Multiplexed I / O
Preface
In this article, I would like to touch on important aspects of programming applications for the web, which should serve many users at the same time, which means that we will analyze all the annoying asynchronous I / O, multiplexing, etc.
The following objectives are pursued:
- Systematize the material in this area, discuss some inconsistencies in terminology
- Fully disassemble the foundation on which applications for serving many clients are built
- Develop a strategy for a future python application that should serve many clients
- Create a clear picture in your head (no wonder they say you understand - when you can explain)
What for?
Years of PHP programming have borne fruit - I never wondered what was going on behind the scenes. But when the projects began to slow down but surely, I decided that it was time to take up the mind and began to study the python (which I am doing successfully now). But since I am absolutely bored with all sorts of words like fork, socket, eventloop, multiprocessing, epoll, etc. I decided to dig deeper. What came out of it is up to you. However, some confusion is present. Confirmation of this can be found in the links [ 6 , 7 ]
int main ()
This article discusses I / O based on Linux OS version 2.6 and later. Since the material is largely focused on people like me (the device for heating water is optionally equipped with a sounder), you will have to disassemble a lot of the basics, so just skip the items you do not need.
')
Basic concepts
The file is a fundamental abstraction in Linux. Linux follows the “everything is a file” philosophy, which means most interaction is realized through reading and writing files. File operations are performed using a unique descriptor - a file descriptor or fd. Most of the Linux system programming is in working with file descriptors.
There are regular files (regular file) - this is what we are used to (the usual “file” in the usual sense) and special files - these are some objects that are represented as files. Linux supports 4 types of special files:
- Block device files
- Character I / O device files
- Named pipelines (named pipe or FIFO)
- Sockets
The latter is precisely the sphere of our interests, because sockets provide communication between two different processes that can be located on different computers (client-server). In fact, network programming and programming for the Internet is built on sockets.
In the first approximation, it is enough to consider only regular files and sockets.
I / O models
A total of 5 + 1 different I / O models are available on Unix-like systems. "Plus one" I will explain a little later, but for now let's consider each model in more detail.
Blocking I / O (blocking I / O)
By default, all input and output is performed in a blocking style. Consider a schematic depiction of processes occurring during blocking I / O.
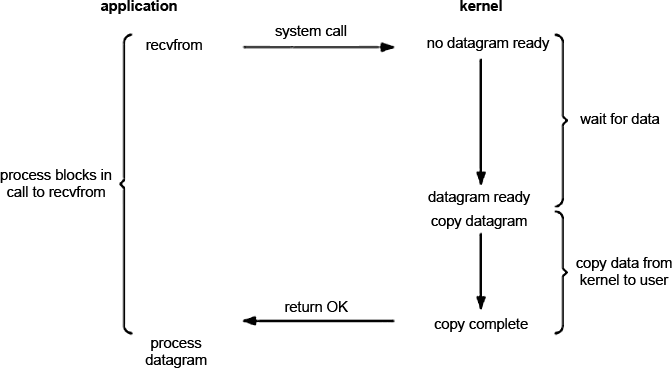
In this case, the process makes the recvfrom system call. As a result, the process is blocked (goes to sleep) until data arrives and the system call writes it to the application buffer.
After that, the system call ends (return OK) and we can process our data.
Obviously, this approach has a very big drawback - while we are waiting for data (and they can go for a very long time due to the quality of the connection, etc.), the process is asleep and does not respond to requests.
Nonblocking I / O (nonblocking I / O)
We can set a non-blocking mode when working with sockets, actually telling the kernel the following: “If the I / O that we want to do is impossible without immersing the process in a lock (sleep), then give me an error that you can’t do without blocking.” a schematic representation of the processes occurring in non-blocking I / O.
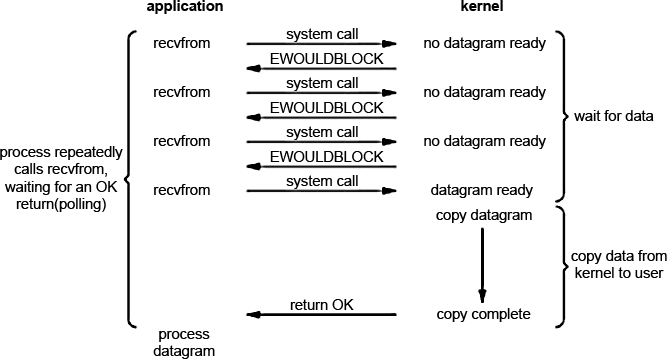
The first three times that we send a system call for reading do not return a result, because the kernel sees that there is no data and just returns the error EWOULDBLOCK.
The last system call succeeds because data is ready for reading. As a result, the kernel writes the data to the process buffer and it becomes available for processing.
On this basis, you can create a loop that constantly calls recvfrom (asks for data) for sockets opened in non-blocking mode. This mode is called polling. The application constantly polls the system kernel for data availability. I basically do not see restrictions to interrogate several sockets sequentially and respectively read from the first, which has data. This approach leads to large overheads (CPU time).
I / O multiplexing (multiplexing I / O)
In general, the word multiplexing translates as "seal." I think it can be successfully described by the motto of time management - “learn to do more”. When multiplexing I / O, we refer to one of the system call available in the OS (multiplexer such as select, poll, pselect, dev / poll, epoll (recommended for Linux), kqueue (BSD)) and block on it instead of blocking on actual I / O call. Schematically, the multiplexing process is represented in the image.
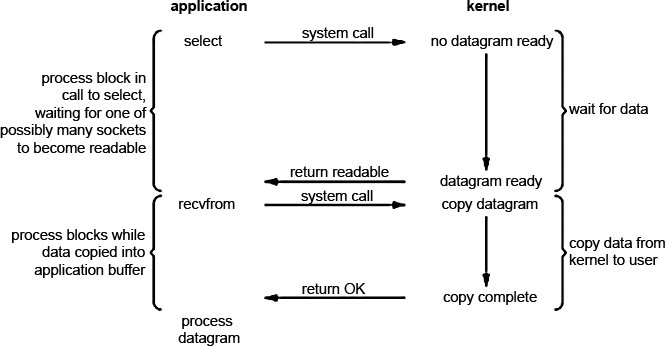
The application is blocked by calling select and waiting for the socket to become available for reading. Then the kernel returns us the status readable and you can retrieve data using recvfrom . At first glance, sheer disappointment. The same blocking, waiting, and 2 more system calls (select and recvfrom) - high overhead. But unlike the blocking method, select (and any other multiplexer) allows you to expect data not from one but from several file descriptors. It must be said that this is the most reasonable method for serving a multitude of clients, especially if resources are rather limited. Why is this so? Because multiplexer reduces downtime (sleep). I will try to explain the following image
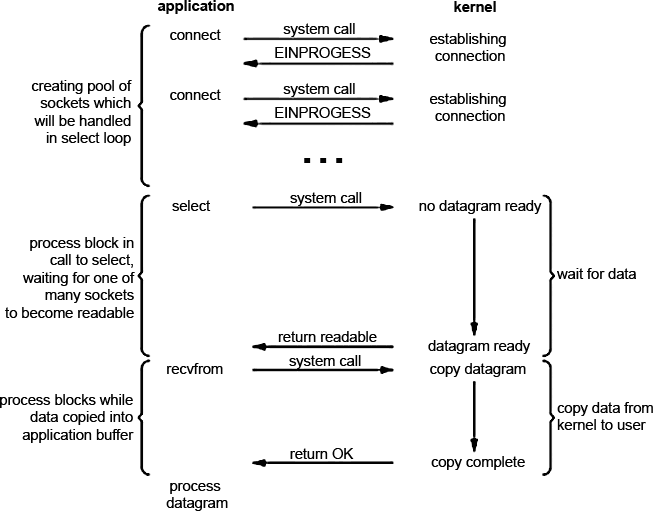
A pool of descriptors corresponding to the sockets is created. Even if during the connection we received the answer EINPROGRESS, it means that the connection is established, which does not bother us in any way, because during the test, the multiplexer will still be taken by the one that was first released.
And now attention! The most important thing!
Answer the question: Which event is more likely? For event A, that data will be ready for a particular socket or event B, that data will be ready for at least one socket? . Answer: B
In the case of multiplexing, ALL of the sockets are checked in our loop and the first one is taken. While we are working with him, others can also come along, that is, we reduce the time to simple (the first time we can wait a long time, but the other times are much less).
If we solve the problem in the usual way (with blocking), we will have to guess from which connection to read the first second, etc. those. we are 100% wrong and we will wait, and although we could not waste this time
I / O in threads / child processes (One file descr per thread or process)
Speaking at the beginning that there is a 5 + 1 method, there was meant just such an approach, when several threads or processes are used, in each of which a blocking I / O is performed. It is similar to I / O multiplexing, but it has several disadvantages. Everyone knows that Linux threads are quite expensive (from the TZ system commands), so using threads causes an increase in overhead. Moreover, if python is considered as a programming language, there is a GIL in it and, accordingly, only one thread can be executed within 1 process at any one time. Another option is to create child processes for handling I / O in a blocking style. But then it is necessary to think about the interaction between the processes (IPC - interprocess communication), which has some difficulties. In addition, if the total number of cores does not exceed one, then this approach has a dubious advantage. By the way, as far as I know, Apache works just approximately according to this scheme (MPM prefork or threads) servicing a client either in a thread or in a separate process.
Signal-driven I / O input
It is possible to use signals, forcing the kernel to send us a signal of the form SIGIO , when it becomes possible to read data without blocking (the handle is ready for reading). This approach is schematically represented in the image.
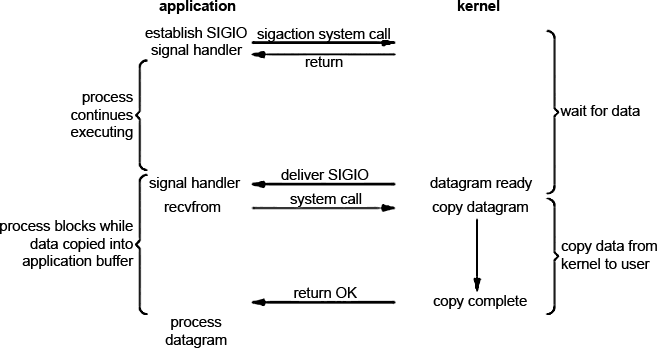
First, you need to set the socket parameters for working with signals and assign a signal handler (signal handler) using the sigaction system call. The result is returned instantly and the application is therefore not blocked. In fact, the core takes all the work, because it keeps track of when the data is ready and sends us a SIGIO signal, which calls the handler installed on it (callback function). Accordingly, the recvfrom call itself can be made either in the signal handler or in the main program thread. As far as I can tell, there is one problem - there can be only one signal for each process of this type. Those. we can only work with one fd at a time (although I'm not sure)
Asynchronous I / O (asyncronous I / O)
Asynchronous I / O is performed using special system calls. The basis is a simple idea - the kernel is given the command to start the operation and notify us (using signals, or something else) when the input / output operation is complete (including copying data to the process buffer). This is the main difference of this implementation from the implementation on the signals. Schematically, asynchronous I / O processes are represented in the image.
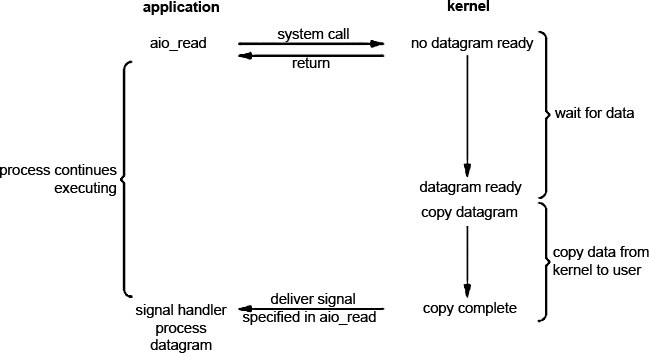
Make the aio_read system call and specify all the necessary parameters. The rest of the work does the core for us. Of course, there must be a mechanism that notifies the process that the I / O is complete. And then there are potentially many problems. But more about that another time.
In general, a lot of problems are associated with this term, examples of references have already been given. Often there is a confusion of concepts between asynchronous, non-blocking and multiplexed input output, apparently because the very concept of "asynchronous" can be interpreted in different ways. In my understanding, asynchronous means independent in time. Ie once started, he lives his life until it is fulfilled, and then we just get the result
On practice
In practice, there is a combination of different models based on the problem. Proceed as follows:
- It is not profitable to use a thread / process for every lock operation.
- Many clients in different threads / processes. Each thread / process uses a multiplexer.
- Many clients in different threads / processes. Asynchronous I / O is being used (aio)
- Just build the server into the kernel.
More details in The C10K problem
Total
I hope that now it will be at least a little clear about the differences in those things that are easily confused.
Well, yes, multiplexing taxis (until aio is finished, I think).
Studying the reference literature, I came to the conclusion that, unlike sockets, regular files cannot be translated into non-blocking mode. For them, it seems, aio is available that is considered here: Asynchronous I / O
Literature and links
- Robert Love “Linux. System Programming"
- W. Richard Stevens, Bill Fenner, Andrew M. Rudoff "Unix Network Programming Volume 1, Third Edition: The sockets networking API"
- Stephens R., Rago S. “Unix. Professional programming, 2nd edition »
- Beloved The C10K problem
- Asynchronous I / O on linux or welcome to hell
- Comparing Two High-Performance I / O Design Patterns
- Asynchronous vs non-blocking
- Blocking vs. Non-Blocking Sockets
Source: https://habr.com/ru/post/111357/
All Articles