Text Recognition Techniques
In spite of the fact that at present most documents are compiled on computers, the task of creating fully electronic document management is still far from being fully implemented. As a rule, existing systems cover the activities of individual organizations, and data exchange between organizations is carried out using traditional paper documents.
The task of transferring information from paper to electronic media is relevant not only within the framework of the needs arising in workflow systems. Modern information technologies allow us to significantly simplify access to information resources accumulated by mankind, provided that they are converted to electronic form.
The easiest and fastest is scanning documents with scanners. The result of the work is a digital image of the document - a graphic file. More preferable, in comparison with graphic, is text representation of the information. This option allows you to significantly reduce the cost of storing and transferring information, and also allows you to implement all possible scenarios for the use and analysis of electronic documents. Therefore, the most interesting from a practical point of view is precisely the translation of paper media into a text electronic document.
The raster image of the document page is input to the recognition system. For the recognition algorithms to work, it is desirable that the incoming image is of the highest possible quality. If the image is noisy, unsharp, has low contrast, then this will complicate the task of recognition algorithms.
')
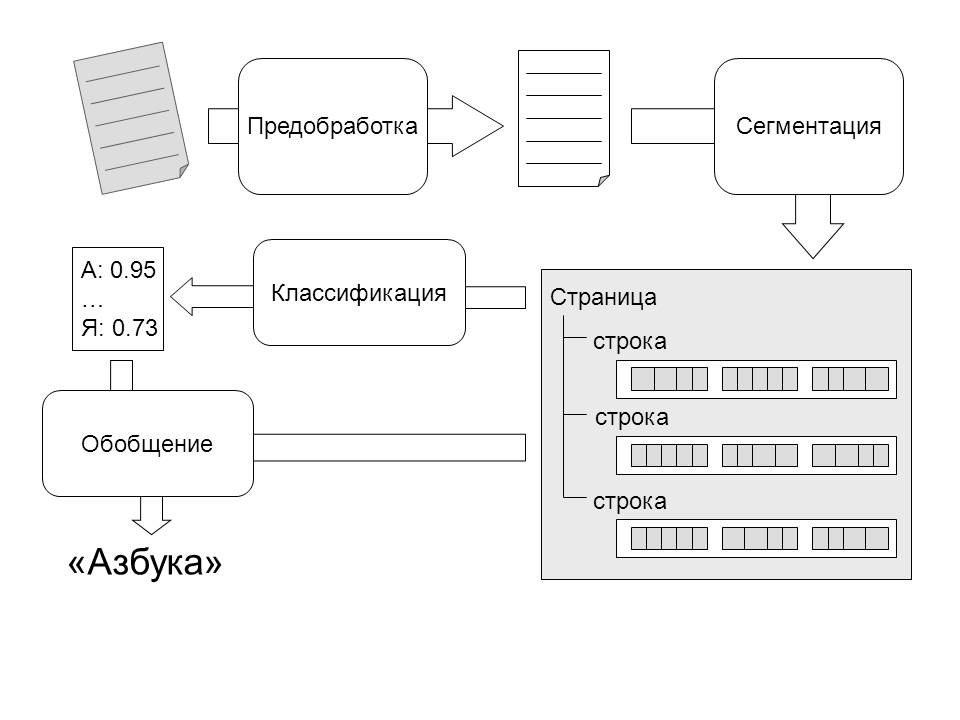
Therefore, prior to image processing by recognition algorithms, it is pre-processed to improve image quality. It includes filtering the image from noise, sharpening and contrasting the image, alignment and conversion to the format used by the system (in our case, an 8-bit image in grayscale).
The prepared image goes to the input of the segmentation module. The purpose of this module is to identify structural units of text - lines, words, and symbols. Selection of high-level fragments, such as lines and words, can be carried out on the basis of the analysis of gaps between dark areas.
Unfortunately, such an approach cannot be applied to isolate individual letters, because, due to the peculiarities of the style or distortion, images of neighboring letters can be combined into one connected component (Fig. 1) or vice versa — the image of one letter can decay into separate connected components ( Fig. 2). In many cases, complex heuristic algorithms are used to solve the problem of segmentation at the level of letters.

Figure 1. Combining several letters into one connectedness component.

Figure 2. Disintegration of letter images into unrelated components due to poor scan quality.
We believe that there is not enough information in the recognition system to make a final decision on the passage of the boundary of letters at such an early stage of processing. Therefore, the task of the segmentation module at the level of letters in the developed algorithm is to find the possible boundaries of the characters inside the letter, and the final decision on word splitting is made at the last stage of processing, taking into account the identification of individual image fragments as letters. An additional advantage of this approach is the ability to work with letter patterns consisting of several connectedness components without special handling of such cases.
The result of the segmentation module is a segmentation tree - a data structure, the organization of which reflects the structure of the text on the page. The highest level corresponds to the object page. It contains an array of objects describing strings. Each line in turn includes a set of word objects. Words are leaves of this tree. Information about possible places of word separation into letters is stored in a word, however, separate objects for letters are not distinguished. Each tree object stores information about the area occupied by the corresponding object in the image. This structure can easily be extended to support other levels of partitioning, for example, columns, tables.
Identified image fragments are fed to the input of the classifier, the output of which is the vector of the possibility of the image belonging to the class of a particular letter. The developed algorithm uses a composite architecture classifier organized in the form of a tree, the leaves of which are simple classifiers, and the internal nodes correspond to the operations of combining the results of the underlying levels (Fig. 3).

Figure 3. Classifier architecture.
The work of the simple classifier is carried out in two steps (Fig. 4). First, attributes are calculated from the original image. The value of each feature is a function of the brightness of a certain subset of image pixels. The result is a vector of values of attributes, which is fed to the input of the neural network. Each output of the network corresponds to one of the letters of the alphabet, and the resulting output value is considered as the level of ownership of the letter to a fuzzy set.

Figure 4. A simple classifier.
The task of the combination algorithm is to summarize information that comes in the form of input fuzzy sets and, on their basis, calculate the output fuzzy subset of the set of recognized characters. The operations of the theory of fuzzy sets (such as t-norms and s-norms), the choice of the most confident expert, are used as combination algorithms.
The result of the classifier is a fuzzy set, resulting from the combination at the highest level.
At the last stage, the decision is made on the most plausible variant of reading the word. For this purpose, the levels of the ability to read individual letters, inter-letter segmentation and the frequency of combinations of letters in Russian are used.
To assess the effectiveness of the developed algorithm, a comparison was made with two existing OCR systems. This is a free open-source system CuneiForm v12 and a commercial system ABBYY FineReader 10 Professional Edition.
Unfortunately, for evaluating the performance of recognition systems, character sets prepared by foreign experts, or kits collected by the authors and not published in the public domain are usually used. For example, when evaluating the performance of the ABBYY FineReader algorithms, the author used the CEDAR, NIST, CENPARMI databases as well as scanned EGE questionnaires. Since these databases contain English and / or handwritten characters, they cannot be used to assess the effectiveness of performing research and development work on the subject of “developing an algorithm for recognizing printed Cyrillic characters”.
The comparison was made on samples with a resolution of 96 dpi and 180 dpi. The comparison involved text consisting of 300 words in Arial 14pt and Times New Roman 14pt fonts. Text resolution of 96 dpi was created on the computer directly as a graphic file. For a test with a resolution of 180 dpi, the text was printed on a laser printer and then scanned with the specified resolution. A fragment of the text used is shown in Fig. five.

Figure 5. Fragment of the text used for testing recognition systems.
The comparison results for 96 dpi are presented in table 1.

Table 1. Results of text recognition with a resolution of 96 dpi.
Comparison results for text with a resolution of 180 dpi are presented in table 2.

Table 2. Text recognition results with a resolution of 180 dpi.
The best recognition results for 96 dpi can be explained by the fact that the current system configuration was trained in Times New Roman 14pt and Arial 14pt fonts with a resolution of 96 dpi. We can expect improved results for this text when simple classifiers are added to the system that are trained to recognize fonts of this size.
In total, out of 1,200 words, it was recognized:
• developed algorithm: 1180 words (98.33%);
• open source system CuneiForm: 597 words (49.75%);
• commercial system ABBYY FineReader: 1200 words (100%).
It is worth noting that at low resolution, the presence of a large number of noise Cuneiform does not cope with text recognition, while the proposed algorithm recognizes text as such.
In general, we can conclude that, although the proposed algorithm is inferior to the best commercial product of Abbyy in this class, it is able to recognize text of lower quality than the CuneiForm open source system is able to recognize.
List of used literature.
Kvasnikov V.P., Dzyubanenko A.V. Improving the visual quality of the digital image by element-by-element transformation // Aerospace Engineering and Technology 2009, 8, pp. 200-204
Arlazarov V.L., Kuratov P.A., Slavin O.A. Recognition of lines of printed texts // Sb. Proceedings of ISA RAS "Methods and means of working with documents." - M .: Editorial URSS, 2000. - p. 31-51.
Project of St. Petersburg State University Open source: recognition of text images [Electronic resource] - Access mode: ocr.apmath.spbu.ru
Bagrova I. A., Gritsay A. A., Sorokin S. V., Ponomarev S. A., Sytnik D. A. Selection of features for recognizing printed Cyrillic characters // Bulletin of Tver State University 2010, 28, p. 59-73
Approximate reasoning, Information Sciences, 8, 199-249; 9, 43-80.
Melin P., Urias J., Solano D., Soto M., Lopez M., Castillo O., Voice Recognition with Neural Networks, Type-2 Fuzzy Logic and Genetic Algorithms. Engineering Letters, 13: 2, 2006.
Panfilov S. A. Methods and software for modeling algorithms for controlling nonlinear dynamic systems based on soft calculations. Thesis for the degree of candidate of technical sciences. Tver, 2005.
The task of transferring information from paper to electronic media is relevant not only within the framework of the needs arising in workflow systems. Modern information technologies allow us to significantly simplify access to information resources accumulated by mankind, provided that they are converted to electronic form.
The easiest and fastest is scanning documents with scanners. The result of the work is a digital image of the document - a graphic file. More preferable, in comparison with graphic, is text representation of the information. This option allows you to significantly reduce the cost of storing and transferring information, and also allows you to implement all possible scenarios for the use and analysis of electronic documents. Therefore, the most interesting from a practical point of view is precisely the translation of paper media into a text electronic document.
The raster image of the document page is input to the recognition system. For the recognition algorithms to work, it is desirable that the incoming image is of the highest possible quality. If the image is noisy, unsharp, has low contrast, then this will complicate the task of recognition algorithms.
')
Therefore, prior to image processing by recognition algorithms, it is pre-processed to improve image quality. It includes filtering the image from noise, sharpening and contrasting the image, alignment and conversion to the format used by the system (in our case, an 8-bit image in grayscale).
The prepared image goes to the input of the segmentation module. The purpose of this module is to identify structural units of text - lines, words, and symbols. Selection of high-level fragments, such as lines and words, can be carried out on the basis of the analysis of gaps between dark areas.
Unfortunately, such an approach cannot be applied to isolate individual letters, because, due to the peculiarities of the style or distortion, images of neighboring letters can be combined into one connected component (Fig. 1) or vice versa — the image of one letter can decay into separate connected components ( Fig. 2). In many cases, complex heuristic algorithms are used to solve the problem of segmentation at the level of letters.
Figure 1. Combining several letters into one connectedness component.
Figure 2. Disintegration of letter images into unrelated components due to poor scan quality.
We believe that there is not enough information in the recognition system to make a final decision on the passage of the boundary of letters at such an early stage of processing. Therefore, the task of the segmentation module at the level of letters in the developed algorithm is to find the possible boundaries of the characters inside the letter, and the final decision on word splitting is made at the last stage of processing, taking into account the identification of individual image fragments as letters. An additional advantage of this approach is the ability to work with letter patterns consisting of several connectedness components without special handling of such cases.
The result of the segmentation module is a segmentation tree - a data structure, the organization of which reflects the structure of the text on the page. The highest level corresponds to the object page. It contains an array of objects describing strings. Each line in turn includes a set of word objects. Words are leaves of this tree. Information about possible places of word separation into letters is stored in a word, however, separate objects for letters are not distinguished. Each tree object stores information about the area occupied by the corresponding object in the image. This structure can easily be extended to support other levels of partitioning, for example, columns, tables.
Identified image fragments are fed to the input of the classifier, the output of which is the vector of the possibility of the image belonging to the class of a particular letter. The developed algorithm uses a composite architecture classifier organized in the form of a tree, the leaves of which are simple classifiers, and the internal nodes correspond to the operations of combining the results of the underlying levels (Fig. 3).
Figure 3. Classifier architecture.
The work of the simple classifier is carried out in two steps (Fig. 4). First, attributes are calculated from the original image. The value of each feature is a function of the brightness of a certain subset of image pixels. The result is a vector of values of attributes, which is fed to the input of the neural network. Each output of the network corresponds to one of the letters of the alphabet, and the resulting output value is considered as the level of ownership of the letter to a fuzzy set.
Figure 4. A simple classifier.
The task of the combination algorithm is to summarize information that comes in the form of input fuzzy sets and, on their basis, calculate the output fuzzy subset of the set of recognized characters. The operations of the theory of fuzzy sets (such as t-norms and s-norms), the choice of the most confident expert, are used as combination algorithms.
The result of the classifier is a fuzzy set, resulting from the combination at the highest level.
At the last stage, the decision is made on the most plausible variant of reading the word. For this purpose, the levels of the ability to read individual letters, inter-letter segmentation and the frequency of combinations of letters in Russian are used.
To assess the effectiveness of the developed algorithm, a comparison was made with two existing OCR systems. This is a free open-source system CuneiForm v12 and a commercial system ABBYY FineReader 10 Professional Edition.
Unfortunately, for evaluating the performance of recognition systems, character sets prepared by foreign experts, or kits collected by the authors and not published in the public domain are usually used. For example, when evaluating the performance of the ABBYY FineReader algorithms, the author used the CEDAR, NIST, CENPARMI databases as well as scanned EGE questionnaires. Since these databases contain English and / or handwritten characters, they cannot be used to assess the effectiveness of performing research and development work on the subject of “developing an algorithm for recognizing printed Cyrillic characters”.
The comparison was made on samples with a resolution of 96 dpi and 180 dpi. The comparison involved text consisting of 300 words in Arial 14pt and Times New Roman 14pt fonts. Text resolution of 96 dpi was created on the computer directly as a graphic file. For a test with a resolution of 180 dpi, the text was printed on a laser printer and then scanned with the specified resolution. A fragment of the text used is shown in Fig. five.
Figure 5. Fragment of the text used for testing recognition systems.
The comparison results for 96 dpi are presented in table 1.
Table 1. Results of text recognition with a resolution of 96 dpi.
Comparison results for text with a resolution of 180 dpi are presented in table 2.
Table 2. Text recognition results with a resolution of 180 dpi.
The best recognition results for 96 dpi can be explained by the fact that the current system configuration was trained in Times New Roman 14pt and Arial 14pt fonts with a resolution of 96 dpi. We can expect improved results for this text when simple classifiers are added to the system that are trained to recognize fonts of this size.
In total, out of 1,200 words, it was recognized:
• developed algorithm: 1180 words (98.33%);
• open source system CuneiForm: 597 words (49.75%);
• commercial system ABBYY FineReader: 1200 words (100%).
It is worth noting that at low resolution, the presence of a large number of noise Cuneiform does not cope with text recognition, while the proposed algorithm recognizes text as such.
In general, we can conclude that, although the proposed algorithm is inferior to the best commercial product of Abbyy in this class, it is able to recognize text of lower quality than the CuneiForm open source system is able to recognize.
List of used literature.
Kvasnikov V.P., Dzyubanenko A.V. Improving the visual quality of the digital image by element-by-element transformation // Aerospace Engineering and Technology 2009, 8, pp. 200-204
Arlazarov V.L., Kuratov P.A., Slavin O.A. Recognition of lines of printed texts // Sb. Proceedings of ISA RAS "Methods and means of working with documents." - M .: Editorial URSS, 2000. - p. 31-51.
Project of St. Petersburg State University Open source: recognition of text images [Electronic resource] - Access mode: ocr.apmath.spbu.ru
Bagrova I. A., Gritsay A. A., Sorokin S. V., Ponomarev S. A., Sytnik D. A. Selection of features for recognizing printed Cyrillic characters // Bulletin of Tver State University 2010, 28, p. 59-73
Approximate reasoning, Information Sciences, 8, 199-249; 9, 43-80.
Melin P., Urias J., Solano D., Soto M., Lopez M., Castillo O., Voice Recognition with Neural Networks, Type-2 Fuzzy Logic and Genetic Algorithms. Engineering Letters, 13: 2, 2006.
Panfilov S. A. Methods and software for modeling algorithms for controlling nonlinear dynamic systems based on soft calculations. Thesis for the degree of candidate of technical sciences. Tver, 2005.
Source: https://habr.com/ru/post/112442/
All Articles