Snapshots - "photo memory (disk;)"

It is always strange to imagine a time when something was not there. It is difficult today to imagine how we lived without personal computers, without the Internet, without torrents, mp3, or without electric copiers, in common parlance "xeroxes". Nevertheless, there have always been times when something familiar did not exist to us. It was also the case with the notion of "data snapshot". But first - what is a "snapshot"?
" Snapshot " (literally - "photo", "snapshot", hereinafter, we will understand this word specifically, without specifying "data snapshot") is a snapshot of the state of data in the storage system, or program, fixed for a certain moment of time. This may be the instantaneous state of the contents of a file, database, or file system (as a special case of a “database”).
As applied to storage systems, this term appeared along with the first NetApp storage systems and was, at that time, the first and main feature of them.
')
Earlier, I already talked about the internal WAFL file structure invented by NetApp founders for my product, and how it works. Those interested in technical details will refer to the beautiful author's publication, which is now translated into Russian . It is this, somewhat unusual, at first glance, according to the principles of operation, the file structure made it possible to implement the concept of snapshots - instant copies of the state of the data stored on the disks of such a system.
As I already told in the article about WAFL , the basic principle of its work is that once the data recorded on the disk, in the future, does not change. Data (for example, a file) can be either recorded on WAFL (entirely) or erased (entirely). If it is necessary to change its contents, these changes are "added" to the free space of disk space, after which the file content pointer is moved to blocks with recorded changes (the old content block is marked as free, or is not marked if more than one file references it) or it is used in snapshot). Therefore, in order to preserve the current state of the data, with such an algorithm for the recording operation, all we need is to save the “root inode” at the given time.
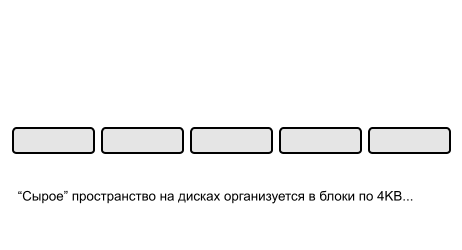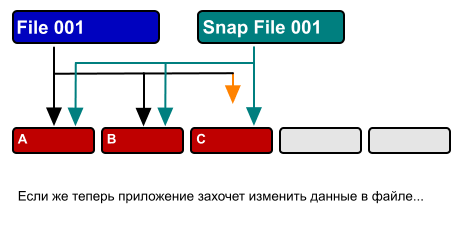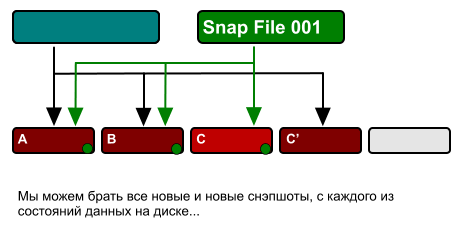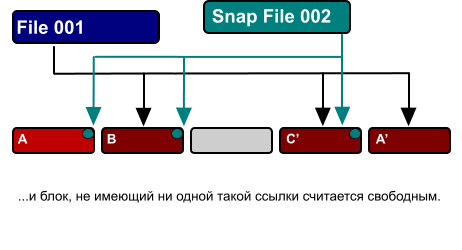
Inode, I remind you, this is a data block that defines the contents of the file. It can refer either directly to specific blocks, or, for large files, to intermediate inodes, forming a "tree" from the "root", the only volume on the entire file system, the so-called "root" inode.
Thus, having created a copy of exactly one block, the root inode of the given file system, we get, turning to it, instead of the current root, a “pseudo-file system” that stores all data unchanged (read-only) at the time when we copied this inode. After all, as you remember, once recorded data blocks of files are not changed in the future.
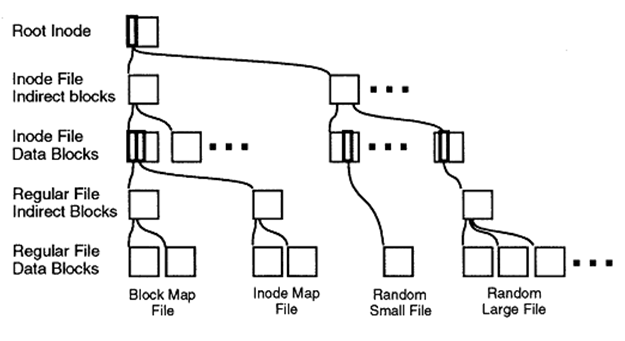
How does this look in practice?
To simplify the story, I will look at the NAS version of NetApp, although, as you know, the same way can work the same way as a SAN device .
Each volume on a NetApp storage system is a separate file system. Up to 254 snapshots of its state can be created on each file system, as described above.
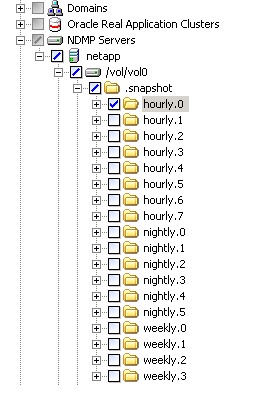
All created snapshots are automatically accessible via the /.snapshot (or / ~ snapshot ) directory in the volume root. When we go there, we will see the names of the created snapshots (they can either have their own name, for example " / lets_fix_this_small_bug ... oh_shit! .. ", being manually created, or, if created on a schedule, will be located in the subdirectories hourly.0 (1, 2.3 ...) , daily.0 (1,2,3) and so on.
Entering such a folder, we will see the entire contents of our volume, with all the files in it, all the files will be readable, and all the content that was in them at the time of the snapshot will be read.
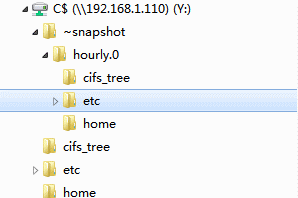
And it even looks a bit strange, at first glance.
Suppose you have a 1TB volume that holds a 750GB database file. For this volume, you create snapshots every hour on a schedule. When you enter /.snapshot, you will see the /hourly.0, /hourly.1 , and so on subdirectories in it , each of which will contain a “ 750GB file”. In this case, on the actual volume, with a capacity of 1TB, on which these 24 (every hour) copies of the base of 750 gigabytes each are located, there will still be 200 gigabytes of free space.
At the same time, we can copy any of these 24 “files” to a backup copy on external storage, mount it as an independent read-only and use (read) this data, as if it were a real database, recover data from it, copying it to a place of "active", for example, in the case of "everything is broken, it is necessary to roll back an hour ago," and so on.
Where is it all stored?
The fact is that all these “files” are simply links to the same blocks of unchanged data. The disk space is occupied only by changes, between the snapshots taken. Suppose that in 24 hours we replaced 50 gigabyte blocks in this database. Then the occupied space on the disks, in the volume of 1TB, on which the 750GB base file resides, and the snapshots every hour, will be 1TB - 750GB file - 50GB of changes = 200GB free.
If the changes in an hour between two snapshots ( hourly.0 and hourly.1 ) turned out to be 1% of the base volume, then hourly.1 will occupy 7.5GB of disk space, indicating by its inodes the blocks that have been changed compared to the previous snapshot. All the other inodes will still refer to the old, unchanged blocks.
What is convenient to use snapshots?
I have already cited the simplest example. Suppose we, or our users, "all broke." This could be a database, or, let's say, an Excel file, in which, accidentally, the wrong data crashed, we managed to write it down, and then discovered it, and we must urgently restore it, "or they will kill us all." But we know that an hour (two, three, a day, a week, a month ago, it all depends on the frequency and regularity of the snapshots) the file we need was intact.
We (by the way, even the user himself can do this) simply go to the /.snapshots folder and pull out the file we need, by copying, the right time, hour, two, 24 hours, and so on back.
Or, if we have a special SnapRestore license, with one command from the console, we “roll back” the state of the volume to the right moment in time (which is convenient if you need to restore not a single single file, but the contents of the entire volume, in general).
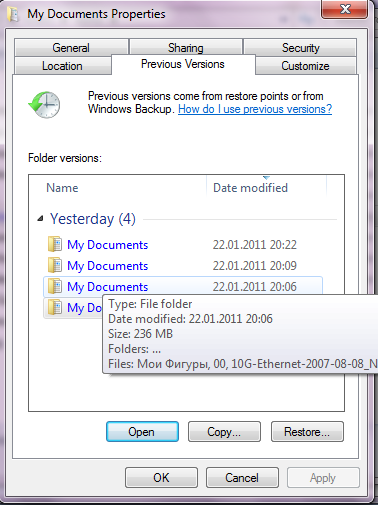
Thus, the snapshots are, for the user, a very real-time backup, available right there, on the same story. By the way, in case of using Windows XP or 7, you will see the files in the snapshot in the “Previous versions” panel of the file or folder properties, NetApp integrates into this Windows mechanism as a VSS-provider.
Now consider a more complex option. Suppose we exploit a large, responsible, mission-critical SQL database of an enterprise.
Of course, every evening, this database is backed up to tape to create a backup.
The base is large, and the backup is copied to tape for about an hour.
“Nothing foreshadowed trouble,” but once, in the middle of the working day, let's say at 3 o'clock in the afternoon, the base irreversibly deteriorates.
What actions does a sysadmin take to restore the base?
We read the backup as of the end of the last working day (it will be read, say, as much as it was written - an hour), and then we should “roll” the redo-log on it, from the moment of the backup creation, in the evening, and until the time before the failure, that is, until 3 o'clock the next day. This "roll forward" is often quite voluminous, and also takes some time, because operations in SQL do not occur instantaneously. Suppose that after 30 minutes, after the end of the backup reading, the base is restored to working condition at the time before the failure, and we are ready to continue working. Total - 1:30.
In the case of using snapshots, the case will proceed as follows. We also make a daily copy to tape to ensure storage safety, for example, in case of a complete failure of the storage system, but our storage is alive, only the data on it is damaged. We know that an hour ago the base was alive and well. We restore the database as of 2 pm, and since the snapshot is created and restored almost instantly, it takes not an hour, but only a few seconds, and redo-logs is rolled on it, but not from yesterday evening, as in the previous case, But in just one hour, from 2 o'clock, that is, the moment of creating a snapshot, before the time of the accident, at 3 o'clock in the afternoon. It also takes not half an hour, but only a few minutes.
Bottom line: after a few minutes , rather than an hour and a half, as usual, our base is again in working condition.
The obvious advantages of using snapshots have led to the fact that, today, almost all manufacturers of storage systems offer this or that implementation of snapshots as ideas for their systems.
However, as we remember, "not all
What is the fundamental difference between “real snapshots” (the name of Snapshots (tm) for storage systems is a registered trademark of NetApp) from all other “counterfeit copies”. ;)
The principal difference that allows snapshots to be implemented as described above by me is the WAFL device, which, as I have already said, does not allow changing the already recorded data. This model allows you to implement snapshots easily and simply. But things are worse if the record structure is traditional. At the same time, we will first have to allocate the reserved block space before using it, taking it away from the data beforehand, then, each time the block changes on the disk, copy its contents into a special reserved pool, then change its contents to its previous place, then change the metadata pointing to old content for snapshot.
This technology is called Copy-on-Write (COW), and is widely used in storage systems of other manufacturers, in their implementation of snapshots.
As you can see from the description above, even the presence of the included snapshot mechanism for a volume turns a single write operation for the storage system into three (reading the original content, writing the original content to a new location, writing the modified content to the old location).
The result is not long in coming. Using COW-snapshots dramatically affects the performance of the storage system using it. This is in stark contrast to NetApp systems, in which the snapshots do not affect the performance at all, because no copying takes place when they are written, all data remain in place.
( demonstration of performance results on the SPC-1 test )
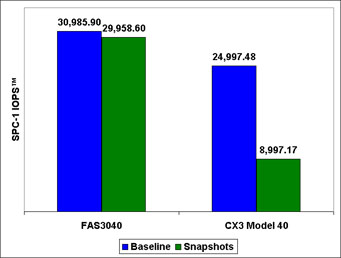
The consequence of such an unpleasant behavior when using COW-snapshots is the recommendation of vendors to reduce the use of such "wrong snapshots" to a minimum, or not to use them at all on primary-systems that place increased performance requirements.
However, NetApp systems do not suffer from this problem and do not impose any restrictions on the use of snapshots.
In addition, often (for the same reason), the total number of snapshots on such systems is limited to just a couple of dozen maximum, I note for contrast that on NetApp systems you can use up to 254 snapshots per volume, with the total number of volumes allowed by the system, equal to 500, reaches a theoretical maximum of 127 thousand.
This allows, when using the classic “rotation” of backups, to store in 254 snapshots backups of volume data up to and including a year.
Also important is the ability to create "truly instant" copies of the data, regardless of the size of the "copied" data. Although the base is 100MB, at least 100TB, the snapshot from it will always be created instantly. For example, we can create a “backup copy” not “in an hour”, but “in a second”, and then, without loading our task with a real combat base, slowly copy the contents of such a snapshot to the backup storage.
Practice shows that people who have tried the simplicity and ease of use of snapshots very soon simply cannot imagine life without them, considering this to be "taken for granted" by the possibility of any storage system. Try it and you.
Let me remind you that you can take a NetApp storage system for testing from any partner, a list of which can be viewed on the Russian page of the NetApp website.
www.netapp.com/ru/how-to-buy/resellers/distributor-ru.html
www.netapp.com/ru/how-to-buy/resellers/platinum-ru.html
www.netapp.com/ru/how-to-buy/resellers/gold-ru.html
PS: On the traditional “photo to attract attention” in the title - the back of the controller of the youngest NetApp model - FAS2020. The youngest, but nonetheless, with all the capabilities of NetApp repositories, including working with snapshots.
In the photo, from left to right, there are two FC 4Gb / s ports, a serial console port, an out-of-band port of the microcontroller of remote administration, and two Gigabit Ethernet ports.
PPS: You could also write this week about NetApp's 5th place in Fortune's list Best Places to Work, won Intel very proudly on 51st place (out of a hundred), but it seemed to me that all these joys of PR department Habra are not very interesting, so I mention this "creeping line" at the very end. Yes, fifth in the top 100 US employers, and fifteenth (above Google (30) and Apple (20), by the way) according to Glassdoor’s list, which assesses companies not “outside”, like Fortune, but from the inside, by anonymous votes of the workers themselves. "A trifle, but nice."
Source: https://habr.com/ru/post/112367/
All Articles