Features of the disks in the cloud
After creating a new disk, a desire to check its speed appears For example, linear.
Discouraging numbers, right? Moreover, if you repeat the experiment, the reading speed will drop, and the write speed will increase to the prescribed 60-150 MB / s.
The reason for this is in the copy-on-write mode of the block devices served by blktap in the Xen Cloud Platform.
')
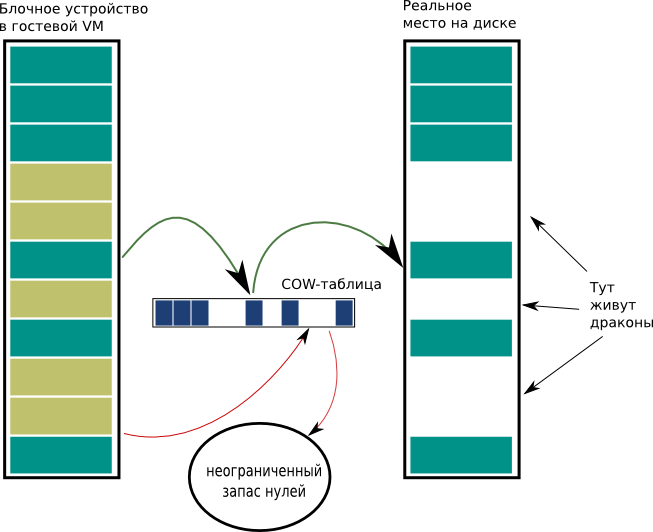
Despite the fact that disk space for virtual machines is reserved in full, until the first write to the block, there is nothing to read from it - instead, zeroes return with the “interface speed”. And during the first recording, the block is marked as used and recorded as a whole (even if 1k was recorded in it). The block is large - as much as 4M, so the kilobyte write results in a 4MB write. This leads to a characteristic slowdown during the first recording. Subsequent attempts to write only changed data - and this happens several orders of magnitude faster.
By the way, it is for this reason that mkfs works longer than we would like - when you first write an inode and superblocks, quite a few blocks are written to disk (more than the actual amount of recorded data).
There are two reasons: firstly, if we allocate a place for clients to the storage and another client’s disk used to be located at this place - can the new owner read the disk contents? The answer is no, because before the first record there is “emptiness” (there is no place to read), and at the first recording the block is overwritten entirely. Thus, this function reliably protects data on a remote disk from access by third parties.
Secondly, some customers create and delete large disks. Why write this way terabyte with hook?
After the initial recording, the speed is normalized, so in most cases no special measures need to be taken. If there are concerns about the performance of random access to a large "leaky" file (sparsed), then overwriting it with dd will normalize performance.
By the way, taking this opportunity, I want to remind you that we really need programmers. How quickly we have people for this job depends on how quickly we will have new features.
dd if = / dev / xvdb of = / dev / null bs = 1M count = 1000 1048576000 bytes (1.0 GB) copied, 1.29269 s, 811 MB / s dd if = / dev / zero of = / dev / xvdb bs = 1k count = 1000 10240000 bytes (10 MB) copied, 24.3481 s, 421 kB / s
Discouraging numbers, right? Moreover, if you repeat the experiment, the reading speed will drop, and the write speed will increase to the prescribed 60-150 MB / s.
The reason for this is in the copy-on-write mode of the block devices served by blktap in the Xen Cloud Platform.
')
Despite the fact that disk space for virtual machines is reserved in full, until the first write to the block, there is nothing to read from it - instead, zeroes return with the “interface speed”. And during the first recording, the block is marked as used and recorded as a whole (even if 1k was recorded in it). The block is large - as much as 4M, so the kilobyte write results in a 4MB write. This leads to a characteristic slowdown during the first recording. Subsequent attempts to write only changed data - and this happens several orders of magnitude faster.
By the way, it is for this reason that mkfs works longer than we would like - when you first write an inode and superblocks, quite a few blocks are written to disk (more than the actual amount of recorded data).
Why do you need it?
There are two reasons: firstly, if we allocate a place for clients to the storage and another client’s disk used to be located at this place - can the new owner read the disk contents? The answer is no, because before the first record there is “emptiness” (there is no place to read), and at the first recording the block is overwritten entirely. Thus, this function reliably protects data on a remote disk from access by third parties.
Secondly, some customers create and delete large disks. Why write this way terabyte with hook?
What to do?
After the initial recording, the speed is normalized, so in most cases no special measures need to be taken. If there are concerns about the performance of random access to a large "leaky" file (sparsed), then overwriting it with dd will normalize performance.
Offtopic
By the way, taking this opportunity, I want to remind you that we really need programmers. How quickly we have people for this job depends on how quickly we will have new features.
Source: https://habr.com/ru/post/111058/
All Articles