to store information on their disk that they do not specifically need, for example, rarely used content. Or help to make complex calculations.
With storage is easiest. Cryptography allows you to store any data in the cloud or on the server without trusting it. This is how Wuala, for example, is one of Dropbox's competitors. Wuala allows you to increase the available space for storing your files, not only at the expense of their data centers, but also at the expense of user disk space. That is, the client program uses my computer as part of cloud storage. I pay for storing my files in the cloud not with money, but with the resources of my disk and Internet connection. All files are encrypted, so I do not know who and what is stored on my screw, moreover, the files are not stored as a whole, but in parts, this is actually a distributed file system. That is, the chances that someone will collect piece by piece and decrypt my files are vanishingly small.
Unfortunately, Wuala does not really promote this chip, but they can be understood. To loudly and distinctly offer users to increase available space for free means to cut the branch on which you are sitting. To promote synchronization and storage services in a P2P cloud, we need a different business model. For example, a resource exchange is so much a terabyte of demand for some more supply. It is necessary to include money in this equation, for example, I have 100 gigabytes of free space, and in order to compensate for the files I keep in the cloud, I need 150. Instead of missing 50 gigabytes, I pay with money. Service takes a small commission. And if enough users are typed, and the balance of supply and demand allows, it will be possible to sell resources to the side.
Returning to distributed web servers, you can imagine a system like Flattr , but instead of money, it will allocate gigabytes and megabits, and not specific pieces of content, but entire sites will be evaluated.
Much worse with calculations. We cannot just allow someone to manipulate our data on our machine. If encryption allows you to store any information anywhere, without fearing for its confidentiality, and signatures and certificates allow anyone to distribute our information, eliminating the possibility of forgery, then it is impossible to process and modify this information in an encrypted and signed form. We will have to some extent trust the nodes of a distributed network. And you have to spend resources on checking nodes for random or intentional data corruption.
The issue of trust cannot be resolved head-on on the client computer. Obfuscating the client code, all anti-cheat monitors is a cumbersome, uncomfortable crutch. The creators of all kinds of MMORPG are fighting with this constantly . Sooner or later everything can be patched. Rather, almost everything. There is such a thing - trusted computing . Welcome to the beautiful new world! Richard Stallman's nightmare, Big Brother's dream - there is a chip in every computer that makes sure that we only do what we are supposed to do, when it should be and how it should be. This solution is much worse than the problem itself.
Another method actually works. He has long been successfully used by mother nature. It is immunity. Any organism very effectively detects hostile or improperly working cells and destroys them. Similar systems are invented for P2P networks.
For example, the BOINC platform for distributed computing, on which the “something @ home” projects are based. It uses the consensus method . The same piece of data is given to the calculation of several participants, and the result is entered into the database only if all returned the same data. If not, then someone was mistaken or cheated. You can correct the error in two main ways - if there is a trusted server, the calculation of the disputed portion of data is entrusted to it, and everyone who gave a different answer goes through the forest. If the network is fully distributed and peer-to-peer, then the answer that is given by the majority of participants is considered correct, this method is known as “quorum consensus”. In addition, an intermediate option is possible - reputation is calculated for each node by the result of previous work. The response of nodes with more reputation has more weight in resolving the conflict.
How does all this apply to distributed websites? Any data that the web server gives can be divided into four groups:
So, today there is already a fundamental opportunity to reach the “dark matter” of the global network resources. However, only file sharing has become really massive. Probably, the fact is that the full-fledged and secure operation of the P2P site requires a serious review of the fundamentals of site building - the architecture and access control approach is changing dramatically, new risks arise. And of course, the eternal problem of chicken and eggs. There are no distributed sites, because there is no infrastructure, no infrastructure, because there are no distributed sites.
Now, in my opinion, the most promising attempt to break this vicious circle from distributed sites, and not infrastructure, is the Diaspora project . Although so far the development is in the alpha version stage, they managed to attract the attention of the general public and collect a lot of money on kickstarter.com. Even Mark Zuckerberg contributed to the financing of the project. The creators of the Diaspora do not threaten to solve the problem of distributed hosting in general, but make a social network that, by its nature, fits well with the P2P architecture. The main "carrot", which they attract people - full control over their data. The diaspora is not the only project of this kind, there are GNUsocial, Appleseed, Crabgrass, but none of them managed to become so popular.
Diaspora is a Ruby on Rails web application. To raise your Diaspora server, you need Linux or MacOS X, thin and nginx on top of it (options are possible here). Until Windows until the hands of the authors did not reach. Creating a simple installer for non-geeks is in the plans for the future. In the Diaspora architecture, botanical terminology is used: the server is the “pod” (pod), the user account is the “grain” (seed). Each pod can contain one or more grains. A post — a photograph, a message, etc. — can belong to one or several "aspects." Aspect - a group of users, for example, “relatives”, “work”, “friends”. Diaspora uses cryptographic access control. What it is?
The familiar access control models, such as ACLs or RBACs , rely entirely on a trusted server that decides who to let in and who not to. Like a guard dog. If our data is stored anywhere, we can no longer expect that on each server there is a rather angry dog that faithfully protects secrets. She may not be there at all, or the dog may confuse his and others. In such conditions, we will have to lock each piece of information on the lock so that only those who have the key can gain access. This is cryptographic control. We control access to any information, encrypting it, and handing out keys to those whom we consider necessary.
The biggest problem of cryptographic control is the practical impossibility of reliably taking access from someone who previously had this access. To do this, you will have to re-encrypt all information with another key, and distribute this key among all members of the group. Even if we manage to do it fairly quickly, we cannot expect that the user removed from the group did not save the decrypted information when he still had the appropriate key. However, we have become accustomed to, that everything published on the Internet remains there forever.
The fact that we cannot make once published information 100% inaccessible does not mean that we should not even try. 99% is not bad either. However, re-encryption and distribution of new keys is a very resource-intensive and slow process. If the number of members of the group from which we want to exclude someone is not very large, and we are satisfied with the 99% guarantee of a successful “weaning”, then we will still encrypt everything and give out new keys. If the group is very large, and there is a lot of information, then the game is not worth the candle, and you can limit yourself only to replacing the keys, so that the excluded user will retain access to the old information, but not to the new one.
What exactly is the cryptographic access control process? Let us need to give access to a group of N users. Information is encrypted with a random key by a symmetric algorithm. This key, in turn, is encrypted with the public keys of each of N. The encrypted information + N differently encrypted instances of the random key are packaged, signed and distributed to the members of the group. To exclude someone from the group, you must repeat the whole process with N-1 keys, and mark the old copy of the encrypted file for deletion at all feasts. Or, if we can accept the fact that the old information will remain available, it is enough just to encrypt the random key to the new information with N-1 user keys in the future. If, on the contrary, we want to give access to a new member of the group, we only need to send him the keys of all the old files.
This is the most straightforward way to implement cryptographic control. To reduce the number of keys distributed, you can use a variety of hierarchical systems derived group keys. Instead of N, you can do with O (logN) keys, but this greatly complicates the scheme. In the limit, when N is a very large number, and the ability to replace keys is absent in principle, a monster such as AACS is obtained - the basis of DRM . Leaving behind the legal, social and ethical aspects of DRM, the AACS device is incredibly exciting. Subset difference tree system is somewhat similar to quantum mechanics - if you think you understand it, then you do not understand it. At least I went through three or four levels of false understanding while I was dealing with her work (maybe more of them, but unfortunately, I don’t have enough free time to keep digging deeper). More information about cryptographic access control can be read here, see chapter 2.3 in the document at the link, only carefully, there is a thick PDF! .
What do you need to make distributed websites commonplace?
First of all, infrastructure. Client software, such as uTorrent, or a browser plugin, like FireCoral, or support for web server functions, such as Opera Unite. What functions should this infrastructure provide?
Secondly, the web application architecture.
, , , , . , . , , , . . , - , , « », , . — , , JavaScript, . . « » , « 24 » .
Actually, this is exactly how server-side caching now looks like. Almost any dynamic page is 99% of such more or less static pieces. The difference is that the finished page will be assembled from these pieces on the client side, and the pieces themselves will be located in the P2P network.
? , - . , , , , . , , . , «», . , - . , , , , — « » , . pubsubhubbub (the funniest of all is the word pronounced by the Japanese).
In principle, the site can temporarily or permanently work without a central server at all. It is necessary only at the stage of initial growth of the network and the formation of the core of the audience. In the future, the server simply speeds up and simplifies the work, and allows the site owners to manage the development of the project. If you use the reputation accounting system, several dozens of the most authoritative nodes can play the role of trackers and certification authorities, maintaining the stability of the community and the integrity of the distributed database. To destroy or control such a network, it is necessary to simultaneously capture most of the authoritative nodes, which is much more difficult than disabling the central server.
To make such a site generally unkillable, it remains to come up DNS . DNS . , Wikileaks , Google, IP-. , , , «» — , . — DNS, Google?
And finally, another fantastic opportunity for fully distributed architecture is division multiplication. Any decentralized site is technically not very difficult to "fork", if it forms a fairly cohesive subgroup of users. Over time, on the site of a single site can grow a whole tree.
Someone this topic may seem too utopian. Most of the technology still looks pretty damp and unreliable. But! . - , , ? ! . , JavaScript , NoSQL , , 200 000 , , . ?
UPD: , , , ( ) , . , - ( ) . - !
UPD2: , .
, , . — PDF:
Cryptographic Access Control for a Network File System
Cryptographic Access Control in Remote Procedure Call
XPeer:A Self-organizing XML P2P Database System
Flexible Update Management in Peer-to-Peer Database Systems
A Flexible Architecture for a Push-based P2P Database
A BitTorrent-based Peer-to-Peer Database Server
A Survey of Broadcast Encryption (, !)
Coral CDN
Attacks on Peer-to-Peer Networks
Design of a Cheat-Resistant P2P Online Gaming System
Securing Content in Peer-to-Peer File Systems
Building secure systems on & for Social Networks
Secure Peer-to-peer Networks for Trusted Collaboration
Not a single file server would have coped with the volume of distribution that is provided by millions of small computers around the world, using only a small part of their resources. If I could just as easily share resources with any site I liked! If the costs of hosting with the growth of the audience grew not linearly, but logarithmically, due to the “voluntary botnet” from visitors' computers. How much less advertising would I see? How many interesting startups would get rid of headaches about scaling? How many non-commercial projects could cease to depend on the benevolence of patrons? And how much more difficult it would be for the cybercriminals or the special services of DDoS to have such a site!
Issue price
Now in the world there are more than one and a half billion computers connected to the Internet. Of these, about 500 million have a broadband connection. If we assume that the average age of a home computer is about two years, then we can assume that it has a simple dual-core processor, 1 -2 gigabytes of memory and a 500 gigabyte screw. For definiteness, suppose also that the average speed of a broadband connection is 10 megabits / sec.
Is it a lot or a little? What happens if we manage to get to this hidden mass of resources? Let's estimate by eye. Suppose that if you leave these computers turned on around the clock, then at least three-quarters of their resources will be idle (this is more than a cautious estimate, the average server load of 18% appears on Wikipedia!). If you boot the computer properly, it will increase the power consumption, say 70 watts per computer, or 50 kilowatt-hours per month. With an average price of electricity in the world of about 10 cents per kilowatt-hour - this is $ 5 per month. Plus, there is the issue of increased wear. The question is quite controversial, most components of serious manufacturers hopelessly become obsolete much earlier than they break, besides, it is believed that constant on-off and associated heating-cooling and other transients result in resource development faster than round-the-clock work. Nevertheless, we will include in the calculation the extra $ 150 for repairs, smeared, say, for 4 years of operation. This is just over 3 dollars a month. Total - $ 8 per month or $ 100 per year of additional expenses. On the other hand, if three-quarters of the resources for which we had already paid at the time of buying a computer are now idle, then at an average price of $ 500, we throw away $ 375 in a landfill. If we consider that we spent these 375 immediately, then when allocating this amount for 4 years of operation, we get exactly the same $ 100 per year. Perhaps, it is worth mentioning that a computer, even when it uses 10% of its power, consumes not 10 times less electricity, but only two times. But we will not be crushed. After all, 99% of people who have a computer at home and high-speed Internet belong to the “golden billion”, so plus or minus a few dollars a month do not play a big role.
')
So let's put it all together. 1 gigabyte of memory, one and a half cores at 1.5 - 2 gigahertz, 350 gigs per screw, 7 megabit / s channel multiply by half a billion:
- + 500 petabyte RAM
- + 750 million cores
- + 175,000 petabytes of disk space
- + 3.5 petabit / sec bandwidth
- - 300 Terawatt-hours of electricity (about 0.3% of world electricity consumption)
- - 100 billion dollars a year, of which 50 we already paid at the time of buying a computer
A critical reader (and I hope there are most of them here) may require prooflinks to all the numbers in the previous paragraph. I risked not to bring them, as there would be several dozen references to disparate pieces of statistics of varying degrees of reliability over the past few years, which would have clogged the text. For disclosing the topic of the article, the order of magnitudes is important, so special accuracy is not needed. Nevertheless, if someone has a ready-made reliable statistics from the same opera, and it is very different from my figures, I will be glad to see it.
So much of this ocean of resources remains untapped. How to get to her? Is it possible to make the site availability with a sharp increase in attendance grow, and not fall, as it happens in file-sharing networks? Is it possible to create a system that would allow me to give some of my computer’s free resources to an interesting startup to help it get on its feet? The first steps in this direction are already being taken, but, like any first steps, we cannot call them particularly successful. Any distributed systems are an order of magnitude more complicated than centralized ones with comparable functionality. Explain what a hyperlink to a file that is stored somewhere on the server, you can even child. But to understand how DHT works, not every adult can.
Mosaic fragments
The biggest problem that we have to deal with when “smearing” a site across an indefinite number of client computers is dynamic content. Distributed storage and distribution of static pages is not much different from the distribution of any other files. The issue of integrity and authenticity of pages is solved with the help of hashes and digital signatures. Unfortunately, the era of static sites on pure HTML ended earlier than distributed networks and protocols matured and widely distributed. The only niche where there are no other alternatives is anonymous encrypted networks like FreeNet or GNUnet . In them to create a normal web server with a permanent address is impossible by definition. " Sites " in these networks consist of a set of static pages or messages, combined into forums . In addition, the more traffic is encrypted and anonymized, the faster the bandwidth of such networks tends to zero, and the response time to infinity. Most people are not ready to tolerate such inconveniences for the sake of anonymity and privacy. Such networks remain the lot of geeks, political dissidents and any evil spirits like pedophiles. When I began to write about privacy, the paragraph has grown so much and so strongly protruded from the surrounding text that I designed it with a separate topic. So here's a lyrical digression .
A little closer to our topic is the Osiris project . It focuses on the creation of distributed sites - "portals", and not on anonymous file sharing and messages. Although anonymity is also there more than enough. So that irresponsible Anonymus does not foul the portals with flood and spam, a reputation accounting system is used, which can work in a “monarchical” mode - the owner of the portal assigns a reputation, and all visitors participate in the “anarchistic” mode. The project is relatively young, the authors are Italians, most of the documentation has not yet been translated even into English (not to mention Russian), so the Wikipedia article will probably be more content than the official site.
Much more interesting is the distributed caching system and CDN. Many have heard about Coral CDN . Although the Coral distributed network is based on PlanetLab servers and not on user computers, its architecture is of great interest. One of the main features of the network is to help small sites at peak times under the slashdot or habra effect. Enough to add to the right of the URL of the resource "magic words" .nyud.net, and all traffic will go through Coral. When accessing a link, the network searches for the necessary resource by request hash, using a modified DHT version - sloppy DHT. The word “sloppy” means that information about peers is “blurred” over several nodes with a close hash value, reducing the load on the node closest to the resource hash (if you did not understand anything in the last sentence, then here is the understandable language of the basics of Distributed Hash architecture Table). In addition, Coral splits the hash table into clusters, depending on the ping between the nodes, in order to reduce the response time - because if you download the movie you can wait a minute for DHT to find enough peers, then when the page loads, the extra few seconds are annoying. Here is a more detailed description .
Two more small steps towards distributed websites are BitTorrent DNA and FireCoral. DNA is based on BitTorrent, and is designed to distribute heavy content. It requires the installation of a downloader on the client machine that actually downloads files or videos. The principle of the loader is not much different from the usual torrent pump, except that streaming video is always loaded sequentially so that you can start watching without waiting for the full load. Downloaded files are cached and distributed to other clients. I have come across DNA loaders a couple of times when I downloaded some drivers. It works all so far only under Windows.
FireCoral is the younger relative of the Coral CDN, an add-on for FireFox that should work on the basis of client computers, not PlanetLab servers. I didn’t manage to really drive him, because at the time of writing this article only 1404 people downloaded this add-on. And he used it as much as 1 person in the last 24 hours.
Here is a detailed description of the FireCoral architecture . In a nutshell: FireCoral intercepts HTTP requests, and if there is nothing suitable in the browser cache, it accesses the tracker (1). The tracker either informs (2) the peer addresses to the client, which have the necessary file in the cache (3), or sends it to the source server, if the query has not yet been cached, or the cache version is expired (4). The authenticity of everything FireCoral downloaded from peers is certified by a digital signature provided by a trusted signature server (5). Having completed the processing of the request, FireCoral informs the tracker that it now also has a copy (6).
The disadvantages of existing distributed caching systems are obvious and quite significant. Caching occurs without the participation (moreover, without the knowledge!) Of the server. This makes it difficult to collect visitor statistics, control the distribution of content and creates potential security risks for both the server and the client. From the point of view of the site, such a P2P network is very similar to an open proxy server . To cope with these difficulties is possible only if the site knows about the existence of a distributed cache and controls it. In terms of the FireCoral architecture, this means that the source server simultaneously serves as both a tracker and a trusted signature server. If now the web server independently does all the work on customer service, then in such an architecture it remains only for the role of "supervisor" who manages the feasts that do all the dirty work.
Even more possibilities appear if not only the web server cooperates with the P2P network, but also the clients explicitly help a specific site. That is, they not only share the content they have downloaded for themselves, but allow the site to store information on their disk that they do not specifically need, for example, rarely used content. Or help to make complex calculations.
With storage is easiest. Cryptography allows you to store any data in the cloud or on the server without trusting it. This is how Wuala, for example, is one of Dropbox's competitors. Wuala allows you to increase the available space for storing your files, not only at the expense of their data centers, but also at the expense of user disk space. That is, the client program uses my computer as part of cloud storage. I pay for storing my files in the cloud not with money, but with the resources of my disk and Internet connection. All files are encrypted, so I do not know who and what is stored on my screw, moreover, the files are not stored as a whole, but in parts, this is actually a distributed file system. That is, the chances that someone will collect piece by piece and decrypt my files are vanishingly small.
Unfortunately, Wuala does not really promote this chip, but they can be understood. To loudly and distinctly offer users to increase available space for free means to cut the branch on which you are sitting. To promote synchronization and storage services in a P2P cloud, we need a different business model. For example, a resource exchange is so much a terabyte of demand for some more supply. It is necessary to include money in this equation, for example, I have 100 gigabytes of free space, and in order to compensate for the files I keep in the cloud, I need 150. Instead of missing 50 gigabytes, I pay with money. Service takes a small commission. And if enough users are typed, and the balance of supply and demand allows, it will be possible to sell resources to the side.
Returning to distributed web servers, you can imagine a system like Flattr , but instead of money, it will allocate gigabytes and megabits, and not specific pieces of content, but entire sites will be evaluated.
Much worse with calculations. We cannot just allow someone to manipulate our data on our machine. If encryption allows you to store any information anywhere, without fearing for its confidentiality, and signatures and certificates allow anyone to distribute our information, eliminating the possibility of forgery, then it is impossible to process and modify this information in an encrypted and signed form. We will have to some extent trust the nodes of a distributed network. And you have to spend resources on checking nodes for random or intentional data corruption.
The issue of trust cannot be resolved head-on on the client computer. Obfuscating the client code, all anti-cheat monitors is a cumbersome, uncomfortable crutch. The creators of all kinds of MMORPG are fighting with this constantly . Sooner or later everything can be patched. Rather, almost everything. There is such a thing - trusted computing . Welcome to the beautiful new world! Richard Stallman's nightmare, Big Brother's dream - there is a chip in every computer that makes sure that we only do what we are supposed to do, when it should be and how it should be. This solution is much worse than the problem itself.
Another method actually works. He has long been successfully used by mother nature. It is immunity. Any organism very effectively detects hostile or improperly working cells and destroys them. Similar systems are invented for P2P networks.
For example, the BOINC platform for distributed computing, on which the “something @ home” projects are based. It uses the consensus method . The same piece of data is given to the calculation of several participants, and the result is entered into the database only if all returned the same data. If not, then someone was mistaken or cheated. You can correct the error in two main ways - if there is a trusted server, the calculation of the disputed portion of data is entrusted to it, and everyone who gave a different answer goes through the forest. If the network is fully distributed and peer-to-peer, then the answer that is given by the majority of participants is considered correct, this method is known as “quorum consensus”. In addition, an intermediate option is possible - reputation is calculated for each node by the result of previous work. The response of nodes with more reputation has more weight in resolving the conflict.
How does all this apply to distributed websites? Any data that the web server gives can be divided into four groups:
- Data, disclosure and unauthorized change of which is absolutely unacceptable - passwords, credit card numbers, private messages and files. They can be stored and transmitted only in encrypted form.
- Data that everyone can see, but their arbitrary change is unacceptable. For example, JavaScript on the page. Such data must be verified and signed by a trusted source.
- Data unauthorized viewing of which is undesirable, but is not a disaster. For example, the contents of closed blogs here on Habré.
- Data whose unauthorized change can be easily corrected afterwards. For example, an article on Wikipedia that is much easier to fix than to spoil. For the sake of greater decentralization, it is possible to allow verification and publication of such data without the participation of a trusted server, using the quorum consensus method.
So, today there is already a fundamental opportunity to reach the “dark matter” of the global network resources. However, only file sharing has become really massive. Probably, the fact is that the full-fledged and secure operation of the P2P site requires a serious review of the fundamentals of site building - the architecture and access control approach is changing dramatically, new risks arise. And of course, the eternal problem of chicken and eggs. There are no distributed sites, because there is no infrastructure, no infrastructure, because there are no distributed sites.
Now, in my opinion, the most promising attempt to break this vicious circle from distributed sites, and not infrastructure, is the Diaspora project . Although so far the development is in the alpha version stage, they managed to attract the attention of the general public and collect a lot of money on kickstarter.com. Even Mark Zuckerberg contributed to the financing of the project. The creators of the Diaspora do not threaten to solve the problem of distributed hosting in general, but make a social network that, by its nature, fits well with the P2P architecture. The main "carrot", which they attract people - full control over their data. The diaspora is not the only project of this kind, there are GNUsocial, Appleseed, Crabgrass, but none of them managed to become so popular.
Diaspora is a Ruby on Rails web application. To raise your Diaspora server, you need Linux or MacOS X, thin and nginx on top of it (options are possible here). Until Windows until the hands of the authors did not reach. Creating a simple installer for non-geeks is in the plans for the future. In the Diaspora architecture, botanical terminology is used: the server is the “pod” (pod), the user account is the “grain” (seed). Each pod can contain one or more grains. A post — a photograph, a message, etc. — can belong to one or several "aspects." Aspect - a group of users, for example, “relatives”, “work”, “friends”. Diaspora uses cryptographic access control. What it is?
The familiar access control models, such as ACLs or RBACs , rely entirely on a trusted server that decides who to let in and who not to. Like a guard dog. If our data is stored anywhere, we can no longer expect that on each server there is a rather angry dog that faithfully protects secrets. She may not be there at all, or the dog may confuse his and others. In such conditions, we will have to lock each piece of information on the lock so that only those who have the key can gain access. This is cryptographic control. We control access to any information, encrypting it, and handing out keys to those whom we consider necessary.
The biggest problem of cryptographic control is the practical impossibility of reliably taking access from someone who previously had this access. To do this, you will have to re-encrypt all information with another key, and distribute this key among all members of the group. Even if we manage to do it fairly quickly, we cannot expect that the user removed from the group did not save the decrypted information when he still had the appropriate key. However, we have become accustomed to, that everything published on the Internet remains there forever.
The fact that we cannot make once published information 100% inaccessible does not mean that we should not even try. 99% is not bad either. However, re-encryption and distribution of new keys is a very resource-intensive and slow process. If the number of members of the group from which we want to exclude someone is not very large, and we are satisfied with the 99% guarantee of a successful “weaning”, then we will still encrypt everything and give out new keys. If the group is very large, and there is a lot of information, then the game is not worth the candle, and you can limit yourself only to replacing the keys, so that the excluded user will retain access to the old information, but not to the new one.
What exactly is the cryptographic access control process? Let us need to give access to a group of N users. Information is encrypted with a random key by a symmetric algorithm. This key, in turn, is encrypted with the public keys of each of N. The encrypted information + N differently encrypted instances of the random key are packaged, signed and distributed to the members of the group. To exclude someone from the group, you must repeat the whole process with N-1 keys, and mark the old copy of the encrypted file for deletion at all feasts. Or, if we can accept the fact that the old information will remain available, it is enough just to encrypt the random key to the new information with N-1 user keys in the future. If, on the contrary, we want to give access to a new member of the group, we only need to send him the keys of all the old files.
This is the most straightforward way to implement cryptographic control. To reduce the number of keys distributed, you can use a variety of hierarchical systems derived group keys. Instead of N, you can do with O (logN) keys, but this greatly complicates the scheme. In the limit, when N is a very large number, and the ability to replace keys is absent in principle, a monster such as AACS is obtained - the basis of DRM . Leaving behind the legal, social and ethical aspects of DRM, the AACS device is incredibly exciting. Subset difference tree system is somewhat similar to quantum mechanics - if you think you understand it, then you do not understand it. At least I went through three or four levels of false understanding while I was dealing with her work (maybe more of them, but unfortunately, I don’t have enough free time to keep digging deeper). More information about cryptographic access control can be read here, see chapter 2.3 in the document at the link, only carefully, there is a thick PDF! .
Fantasies and speculation
What do you need to make distributed websites commonplace?
First of all, infrastructure. Client software, such as uTorrent, or a browser plugin, like FireCoral, or support for web server functions, such as Opera Unite. What functions should this infrastructure provide?
- Implicit automatic distributed caching of sites I visit. (Examples - FireCoral, BitTorrent DNA)
- Explicit provision of resources of my computer to those sites that I want to support. (There are no examples yet. The only thing that comes to mind is the recent events around Wikileaks, when sympathizers manually created hundreds of site mirrors)
- Publish or store in the P2P cloud of my own resources. (Examples - Diaspora, Opera Unite, Wuala)
Secondly, the web application architecture.
- The web server should become a tracker of its own P2P network and certificate authority.
- . - , . , . - key-value . , , .
- , .
- Push on change Pull on demand.
, , , , . , . , , , . . , - , , « », , . — , , JavaScript, . . « » , « 24 » .
Actually, this is exactly how server-side caching now looks like. Almost any dynamic page is 99% of such more or less static pieces. The difference is that the finished page will be assembled from these pieces on the client side, and the pieces themselves will be located in the P2P network.
? , - . , , , , . , , . , «», . , - . , , , , — « » , . pubsubhubbub (the funniest of all is the word pronounced by the Japanese).
In principle, the site can temporarily or permanently work without a central server at all. It is necessary only at the stage of initial growth of the network and the formation of the core of the audience. In the future, the server simply speeds up and simplifies the work, and allows the site owners to manage the development of the project. If you use the reputation accounting system, several dozens of the most authoritative nodes can play the role of trackers and certification authorities, maintaining the stability of the community and the integrity of the distributed database. To destroy or control such a network, it is necessary to simultaneously capture most of the authoritative nodes, which is much more difficult than disabling the central server.
To make such a site generally unkillable, it remains to come up DNS . DNS . , Wikileaks , Google, IP-. , , , «» — , . — DNS, Google?
And finally, another fantastic opportunity for fully distributed architecture is division multiplication. Any decentralized site is technically not very difficult to "fork", if it forms a fairly cohesive subgroup of users. Over time, on the site of a single site can grow a whole tree.
Conclusion
Someone this topic may seem too utopian. Most of the technology still looks pretty damp and unreliable. But! . - , , ? ! . , JavaScript , NoSQL , , 200 000 , , . ?
UPD: , , , ( ) , . , - ( ) . - !
UPD2: , .
, , . — PDF:
Cryptographic Access Control for a Network File System
Cryptographic Access Control in Remote Procedure Call
XPeer:A Self-organizing XML P2P Database System
Flexible Update Management in Peer-to-Peer Database Systems
A Flexible Architecture for a Push-based P2P Database
A BitTorrent-based Peer-to-Peer Database Server
A Survey of Broadcast Encryption (, !)
Coral CDN
Attacks on Peer-to-Peer Networks
Design of a Cheat-Resistant P2P Online Gaming System
Securing Content in Peer-to-Peer File Systems
Building secure systems on & for Social Networks
Secure Peer-to-peer Networks for Trusted Collaboration
Source: https://habr.com/ru/post/112491/
All Articles