Point, point, comma: machine learning
How to teach the search engine to properly break the text into sentences? Make it so that it can recognize points that are not ends of sentences.
Our article on machine learning explains one of the techniques that are used in a search engine when there is a need to correctly split the text into sentences. The solution of such a problem is of fundamental importance, for example, when generating snippets by search engines or when building a database of contexts of usage. Now this technology is being integrated into the Index. Search. Mail. Ru. According to our observations, the accuracy of the method is at least 99%.
Read more about how this works in our article.
Problem and existing solution
When developing automatic word processing systems, the task of correctly splitting text into sentences often arises. Its solution is of fundamental importance, for example, when generating snippets by search engines or when building a database of contexts of usage.
In practice, you first need to find out whether the sign is the end of a sentence, then determine the places in the text where the divisor of the sentence was omitted, for example, by mistake. Implementing (and calculating) the second is much more difficult, but, fortunately, there is no urgent need for this, since the implied ends of sentences are less common than the explicit ones.
')
Ends of sentences may be indicated by dots, question marks and exclamations, paragraph end characters, dots and, in some cases, colons. The main problems are created by the dot symbol, since it is also used in abbreviations and literal notations - dates, ciphers, email addresses, web addresses, etc.
To determine whether a point in this context is the end of a sentence, various methods are used, the complexity of which depends on the requirements for the result. The most common are the methods that involve the use of regular expressions and tables of standard abbreviations, which in fairly simple cases give an acceptable result.
The main disadvantage of abbreviations tables is that they cannot be applied to cases of non-standard (author's) abbreviations. In addition, abbreviations may be at the end of a sentence, and some of them, for example, "etc.", "etc." often denote an explicit end of a sentence (by the way, this sentence is an exception).
Information about whether a sign is the end of a sentence is stored in context and displayed according to certain rules. To formulate them, based only on their own experience, is not so easy - especially given the fact that they need to be presented in the form of an algorithm.
But it is still possible to derive rules that allow to automatically distinguish the signs of the ends of sentences with more than 99% accuracy.
The basic rules are divided into two types - substitutions and combinations. Substitutions are set by regular expressions and check for specific simple context attributes such as, for example, “spaces to the right” or “one uppercase letter to the left”, etc.
Combinations are algebraic constructions that are constructed from substitutions, for example, “uppercase letter to the left” + “title to the right” (title is a word starting with a capital letter). Each of the basic rules, when applied to a specific context, returns the number of points awarded, usually 0, -1 or +1. The end result is calculated from the vector of points by means of a special classifier.
A pleasant feature of this approach is the fact that to make a decision, it is necessary to calculate the values of not all the rules, but only those that will be required by the classifier. In addition, based on the importance of the rules for the classifier, you can optimize them, seeking to improve quality and performance.
The training went on consistently, on documents of different types - web pages, artistic and formal texts. In total, about 10 thousand episodes were selected with the ratio of the number of signs-divisors of sentences to non-divisors, as 2 to 3. To get the final one. 99% accuracy required six stages of training.
For the first stage of training, data were prepared manually: it took about 1000 episodes to be considered. At each subsequent stage, episodes were added to the training list, where the classifier “was mistaken” or “doubted”.
As a result of the experiments, we found that the most significant rules include:
• "Type of delimiter", 3 rules. The point, question mark and exclamation mark are determined respectively;
• "Left / right spaces". Determine the presence of whitespace characters to the right and left of the separator;
• “Punctuation symbol on the right / left”;
• “Number to the right / left”;
• “Uppercase / lowercase letter right / left”;
• “Open / close bracket right / left”;
• “Standard Abbreviations”;
• “Unknown abbreviations of the general form xxx.-xx. xx. "etc.
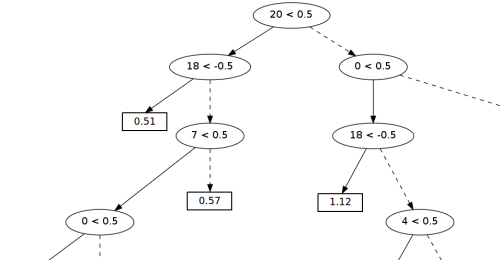
Figure 1. Fragment of the decision tree.
As a basis for the classifier, we used “decision trees”, which are widely used in machine learning. An example of a real “tree” from our classifier is shown in Figure 1 (we present a fragment, since the whole “tree” is too large).
In the "nodes" of the tree are the conditions for checking the rules. Record of the form “20 <0.5” means that if rule No. 20 scored less than 0.5 points, then you need to move to the left subtree, otherwise - to the right.
In the "leaves of the tree" stored estimates of the likelihood that the divisor is the end of the sentence (the higher the value, the higher the probability). In this example, the “tree” makes decisions based on the following rules:
• # 0 - separator is a point
• №4 - spaces on the right
• №7 - upper left letter
• # 18 - dot (+2 for the first point, +1 for the average, -1 for the last)
• No. 20 - title to the right (title - a word written with a capital letter).
Unfortunately, one “tree” cannot provide an acceptable quality of classification, therefore, as a classifier, we use a combination of several hundred relatively simple trees.
Each "tree" is built in such a way as to maximally compensate for the error of the work of the other "trees" of the classifier (this approach is known in the special literature under the name boosting). Additionally, to improve the quality of the classifier as a whole, we used the bootstrapping technique, where a random subset of the training set is used to build each "tree", changing from "tree" to "tree". The composite classifier obtained in this way shows significantly better quality of work than a single “tree”.
The table shows the estimates made by the classifier. The cut-off threshold (equal to 0.64) was chosen by the least squares method for the estimates obtained from the training set. The shift of the threshold is explained by the asymmetry of the training sample relative to the number of cases when the sign is a separator and when it is not.
And what about us?
Currently, machine learning technology on the correct breakdown of texts into sentences is embedded in the indexer of our search engine. This introduction promises to improve the quality of snippets in Search. Mail.Ru, and also will allow to correctly determine the context in which the word is used - which in turn will increase the relevance of search results.
Respectfully,
Search Team@Mail.Ru
Our article on machine learning explains one of the techniques that are used in a search engine when there is a need to correctly split the text into sentences. The solution of such a problem is of fundamental importance, for example, when generating snippets by search engines or when building a database of contexts of usage. Now this technology is being integrated into the Index. Search. Mail. Ru. According to our observations, the accuracy of the method is at least 99%.
Read more about how this works in our article.
Problem and existing solution
When developing automatic word processing systems, the task of correctly splitting text into sentences often arises. Its solution is of fundamental importance, for example, when generating snippets by search engines or when building a database of contexts of usage.In practice, you first need to find out whether the sign is the end of a sentence, then determine the places in the text where the divisor of the sentence was omitted, for example, by mistake. Implementing (and calculating) the second is much more difficult, but, fortunately, there is no urgent need for this, since the implied ends of sentences are less common than the explicit ones.
')
Ends of sentences may be indicated by dots, question marks and exclamations, paragraph end characters, dots and, in some cases, colons. The main problems are created by the dot symbol, since it is also used in abbreviations and literal notations - dates, ciphers, email addresses, web addresses, etc.
To determine whether a point in this context is the end of a sentence, various methods are used, the complexity of which depends on the requirements for the result. The most common are the methods that involve the use of regular expressions and tables of standard abbreviations, which in fairly simple cases give an acceptable result.
The main disadvantage of abbreviations tables is that they cannot be applied to cases of non-standard (author's) abbreviations. In addition, abbreviations may be at the end of a sentence, and some of them, for example, "etc.", "etc." often denote an explicit end of a sentence (by the way, this sentence is an exception).
Information about whether a sign is the end of a sentence is stored in context and displayed according to certain rules. To formulate them, based only on their own experience, is not so easy - especially given the fact that they need to be presented in the form of an algorithm.
But it is still possible to derive rules that allow to automatically distinguish the signs of the ends of sentences with more than 99% accuracy.
Our method
The method that we decided to use for Search. Mail. Ru is to create a small set of basic rules (about 40) and then automatically build a classifier based on the results of applying these rules.The basic rules are divided into two types - substitutions and combinations. Substitutions are set by regular expressions and check for specific simple context attributes such as, for example, “spaces to the right” or “one uppercase letter to the left”, etc.
Combinations are algebraic constructions that are constructed from substitutions, for example, “uppercase letter to the left” + “title to the right” (title is a word starting with a capital letter). Each of the basic rules, when applied to a specific context, returns the number of points awarded, usually 0, -1 or +1. The end result is calculated from the vector of points by means of a special classifier.
A pleasant feature of this approach is the fact that to make a decision, it is necessary to calculate the values of not all the rules, but only those that will be required by the classifier. In addition, based on the importance of the rules for the classifier, you can optimize them, seeking to improve quality and performance.
On learning: decision trees
The selection of basic rules was done manually, using a specially developed declarative language. To build a classifier, we used a machine learning algorithm based on “decision trees”.The training went on consistently, on documents of different types - web pages, artistic and formal texts. In total, about 10 thousand episodes were selected with the ratio of the number of signs-divisors of sentences to non-divisors, as 2 to 3. To get the final one. 99% accuracy required six stages of training.
For the first stage of training, data were prepared manually: it took about 1000 episodes to be considered. At each subsequent stage, episodes were added to the training list, where the classifier “was mistaken” or “doubted”.
The most important rules
As already mentioned, the significance of individual rules is determined automatically in the learning process. The higher the degree of correlation of the estimate obtained by a certain rule with the required answer, the higher this rule in the survey list, and the more often its execution will be checked.As a result of the experiments, we found that the most significant rules include:
• "Type of delimiter", 3 rules. The point, question mark and exclamation mark are determined respectively;
• "Left / right spaces". Determine the presence of whitespace characters to the right and left of the separator;
• “Punctuation symbol on the right / left”;
• “Number to the right / left”;
• “Uppercase / lowercase letter right / left”;
• “Open / close bracket right / left”;
• “Standard Abbreviations”;
• “Unknown abbreviations of the general form xxx.-xx. xx. "etc.
Algorithm for constructing a classifier
Figure 1. Fragment of the decision tree.
As a basis for the classifier, we used “decision trees”, which are widely used in machine learning. An example of a real “tree” from our classifier is shown in Figure 1 (we present a fragment, since the whole “tree” is too large).
In the "nodes" of the tree are the conditions for checking the rules. Record of the form “20 <0.5” means that if rule No. 20 scored less than 0.5 points, then you need to move to the left subtree, otherwise - to the right.
In the "leaves of the tree" stored estimates of the likelihood that the divisor is the end of the sentence (the higher the value, the higher the probability). In this example, the “tree” makes decisions based on the following rules:
• # 0 - separator is a point
• №4 - spaces on the right
• №7 - upper left letter
• # 18 - dot (+2 for the first point, +1 for the average, -1 for the last)
• No. 20 - title to the right (title - a word written with a capital letter).
Unfortunately, one “tree” cannot provide an acceptable quality of classification, therefore, as a classifier, we use a combination of several hundred relatively simple trees.
Each "tree" is built in such a way as to maximally compensate for the error of the work of the other "trees" of the classifier (this approach is known in the special literature under the name boosting). Additionally, to improve the quality of the classifier as a whole, we used the bootstrapping technique, where a random subset of the training set is used to build each "tree", changing from "tree" to "tree". The composite classifier obtained in this way shows significantly better quality of work than a single “tree”.
Example of outputting a marking program for a random set of phrases
Inside the sn tags are whole sentences:< sn > "". </ sn >< sn > There is no silver bullet. </ sn >< sn > . . - . </ sn >< sn > . . . </ sn >< sn > Unix 01. 01. 1970. </ sn >< sn > . . 11.06.1999. </ sn >< sn > v.pupkin@nowhere.ru.com, - nowhere.ru.com/pupkin.html - , . </ sn >
* This source code was highlighted with Source Code Highlighter .The table shows the estimates made by the classifier. The cut-off threshold (equal to 0.64) was chosen by the least squares method for the estimates obtained from the training set. The shift of the threshold is explained by the asymmetry of the training sample relative to the number of cases when the sign is a separator and when it is not.
| Decision: | Context (separating character is in the center): | Rating: |
| Yes | `that day was" good. " There is no silver bulle ' | 1,000 |
| Yes | `There is no silver bullet. A. S. Pushkin - a great p ' | 0.734 |
| not | `re is no silver bullet. A. S. Pushkin - the Great Russ' | -0,002 |
| not | `is no silver bullet. A. S. Pushkin - the great Russian ' | 0,003 |
| Yes | `in - the great Russian poet. F. M. Dostoevsky lived in ' | 0.972 |
| not | `- the great Russian poet. F. M. Dostoevsky lived in not ' | -0,002 |
| not | `great Russian poet. F. M. Dostoevsky lived in not himself | 0,003 |
| Yes | `simple time for Russia. The beginning of the Unix era | 1,000 |
| not | `m epoch Unix is 01. 01. 1970. Vasily Pupkin ' | 0.460 |
| not | `oh, Unix is considered 01. 01. 1970. Vasily Pupkin was' | 0.489 |
| Yes | `ix is considered 01. 01. 1970. Vasily Pupkin was appointed ' | 0,500 |
| not | `Lee Pupkin was appointed and. about. general manager ' | 0.184 |
| not | `Pupkin was appointed and. about. general manager 1 ' | 0.050 |
| not | `general manager 11.06.1999. His postal address is' | -0.001 |
| not | The oral manager 11.06.1999. His mailing address is' | -0.001 |
| Yes | The manager’s manager 11.06.1999. His mailing address is v.pup ' | 0,500 |
| not | `999. His mailing address is v.pupkin@nowhere.ru.com, whether | -0,055 |
| not | `th address v.pupkin@nowhere.ru.com, personal page ' | 0,000 |
| not | `address v.pupkin@nowhere.ru.com, personal page zde ' | 0.001 |
| not | `ka here - nowhere.ru.com/pupkin.html - now ' | 0,000 |
| not | `here - nowhere.ru.com/pupkin.html - now ' | -0.001 |
| not | `p: //nowhere.ru.com/pupkin.html - now everyone knows, ' | -0.001 |
| Yes | `Find out how to contact him. ' | 0.972 |
And what about us?
Currently, machine learning technology on the correct breakdown of texts into sentences is embedded in the indexer of our search engine. This introduction promises to improve the quality of snippets in Search. Mail.Ru, and also will allow to correctly determine the context in which the word is used - which in turn will increase the relevance of search results.extracurricular reading
For a more in-depth acquaintance with machine learning algorithms, we recommend the book T.Hastie, R.Tibshirani, JHFriedman “The elements of the statistical learning”, which is available online .Respectfully,
Search Team@Mail.Ru
Source: https://habr.com/ru/post/112142/
All Articles