Data storage by the magazine-structured storage algorithm
As a rule, if you are developing storage systems - such as a file system or database - one of the main problems is how to store data on a disk. When developing you must take care of a number of tasks. For example, about allocating space for objects that you intend to store. And also about indexing data, so that you don’t have to worry about what happens when you want to expand an existing object (for example, when adding data to a file), and about fragmentation that occurs when old objects are deleted, and new will take their place. All this leads to a lot of difficulties, and the solution to frequent bugs, or this is always inefficient.
The structured storage method takes care of all these issues. It appeared in the 1980s, but lately we have been seeing an increasing use of this method as a method of storage structure in database engines. In its initial use of the file system, it suffers from some flaws that prevent widespread adoption, but, as we will see, they are not so important for a DBMS, and the structured storage log leads to additional benefits for the database.
The basis for organizing a structured data storage log system, as the name implies, is a log — that is, everything happens by writing data sequentially. Whenever you have new data to write, instead of finding space for it on disk, you simply add it at the end of the log. Indexing data is carried out by processing metadata: updating metadata also occur in the log. This may seem inefficient, but on the disk the index structures are B-trees, as a rule, they are very wide, so the number of index nodes we need to update with each record are usually very small. Let's look at a simple example. We start with logs containing only one data item, as well as the index of the node that refers to it:
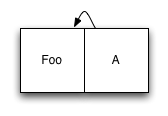
')
So far so good. Now suppose we want to add a second element. We add a new item at the end of the log, and an updated version of the pointer:
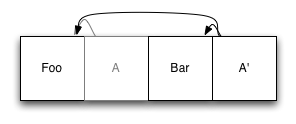
The original entry with the index (A) is still in the file, but it is no longer used: it has been replaced by the new entry A ', which refers to the original copy of Foo, as well as to the new entry Bar. When you want to read from our file system, we find the index of the root node, and use it as it would on any other system.
Quick root search. With a simple approach, one could simply look at the last block in the journal, since the last thing we always write is the root index. However, this is not ideal, as it is possible that at the time of reading the index, another process adds the middle of the magazine. We can avoid this by having a single block — say, at the beginning of the log — which contains a pointer to the current root node. Whenever we update the log, we will rewrite the first record to make sure it points to the new root node.
Next, let's see what happens when we update an item. Let's say we change foo:

We started recording a brand new copy of Foo at the end of the magazine. Then we again updated the node index (only in this example) and also recorded it at the end of the log. Once again, the old copy of Foo remains in the log, but the updated index simply does not refer to it anymore.
You probably understand that this system is not sustainable indefinitely. At some point, old data will just take up space. In the file system, it is considered as a ring buffer, overwriting old data. When this happens, the data that remains valid is simply added to the log again, as if it had just been written, and not the necessary old copies will be overwritten.
In the file system, one of the shortcomings that I mentioned earlier is not a good block in the header of the log. When we get complete information from the disk, the file system must spend more and more of its time collecting garbage, and constantly writing data to the log header. And when you reach 80%, your file system almost stops.
If you are using structured log storage for a database, this is not a problem! If we divide the database into several pieces of fixed length, then when we have to return some space, we can select a piece, rewrite it with new data, and delete the piece. The first segment in our example begins to look a little freer:
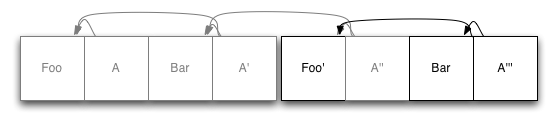
All we did here was take an existing copy of “Bar” and write it at the end of the magazine, then update the index of the node (s) as described above. After we have done this, the first log segment can be safely deleted.
This approach has several advantages over the file system approach. To begin with, we are not limited to the removal of old segments, if the intermediate segment is almost empty, we can simply collect garbage. This is especially useful for databases if there is some data that is stored for a long time, and which data is overwritten several times. We do not want to spend too much time rewriting unmodified data. We also have more flexibility when collecting garbage.
The benefits of this approach for the database do not end there. In order to ensure transaction consistency, databases typically use Write Ahead Log, or WAL. When a database is saved to disk, it first writes all changes to WAL, then to disk, and then updates the existing database files. This allows you to recover from the accident changes recorded in WAL. If we use log structured storage, the WAL database, so we only need to write data once. When restoring, just open the database, starting with the last recorded index, and search for any missing indexes.
Using our recovery scheme from the top, we can continue to optimize our recording. Instead of writing update index nodes for each record, we can cache them in memory, and only write them periodically to disk. Our recovery mechanism will take care of the recovery, as long as we suggest it distinguish between normal and incomplete records.
We can also gradually copy our databases with each new log segment to backup media.
The last main advantage of this system relates to parallelism and transaction semantics in databases. In order to ensure transaction consistency, most databases use complex lock systems to control which processes can update data and at what time. Depending on the level of consistency required, it can attract readers by taking out keys to make sure that the data does not change when they read it, and also write data keys for writing, can cause a significant decrease in performance even at relatively low numbers if enough simultaneous readings.
When it comes to writing data, we can use Optimistic Concurrency . In typical read-modify-write cycles, we first perform our read operations, as described above. Then, to record our changes, we lock the records for the database and make sure that none of the data we read is in the first phase. We can do it quickly, looking at the index, if the address of the data is the same as when we last read. If it is not recorded, we can proceed with the change. If everything is different, we just go back and start reading again.
The structured storage method takes care of all these issues. It appeared in the 1980s, but lately we have been seeing an increasing use of this method as a method of storage structure in database engines. In its initial use of the file system, it suffers from some flaws that prevent widespread adoption, but, as we will see, they are not so important for a DBMS, and the structured storage log leads to additional benefits for the database.
The basis for organizing a structured data storage log system, as the name implies, is a log — that is, everything happens by writing data sequentially. Whenever you have new data to write, instead of finding space for it on disk, you simply add it at the end of the log. Indexing data is carried out by processing metadata: updating metadata also occur in the log. This may seem inefficient, but on the disk the index structures are B-trees, as a rule, they are very wide, so the number of index nodes we need to update with each record are usually very small. Let's look at a simple example. We start with logs containing only one data item, as well as the index of the node that refers to it:
')
So far so good. Now suppose we want to add a second element. We add a new item at the end of the log, and an updated version of the pointer:
The original entry with the index (A) is still in the file, but it is no longer used: it has been replaced by the new entry A ', which refers to the original copy of Foo, as well as to the new entry Bar. When you want to read from our file system, we find the index of the root node, and use it as it would on any other system.
Quick root search. With a simple approach, one could simply look at the last block in the journal, since the last thing we always write is the root index. However, this is not ideal, as it is possible that at the time of reading the index, another process adds the middle of the magazine. We can avoid this by having a single block — say, at the beginning of the log — which contains a pointer to the current root node. Whenever we update the log, we will rewrite the first record to make sure it points to the new root node.
Next, let's see what happens when we update an item. Let's say we change foo:
We started recording a brand new copy of Foo at the end of the magazine. Then we again updated the node index (only in this example) and also recorded it at the end of the log. Once again, the old copy of Foo remains in the log, but the updated index simply does not refer to it anymore.
You probably understand that this system is not sustainable indefinitely. At some point, old data will just take up space. In the file system, it is considered as a ring buffer, overwriting old data. When this happens, the data that remains valid is simply added to the log again, as if it had just been written, and not the necessary old copies will be overwritten.
In the file system, one of the shortcomings that I mentioned earlier is not a good block in the header of the log. When we get complete information from the disk, the file system must spend more and more of its time collecting garbage, and constantly writing data to the log header. And when you reach 80%, your file system almost stops.
If you are using structured log storage for a database, this is not a problem! If we divide the database into several pieces of fixed length, then when we have to return some space, we can select a piece, rewrite it with new data, and delete the piece. The first segment in our example begins to look a little freer:
All we did here was take an existing copy of “Bar” and write it at the end of the magazine, then update the index of the node (s) as described above. After we have done this, the first log segment can be safely deleted.
This approach has several advantages over the file system approach. To begin with, we are not limited to the removal of old segments, if the intermediate segment is almost empty, we can simply collect garbage. This is especially useful for databases if there is some data that is stored for a long time, and which data is overwritten several times. We do not want to spend too much time rewriting unmodified data. We also have more flexibility when collecting garbage.
The benefits of this approach for the database do not end there. In order to ensure transaction consistency, databases typically use Write Ahead Log, or WAL. When a database is saved to disk, it first writes all changes to WAL, then to disk, and then updates the existing database files. This allows you to recover from the accident changes recorded in WAL. If we use log structured storage, the WAL database, so we only need to write data once. When restoring, just open the database, starting with the last recorded index, and search for any missing indexes.
Using our recovery scheme from the top, we can continue to optimize our recording. Instead of writing update index nodes for each record, we can cache them in memory, and only write them periodically to disk. Our recovery mechanism will take care of the recovery, as long as we suggest it distinguish between normal and incomplete records.
We can also gradually copy our databases with each new log segment to backup media.
The last main advantage of this system relates to parallelism and transaction semantics in databases. In order to ensure transaction consistency, most databases use complex lock systems to control which processes can update data and at what time. Depending on the level of consistency required, it can attract readers by taking out keys to make sure that the data does not change when they read it, and also write data keys for writing, can cause a significant decrease in performance even at relatively low numbers if enough simultaneous readings.
When it comes to writing data, we can use Optimistic Concurrency . In typical read-modify-write cycles, we first perform our read operations, as described above. Then, to record our changes, we lock the records for the database and make sure that none of the data we read is in the first phase. We can do it quickly, looking at the index, if the address of the data is the same as when we last read. If it is not recorded, we can proceed with the change. If everything is different, we just go back and start reading again.
Source: https://habr.com/ru/post/111287/
All Articles