Pro Video Compression - Introduction
Days go by, video quality requirements are constantly increasing. At the same time, the width of the channels and the capacity of the carriers could not keep up with this growth if the video compression algorithms had not been improved.
Then we will talk about some basic concepts of video compression. Some of them are somewhat outdated or described too simply, but at the same time they give a minimal idea of how everything works.
Search for motion vectors to compensate for motion (-: More on this ...
Almost everyone knows that any video is a set of static pictures that will replace each other in time. Further we will call this ordered set a video stream. They are different, so here it is extremely useful to conduct a small classification:
If we transmit video uncompressed, then no matter what is serious, we will not have enough communication channels or space to store data. Suppose we have an HD stream with characteristics:
1920x1080p, 24 fps, RGB24 and calculate the “cost” of such a stream.
1920 * 1080 * 24 * 24 = 1139 Megabit / s, and if we want to record a 90 minute film, then we need 90 * 60 * 1139 = 750 GB! Cool? This is despite the fact that a video of amazing quality with the same 1920x1080p on BluRay will occupy 20 GB, that is, the difference is almost 40 times!
Obviously, the video requires compression, especially given the fact that you can reduce the size of 40 or more times, while leaving the viewer in awe.
I tried to tell some basic concepts, not much loading with technical details. Next, I will talk about the structure of codecs, containers, etc. For those who are seriously interested in the compression and processing of video data there is a website compression.ru, supported by the native laboratory of computer graphics and multimedia VMK MSU.
To be continued…
Then we will talk about some basic concepts of video compression. Some of them are somewhat outdated or described too simply, but at the same time they give a minimal idea of how everything works.
Search for motion vectors to compensate for motion (-: More on this ...
Characteristics of the video stream
Almost everyone knows that any video is a set of static pictures that will replace each other in time. Further we will call this ordered set a video stream. They are different, so here it is extremely useful to conduct a small classification:
- Pixel format Pixel does not give us any information except its color. However, color perception is highly subjective and great efforts have been made to create color presentation and color rendering systems that would be acceptable to most people. So, the color that we see in the real world is quite complex in the frequency spectrum of light, which is extremely difficult to transmit in digital form, and even harder to display. However, it was noted that all three points in the spectrum can accurately approximate the displayed color to the present in the color perception metric of an ordinary person. These three points are red, green and blue. That is, with their linear combination we can cover most of the visible color spectrum. Therefore, the easiest way to represent a pixel is RGB24 , where exactly 8 bits of information are allocated to the Red, Green and Blue components. And so we can convey 256 gradations of each color and a total of 16,777,216 different shades. But in practice during storage such color representation is practically not used, not only because we spend as much as 3 bytes per pixel, but for other reasons, but more on that later (about YV12 ).
- Frame size . We have already taken and encoded all the pixels of the video stream and received a huge array of data, but it is inconvenient in operation. At first, everything is very simple, the frame is characterized by: width, height, dimensions of the visible part and format (more on that later). There will surely be a lot of familiar figures for the numbers: 640x480, 720x480, 720x576, 1280x720, 1920x1080 . Why? Yes, because they appear in different standards, for example, the resolution of 720x576 has most of the European DVDs. No, of course, you can make a 417x503 video, but I don’t think there’s anything good in it.
- Frame format . Even knowing the size of the frame, we can not imagine an array of pixels in a more convenient form, without having information about the way the frame is “wrapped”. In the simplest case, nothing tricky: take a row of pixels and write out in a row the bits of each encoded pixel and so line by line. That is, we write out as many lines as we have a height of as many pixels as we have width and everything in a row, in order. Such a sweep is called progressive . But maybe you tried to watch TV shows on your computer without proper adjustments and saw the “comb effect”, this is when the same object is in different positions with respect to even and odd lines. One can argue about the expediency of interlaced scanning for a very long time, but the fact is that it remains as a relic of the past from traditional television (for whom it is interesting to read about the device of a kinescope). About the methods of elimination ( deinterlacing ) of this unpleasant effect I will not speak now. From here come the magic symbols: 576i, 720p, 1080i, 1080p , where the number of lines (frame height) and the type of scanning are indicated.
- Frame rate . Some of the standard values are 23.976, 24, 25, and 29.97 frames per second. For example, 25 fps is used in European television, 29.97 in the US, and at a frequency of 24 fps is filmed. But where did the “strange” 23.976 and 29.97 come from? I will reveal the secret: 23.976 = 24 / 1.001, and 29.97 = 30 / 1.001, that is, the divider 1.001 is incorporated into the standard of the American television broadcasting NTSC. Accordingly, when a film is shown, there will be a very slight slowdown, which will not be noticeable to the viewer, but if this is a musical concert, the speed of the show is so critical that it is better to skip frames occasionally and again the viewer will not notice anything. Although I was a little deceived, “24” frames per second are never shown on American television, but “30” interlaced frames are shown (and that 59.94 frames per second, which corresponds to the frequency of their electrical network), but they are obtained by the “descent method” ( 3: 2 pulldown ). The essence of the method is that we have 2 full frames and 5 half-frames, and we fill in the first 3 half-frames from the first frame, and the remaining 2 from the second frame. That is, the sequence of the half-frames is as follows: [1 top, 1 bottom], [1 top, 2 bottom], [2 top, 3 bottom], [3 top, 3 bottom], [4 top, 4 bottom], etc. Where top - the top lines ( fields, fields ), and bottom bottom, that is, odd and even starting from the top, respectively. Thus, the film picture is quite watchable on TV, but twitching is noticeable on dynamic scenes. The frame rate may be variable, but many problems are connected with it, so I will not consider this case.
- Global characteristics . All the above concerns local properties, that is, those that are reflected during playback. But the duration of the video stream over time, the amount of data, the availability of additional information, dependencies, etc. For example: a video stream may contain one stream corresponding to the left eye, and another stream will in some way store information about the difference between the flow of the right eye from the left eye. So you can transmit stereo video or popularly known “3D”.
Why do I need to compress video?
If we transmit video uncompressed, then no matter what is serious, we will not have enough communication channels or space to store data. Suppose we have an HD stream with characteristics:
1920x1080p, 24 fps, RGB24 and calculate the “cost” of such a stream.
1920 * 1080 * 24 * 24 = 1139 Megabit / s, and if we want to record a 90 minute film, then we need 90 * 60 * 1139 = 750 GB! Cool? This is despite the fact that a video of amazing quality with the same 1920x1080p on BluRay will occupy 20 GB, that is, the difference is almost 40 times!
Obviously, the video requires compression, especially given the fact that you can reduce the size of 40 or more times, while leaving the viewer in awe.
What can you save?
- Color coding . Surely many people know that once upon a time television was black and white, but today's television is entirely in color. But a black and white TV can still show programs. The fact is that in the television signal the brightness is coded separately from the color components and is presented in the YUV format (for more details, see Wikipedia). Where Y component is brightness, and U and V are color components, and all this is calculated by the “magic” formula:
Y = 0.299 * R + 0.587 * G + 0.114 * B
U = -0.14713 * R - 0.28886 * G + 0.436 * B
V = 0.615 * R - 0.51499 * G - 0.10001 * B
As can be seen, the transformation is linear and nondegenerate. Consequently, we can easily get back the values of R, G and B. Assume that under storage of Y, U and V we allocate 8 bits each, then there were 24 bits per pixel and that’s it. No savings. But the human eye is sensitive to brightness, but to color it is not very pretentious. Yes, and almost all images of colors replace each other less often. If we conditionally divide the image into Y, U, and V layers and leave the luminance layer unchanged, and reduce U and V layers by two times in height and two times in width and four times. If earlier 24 bits were spent on each pixel, now we spend 8 * 4 + 8 + 8 = 48 bits per 4 pixels, that is, roughly speaking, 12 bits per pixel (that is why this encoding format is called YV12 ). Due to the color thinning, we squeezed the flow twice without any special losses. For example, JPEG always performs a similar conversion, but compared to other possible artifacts, thinning the color does not bear any harm. - Image redundancy . I will not dwell here especially since there are no differences from image compression algorithms. The same JPEG compresses the image due to its local redundancy by the methods of discrete cosine transform (DCT) and quantization , which again can be read on wikipedia. I will only mention that the static image compression algorithm built into the codec should compress well even remotely resembling real images, you will soon find out why.
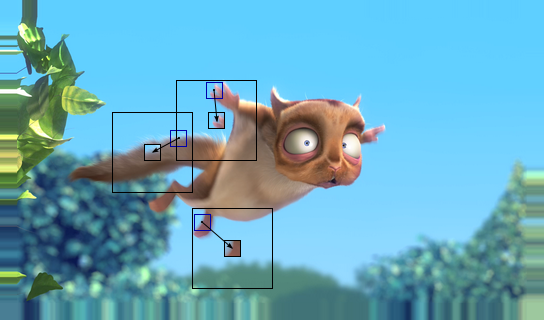
- Interframe difference . Surely, anyone looking at any video will notice that the images do not change dramatically, and the neighboring frames are quite similar. Of course, there are abrupt changes, but they usually occur when changing scenes. And here a problem arises: how should a computer represent all the variety of possible image transformations? The motion compensation algorithm comes to the rescue. About him I wrote an article on wikipedia. In order not to make copy-paste, I will confine myself to the main points. The image is divided into blocks and in the neighborhood of each of them a similar block is searched for in another frame ( motion estimation ), this is how the field of motion vectors is obtained. And already at compensation ( motion compensation ) the motion vectors are taken into account, and an image as a whole similar to the original frame is created.
')
Difference before motion compensation
Difference between original and compensated frames
Here it is clearly seen that the initial interframe difference is much larger than the difference between the original and compensated frames. Given the amount of information when compressing images, we can save motion vectors almost for free. They did this and then squeezed the image of the compensated interframe difference with a static image compression algorithm. And since the second picture is a blatant mess, the image compression algorithm should work correctly with such things. Due to the large redundancy of such images, they compress very strongly. But if the codec compresses them too much, then the blockiness effect occurs. The old algorithms do not take into account the changes in the objects in brightness and that is why the blockiness of the president is visible on TV during camera flashes. - The organization of sequences of frames . First of all, the codec should be sensitive to scene changes. To determine this is quite simple, since the motion compensation will work in this case ugly. The frame of the beginning of the new scene is logical to keep “as it is”, since it does not look like anything previously encountered. Such frames are called reference frames ( I-frame ). And then there are frames to which motion compensation was applied, that is, they depend on the reference frame and from each other. It can be P-frame or B-frame . The former can only rely on the previous frames, and the latter can on the left and right neighbor. The I-frame and all its dependencies form a GOP (group of pictures). The advantages of using bi-frames are as follows: fast navigation (because previous bi-frames do not need to be decoded) and the fact that they have the smallest size among all movie frames, well, a little lower quality (but fast alternation with higher-quality frames makes it unobtrusive to the viewer).
- Output redundancy . Even after performing all the compression procedures, the flow of coefficients has redundancy. Further different lossless compression methods can be applied. In the H.264 codec, for example, there are two variants of CABAC and CAVLC that implement arithmetic compression with a powerful probabilistic model and implement Huffman with a simpler model. For unclear reasons, Apple prefers the latter option, although on good decoders the difference in performance is insignificant.
Instead of conclusion
I tried to tell some basic concepts, not much loading with technical details. Next, I will talk about the structure of codecs, containers, etc. For those who are seriously interested in the compression and processing of video data there is a website compression.ru, supported by the native laboratory of computer graphics and multimedia VMK MSU.
To be continued…
Source: https://habr.com/ru/post/111244/
All Articles