Multi-tenant Data Architecture
Hi Habr!

Once upon a time, there were computers of several floors in size, and several operators worked with some powerful computers. Then this miracle of technology could be reduced to a desktop size and put it in every home. Now again, “cloud computing” is considered an innovation, hmm ... it all comes down to several terminals and one powerful computer data center. Well, let's wait until Google’s data center is reduced to the size of a laptop ...
')
After the year 2000, the term acronym SaaS (software as a service) entered the lives of developers and architects, customers and many others related to IT. The essence of SaaS comes down to the fact that the Contractor develops the software, places it on the servers, maintains its performance, security, availability for customers (usually in the plural) and naturally pays for the server and other expenses.
The client pays for the use of services and does not think about the purchase of servers and their maintenance. This approach is cheaper for the Client and pays off for the Contractor (since it solves problems with licensing and piracy, and most importantly one service can be provided to several clients). However, the Client must trust the Contractor, since all his data are far away.
Naturally, such a decision forced to look for compromises in the field of data placement and sharing.
Since telling something without an example is quite problematic, consider the abstract problem.
For the Client, the convenience of such a system is obvious - employees of the company enter the system and see all the necessary data for more profitable and convenient work. The executor may not worry about the unauthorized use of the developed system, and most importantly, this system can be simultaneously used for several Clients, since the task is the same, and the database structure will also be identical. And here the decision tree forks, but more on that later.
Total: there are several customers who write and read to the database and know nothing about each other. It is necessary to ensure their isolation from each other and effective use of hardware and software.
The first solution that comes to mind to separate the data of different customers will store them in different databases (isolated approach). Alternatively, you can store all the data in one database by entering the additional field TenantID, by which to distinguish them (the general approach). In spite of all the binary nature of logic, there were no more solutions, but more. This fact is very convincingly presented in the picture borrowed from msdn:

This solution - the first thing that comes to mind is the simplest implementation of data sharing.
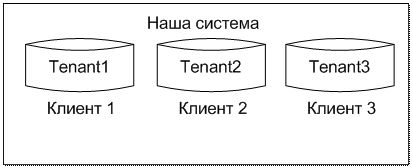
With this approach, the code is shared between clients (common UI files and business logic are used), and the data is logically (and possibly physically) separated from each other.
As a result, despite the high price, this is the most appropriate solution for customers whose main goal is security and who are willing to pay (for example, banks).
So, we decided to store everything in one database, how to do it without introducing an additional field TenantID? Store information from different customers in different tables. To implement this method will help us schema (schema) . In essence, schemes are “namespaces” that contain certain resources (tables for example) and for which certain permissions can be given.
The result, if customers are ready to live next door, then the option is quite effective, because will allow on one machine to settle more customers than in the previous version.
The third option is to store everything in a single database and in general tables. To implement this option, a prerequisite will be the introduction of an additional field TenantID (or CustomerID as you like) for sharing information between customers.
So, if you have a lot of clients, but few servers (money), and if you do not have all the hard drives in the mirror at the same time, then the approach is just for you.
Since the first option (different databases) can not afford all, it is most appropriate to use the option with a common database. But on this way we are waiting for a few unexpected surprises.

So, choose the cheapest option as a worker. Imagine that our bases do not fall, and hard drives are eternal. And now our system has been working successfully for a year and everyone is happy, gigabytes of data have accumulated, and suddenly everything starts to work slower and slower. The DBMS is not a black box, it must also be configured. The problem is trivial - the data is written in one table, in one file, and therefore on the hard drive fall behind each other. Now let's imagine how data is sampled for a single client: the hard drive head (yes, fans of SSD hard drives forgive me) slowly reads into the buffer everything, and records with the desired TenantID may not appear soon. Now imagine that we need to transfer the data of one client to the archive (by deleting them in our database).
Indices do you say? - I'll tell you dearly. In addition, even with indexes, the data will still lie in different parts of the disk.
There is a very elegant solution available in the enterprise versions of the DBMS called Partitioning (Sectioning), the essence of which can be seen in the figure:
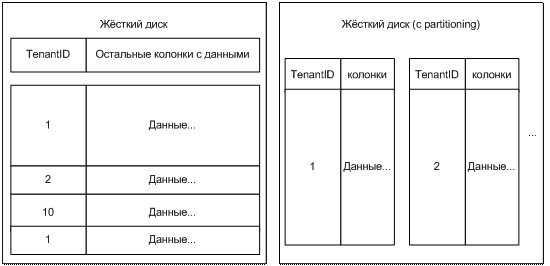
With partitoning, the data of one client are arranged sequentially, in a separate place from the rest. For simplicity, we can assume that the data of each client lies on a separate logical drive. This feature is supported at the DBMS level, so there is no need to write drivers and reinvent the wheel.
This article is not a translation, but of course there are English-speaking sources setting forth the essence of multi-tenant.
Some related links:
www.developer.com/design/article.php/3801931
msdn.microsoft.com/en-us/library/aa479069.aspx
msdn.microsoft.com/en-us/library/aa479086.aspx
Special thanks: DA Surkov and DMinsky (these are different Dmitriy)
Taking advantage of myofficial position , I want to congratulate everyone on the upcoming, the very last, most Friday Friday this year!
Once upon a time, there were computers of several floors in size, and several operators worked with some powerful computers. Then this miracle of technology could be reduced to a desktop size and put it in every home. Now again, “cloud computing” is considered an innovation, hmm ... it all comes down to several terminals and one powerful computer data center. Well, let's wait until Google’s data center is reduced to the size of a laptop ...
')
Introduction
After the year 2000, the term acronym SaaS (software as a service) entered the lives of developers and architects, customers and many others related to IT. The essence of SaaS comes down to the fact that the Contractor develops the software, places it on the servers, maintains its performance, security, availability for customers (usually in the plural) and naturally pays for the server and other expenses.
The client pays for the use of services and does not think about the purchase of servers and their maintenance. This approach is cheaper for the Client and pays off for the Contractor (since it solves problems with licensing and piracy, and most importantly one service can be provided to several clients). However, the Client must trust the Contractor, since all his data are far away.
Naturally, such a decision forced to look for compromises in the field of data placement and sharing.
Since telling something without an example is quite problematic, consider the abstract problem.
Task
- There are several large companies that need to follow the news to be able to compete;
- News - information scattered throughout the internet;
- As a service, a system that in a certain way collects the necessary information on the Internet and stores it in a database in order to show it to the client;
- After a time (six months or a year), the data will be transferred to the archive (deleted from the main database).
For the Client, the convenience of such a system is obvious - employees of the company enter the system and see all the necessary data for more profitable and convenient work. The executor may not worry about the unauthorized use of the developed system, and most importantly, this system can be simultaneously used for several Clients, since the task is the same, and the database structure will also be identical. And here the decision tree forks, but more on that later.
Total: there are several customers who write and read to the database and know nothing about each other. It is necessary to ensure their isolation from each other and effective use of hardware and software.
Solution: MULTI-TENANT
The first solution that comes to mind to separate the data of different customers will store them in different databases (isolated approach). Alternatively, you can store all the data in one database by entering the additional field TenantID, by which to distinguish them (the general approach). In spite of all the binary nature of logic, there were no more solutions, but more. This fact is very convincingly presented in the picture borrowed from msdn:
Different Databases
This solution - the first thing that comes to mind is the simplest implementation of data sharing.
With this approach, the code is shared between clients (common UI files and business logic are used), and the data is logically (and possibly physically) separated from each other.
Benefits:
- Simple extensibility (to add a client it is enough to create a new database and set up a configuration file);
- Simple scaling - it is possible to distribute databases of different clients to separate servers;
- Individuality - you can make individual settings for some clients (even place the base on another DBMS);
- Simple data backup - if something broke at one client, during the rollback of the database, others, it does not touch;
Disadvantages:
- Expensive. Very expensive. The number of databases supported by a single server is limited, which means that such a solution will require more hardware (as opposed to the method where everything is stored in one database), more hardware — more administrators, server area and electricity cost;
- Expensive. Again, expensive. When there are several databases on one server, the total amount of which is more RAM, data will be dumped into the paging file, and, therefore, the hard disk will be accessed, which is very slow. As a way out, buy more servers;
As a result, despite the high price, this is the most appropriate solution for customers whose main goal is security and who are willing to pay (for example, banks).
Common database, different schemes
So, we decided to store everything in one database, how to do it without introducing an additional field TenantID? Store information from different customers in different tables. To implement this method will help us schema (schema) . In essence, schemes are “namespaces” that contain certain resources (tables for example) and for which certain permissions can be given.
Benefits:
- Thanks to the schemes, the separation of access takes place at the DBMS level and does not require additional development from us (we save man-hours);
- Smaller databases - less hardware resources, again saved;
- Not bad extensibility - when adding a client, we create a new scheme based on the standard one, set up access and are ready. Despite the fact that all schemes are based on the standard, they may undergo some changes, because isolation is preserved, and therefore it is possible to edit columns, tables, etc.
Disadvantages:
- Nevertheless, the data is stored together, they are separated logically;
- The problem with backup and restore, because the database is the same, if the tables have fallen off for one client, a simple rollback of the database will return the data of all clients to the past, and this is unacceptable. It will require selective rollback and merging of old and new data, the procedure is a bit more complicated than just rolling back the entire database (I felt it on my own experience on one unfortunate day when two screws died almost simultaneously in the raid mirror. And there were backup and pieces of information on hand with dead screws ...);
The result, if customers are ready to live next door, then the option is quite effective, because will allow on one machine to settle more customers than in the previous version.
General database, general scheme
The third option is to store everything in a single database and in general tables. To implement this option, a prerequisite will be the introduction of an additional field TenantID (or CustomerID as you like) for sharing information between customers.
Benefits:
- Cheaply, in one set of tables we will have everything;
- Adding a customer - just creating a new record in the customer table;
Disadvantages:
- No flexibility, all clients use one set of tables and columns. The appearance of an individualized client - a sign of crutches and patches;
- Man-hours and nerves spent on developing their own rights-sharing system;
- With backup and recovery, it’s quite a problem, if in the previous approach we could delete the entire table and restore it, then we’ll have to search for the necessary records in one table and rewrite them, which will cost more in performance;
So, if you have a lot of clients, but few servers (money), and if you do not have all the hard drives in the mirror at the same time, then the approach is just for you.
Harsh reality
Since the first option (different databases) can not afford all, it is most appropriate to use the option with a common database. But on this way we are waiting for a few unexpected surprises.
So, choose the cheapest option as a worker. Imagine that our bases do not fall, and hard drives are eternal. And now our system has been working successfully for a year and everyone is happy, gigabytes of data have accumulated, and suddenly everything starts to work slower and slower. The DBMS is not a black box, it must also be configured. The problem is trivial - the data is written in one table, in one file, and therefore on the hard drive fall behind each other. Now let's imagine how data is sampled for a single client: the hard drive head (yes, fans of SSD hard drives forgive me) slowly reads into the buffer everything, and records with the desired TenantID may not appear soon. Now imagine that we need to transfer the data of one client to the archive (by deleting them in our database).
Indices do you say? - I'll tell you dearly. In addition, even with indexes, the data will still lie in different parts of the disk.
There is a very elegant solution available in the enterprise versions of the DBMS called Partitioning (Sectioning), the essence of which can be seen in the figure:
With partitoning, the data of one client are arranged sequentially, in a separate place from the rest. For simplicity, we can assume that the data of each client lies on a separate logical drive. This feature is supported at the DBMS level, so there is no need to write drivers and reinvent the wheel.
P.S
This article is not a translation, but of course there are English-speaking sources setting forth the essence of multi-tenant.
Some related links:
www.developer.com/design/article.php/3801931
msdn.microsoft.com/en-us/library/aa479069.aspx
msdn.microsoft.com/en-us/library/aa479086.aspx
Special thanks: DA Surkov and DMinsky (these are different Dmitriy)
Post Postscript
Taking advantage of my
Source: https://habr.com/ru/post/110979/
All Articles