Habr's favorites in PDF
All with the coming!
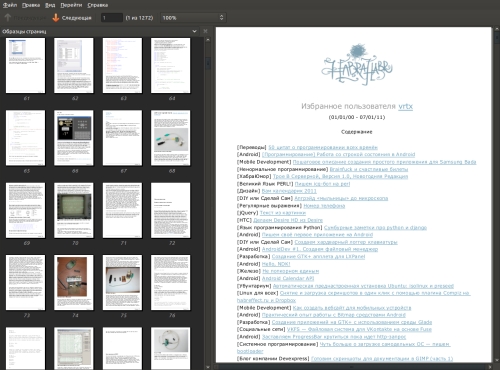
Since I like to organize and catalog everything, the idea of wrapping selected topics from Habr in PDF has long been turned around and sorted by dates.
Actually, some free time was allocated on holidays, I decided to carry out my plans and share with Habr
')
UPD:
- Fixed the error “too large on page” (more on github) Thanks to Bifidokk and StreetAngel
- Authors of topics made by reference
- Added ability to save favorites from specified blogs only
The script requires python-pisa
Work under windows unfortunately not tested, no nearby
Startup order:
We edit fav2pdf.py for your needs.
Run
The output will be approximately following
As a result, next to the script, we will get a file with the name of your nickname in pdf format
Features:
Unfortunately, the topics in the favorites are sorted by the date they were added there, and not by the date of publication, so I had to sort through all my favorites,
which, although it does not greatly affect the speed (reading at 256k is about 230 topics ~ for 3 min), but not pleasant.
Minuses:
So far I have not found the minuses anymore, but anyway, the ones that I mentioned met in my favorites, and this was not a lot of 230 topics + tested on several users.
Who is still interested, link to github
Instructions for running the script under Windows, thanks to desiderata :
PS At the end of the script, the All-In-One script gave an error in pisa_document.py ", line 229, in pisaDocument
However, the PDF file was successfully created and contains all the articles from the favorites.
PS
If a similar error occurs during the script, it is treated with the PIL patch:
Decision:
PS2
Not at all strong in regulars, if someone prompts more optimal expressions, I will be grateful.
Since I like to organize and catalog everything, the idea of wrapping selected topics from Habr in PDF has long been turned around and sorted by dates.
Actually, some free time was allocated on holidays, I decided to carry out my plans and share with Habr
')
UPD:
- Fixed the error “too large on page” (more on github) Thanks to Bifidokk and StreetAngel
- Authors of topics made by reference
- Added ability to save favorites from specified blogs only
The script requires python-pisa
Work under windows unfortunately not tested, no nearby
Startup order:
We edit fav2pdf.py for your needs.
user = 'vrtx' -
site = user + '.habrahabr.ru'
from_date = '1 2011' - ,
to_date = '' - ,Run
python fav2pdf.pyThe output will be approximately following
Processed page 1 of 25:
----------------------
1 Topic: ->50
2 Topic: Android->[] Android
3 Topic: Mobile Development-> Samsung Bada
4 Topic: ->Brainfuck
Topic: -> , 1.0, is locked!
----------------------
Prepare PDF...
As a result, next to the script, we will get a file with the name of your nickname in pdf format
Features:
- Main page with content
- The topic header leads to the topic in Habré
- Pages are pulled from the mobile version of the Habr
- The ability to limit the selection by dates, you can, for example, personal habrazh magazine :)
- Ability to pull out the favorites of any user
Unfortunately, the topics in the favorites are sorted by the date they were added there, and not by the date of publication, so I had to sort through all my favorites,
which, although it does not greatly affect the speed (reading at 256k is about 230 topics ~ for 3 min), but not pleasant.
Minuses:
- Does not read closed blogs (login required)
- I hope from the temporary disadvantages - glitches with the display of the contents of the pre tag (native syntax highlighting), rarely anyone using it from the authors, but still
- There may also be other flaws in the display due to limited CSS support in PISA.
- pisa-parser does not see links to Cyrillic images
- Did not do any "foolproof"
So far I have not found the minuses anymore, but anyway, the ones that I mentioned met in my favorites, and this was not a lot of 230 topics + tested on several users.
Who is still interested, link to github
Instructions for running the script under Windows, thanks to desiderata :
1. Python 2.7.1 x86 ( 3.0 , x64 _imaging)
2. pisa 3.0.31 :
Windows Installer,
C:\python27\python.exe setup.py install
ReportLab Toolkit 2.5, html5lib 0.9, PyPdf 1.13, PIL 1.1.7, setuptools 0.6c11, pisa 3.0.33.
3. C:\Python27\Lib\site-packages\PIL\Image.py .
4. fav2pdf.py .
5. C:\Python27\python.exe fav2pdf.py
6. PROFIT .PS At the end of the script, the All-In-One script gave an error in pisa_document.py ", line 229, in pisaDocument
However, the PDF file was successfully created and contains all the articles from the favorites.
PS
If a similar error occurs during the script, it is treated with the PIL patch:
File "/usr/lib/python2.6/dist-packages/PIL/Image.py", line 1498, in split
if self.im.bands == 1:
AttributeError: 'NoneType' object has no attribute 'bands'
Decision:
# HG changeset patch -- Bitbucket.org
# Project pil-2009-raclette
# URL bitbucket.org/effbot/pil-2009-raclette/overview
# User Fredrik Lundh <fredrik@effbot.org>
# Date 1272193085 -7200
# Node ID fb7ce579f5f96f7d9008f72ab03eef4f1c6db609
# Parent 45c2debe0fc3d9632372a15826b1b64a35ff43c4
Fixed split after open bug (regression in 1.1.7).
--- a/PIL/Image.py
+++ b/PIL/Image.py
@@ -1494,11 +1494,11 @@ class Image:
def split(self):
"Split image into bands"
+ self.load()
if self.im.bands == 1:
ims = [self.copy()]
else:
ims = []
- self.load()
for i in range(self.im.bands):
ims.append(self._new(self.im.getband(i)))
return tuple(ims)
PS2
Not at all strong in regulars, if someone prompts more optimal expressions, I will be grateful.
Source: https://habr.com/ru/post/111411/
All Articles