Grammar arithmetic or write a calculator on ANTLR
When the question arises of how to compute an arithmetic expression, then, probably, many people think from the reverse Polish notation. Therefore, in this topic, I would like to talk about how you can compile a grammar of an arithmetic expression and build on it a lexical and syntactical analyzer using ANTLR.
To begin, consider the necessary tools. We will need:
Anything that relates to ANTLR, that is, the first three points, can be downloaded from the official site http://www.antlr.org/download.html for free, that is, for nothing.
Now a few words, in fact, about ANTLR (turn to Wikipedia). ANTLR (Another Tool For Language Recognition - “Another Language Recognition Tool”) is a parser generator that allows you to automatically create a parser program (like a lexical analyzer) in one of the target programming languages (C ++, Java, C #, Python, Ruby) according to the description of LL (*) - grammar in a language close to the RBNF. The author of this project is Professor Terence Parr (Terence Parr) from the University of San Francisco. I must say that the project is open source and distributed under the BSD license.
As part of this topic, we will write a program in C #, which will read arithmetic expressions separated by a line break from the console, and then return the result of the calculations. As arithmetic operations will be supported: addition, subtraction, multiplication, division. For simplicity, all operations will be performed on integers. As a bonus, our calculator (let's call it a project) will support the work with variables and, accordingly, the assignment operation.
')
It's time to start ANTLRWorks and create a project with our grammar. When running, ANTLRWorks will ask what type of document we want to create. Select "ANTLR 3 Grammar (* .g)". In the window that appears, enter the name of the grammar (let's call it “Calc”), leave the type as default (“Combined Grammar”). This means that in one file we will have both the rules of the grammar of the lexical and the parser. To avoid further disagreement, let's call the lexical analyzer a lexer (Lexer), and a syntax parser - a parser (Parser). If in the drop-down list you look at other options, you will understand the entered notation. Let me remind you that the lexer from the stream of characters selects tokens (tokens): integers, identifiers, strings, etc., and the parser checks whether the lexemes are in the correct order in the stream of tokens. I also recommend checking the Identifier and Integer checkboxes so that our grammar already contains rules for identifiers and integers. The result should be the following:

Click the “Ok” button and get a grammar with two automatically added lexer rules. Let's analyze how the rules for the lexer are written using the example of the “INT” rule. The rule starts with a name (in this case, INT). Names for lexer rules must begin with a capital letter. After the name is the symbol ":", followed by the so-called alternatives . Alternatives are separated by the symbol "|" and must end with a ";".
We now look at the only alternative to the INT rule. Writing '0' .. '9' + in ANTLR means that INT is a sequence of digits with at least one digit in it. If instead of the character '+' stood, for example, the symbol of '*', then this would mean that the sequence of numbers may be empty. The ID rule is somewhat more complicated and means that the ID is a sequence of characters consisting of lowercase and uppercase Latin letters, numbers, underscores, and starting with a letter or underscore.
Well, now we will write independently the first rule for the parser or in a scientific axiom , that is, the rule with which the parser will start to check the flow of tokens. So:
As you can see, the rules for the parser do not differ in structure from the rules for the lexer, except that the name must begin with a lowercase letter. In this case, we tell the parser that the input stream of tokens is a non-empty sequence of statements. Since the parser is not clairvoyant, it needs to know what statement is. Tell him:
Those who have forgotten what alternatives are on this rule canlearn to remember what kind of beast it is. The alternative is simply one of the possible variants of the order of the tokens. That is, statement is either an expression (expr) ending in a newline (NEWLINE), or an assignment operation ending in a newline, or simply a newline. Yes, by the way, do not forget to add the NEWLINE rule to the lexer rules, which I recommend to place at the end of the grammar file:
Sign "?" means that the character '\ r' must be present in the sentence either once or not at all.
Now consider the rule in which two alternatives are combined into one:
In ANTLR, this means that expr is an arbitrary sequence of addends with arbitrary signs. For example, multExpression-multExpression + multExpression-multExpression-multExpression + multExpression.
I will not consider the remaining rules (besides, there are only two of them left), but simply bring them as they are:
If you write the rules to a grammar file as you read, you probably already noticed that for each rule ANTLRWorks draws a graph. Did you notice? Fine! Now I do not need to comment on every rule:
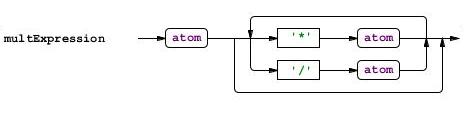
At this grammar can be finished. Is it really that simple?
Well, we have developed a grammar. It's time to generate the parser and lexer in C #. Since ANTLRWorks is more Java-oriented, it will be easier to generate code manually (personally for me) than with the help of a visual environment. But more on that later. First, let's add a couple of lines to the grammar file. Immediately after the first line of grammar names, you need to add the following:
These lines tell ANTLR that we want to get C # code, and also want the parser and lexer classes to be in the generated namespace. Everything, it is possible to generate the code. To do this, create a .bat file, in which we add the following contents:
Please note that in my case the .bat file is in the same directory as the antlr-3.2.jar and Calc.g files.
The "-o" key sets the path to the folder in which the generated files will be located. The pause is made solely for convenience - so that in case of errors, we can find out about it.
Run the .bat file and rather look into the Generated folder. There we see three files:
To start the parser, I created a console application in Visual Studio and added two received .cs files to it. For convenience, the namespace is called Generated, so as not to write any usings. It is important not to forget to add to the reference project on C # runtime distribution (Antlr3.Runtime.dll file in the DOT-NET-runtime-3-3.1.1.zip archive, downloaded from the ANTLR project site). Add the following code to the Main () function:
Done !!! Compile and run.

Note that the input ends when the end-of-file (EOF) character is encountered. To put this symbol in Windows, you must press CTRL + Z.
Everything is almost great. You probably noticed that no result is displayed on the screen. Disorder! To correct the annoying subtle work, we must again conjure up with grammar. Not closed ANTLRWorks yet?
The time has come for the most interesting. First, we will configure ANTLR a little more by adding the following fragment to the beginning of the file with
grammar:
I will explain. @members tells ANTLR that it is necessary to add a private member to the parser class (to store the values of variables) and, accordingly, the header says what namespaces need to be connected in order to use the Hashtable. Now you can add C # code to our grammar. Let's start with the statement statement:
The code is written in curly brackets {}. If the statement is the first alternative, then we print the value of the arithmetic expression on the screen, if the second one, we save the variable name and its value in the memory so that it can be obtained later. Everything is very simple here, but the question arises, where does the value of the expression $ expr.value come from? And it is taken from here:
Here, too, nothing complicated. We say ANTLR that the rule expr returns a value with the name value of type int. Note that in both the "$ expr.value" and "returns [int value]" entries, the value is not accidental. If we write:
and then we turn to $ expr.value, then ANTLR will generate an error.
I made some kind of free speech, saying that “the rule returns value”, but to say it briefly in a different way, without losing meaning, it is rather difficult in my opinion.
Another subtlety. Consider the statement rule, for example, the first alternative. In the code corresponding to this alternative, we address the expr rule directly ($ expr.value). But in the statement rule, this will not work, because there are two multExpression rules in it at once, that is, in order to distinguish them, you must give them names. In this case, it is me1 and me2. It seems to be all the details
discussed, now closer to the point.
In the expr rule, two alternatives are written into one through the '|' character. This is clearly seen in part 2 of this topic. Recall that expr is a clause of the type multExpression-multExpression + multExpression-multExpression-multExpression + multExpression. Now we will look at the code in curly brackets and see that the value of the first term is assigned to the returned value first, and then the values of the subsequent terms are added or subtracted depending on the operation. Similarly, the rule looks like
multExpression:
The last rule of the atom parser is left. There should be no problems with it:
If atom is an identifier (ID), then we return its value taken from memory. If atom is an integer, then simply return the number obtained from its string representation. Finally, if atom is an expression in brackets, then we simply return the value of the expression.
It remains to generate the parser and lexer using a .bat file. Even the function code Main () does not have to be changed. We run our calculator and play.
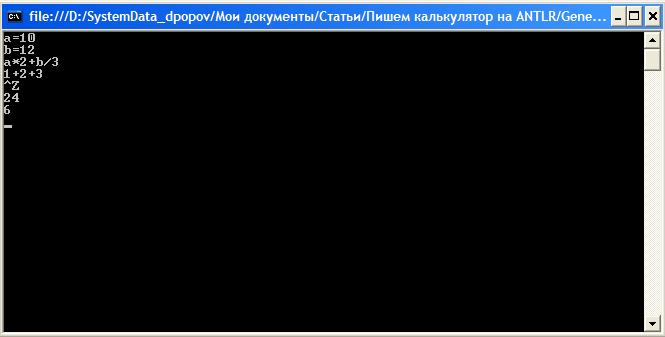
Interestingly, the generated parser can report syntax errors and moreover recover from them. To see this, try typing some expression, for example, with spaces (we didn’t do the processing of spaces, tabs and other things):

Parser, found errors, but nevertheless correctly calculated the result. You can even write something like “2 ++ 3” and get 5.
It's time to make a small summary. The solution that we got, it seems to me, is fully consistent with the task. The expression program reads? Yes. The result calculates? Yes. On this, perhaps, you can finish. I really hope, dear Habrelovelek, that you like this topic and you want to learn how to build parse trees with the help of ANTLR on grammar and use the same ANTLR to bypass them. If you have a dream to write your own programming language, then with ANTLR it has become much closer to implementation!
To begin, consider the necessary tools. We will need:
- ANTLRWorks - an environment for developing and debugging grammars
- ANTLR v3 - ANTLR itself (as of this writing, the latest version is 3.2)
- C # runtime distribution (Antlr3.Runtime.dll) - .NET library for working with generated analyzers
- Visual Studio - any other tool for compiling and debugging C # code
- Java runtime - since ANTLR and ANTLRWorks are written in Java
Anything that relates to ANTLR, that is, the first three points, can be downloaded from the official site http://www.antlr.org/download.html for free, that is, for nothing.
Now a few words, in fact, about ANTLR (turn to Wikipedia). ANTLR (Another Tool For Language Recognition - “Another Language Recognition Tool”) is a parser generator that allows you to automatically create a parser program (like a lexical analyzer) in one of the target programming languages (C ++, Java, C #, Python, Ruby) according to the description of LL (*) - grammar in a language close to the RBNF. The author of this project is Professor Terence Parr (Terence Parr) from the University of San Francisco. I must say that the project is open source and distributed under the BSD license.
1. Statement of the problem
As part of this topic, we will write a program in C #, which will read arithmetic expressions separated by a line break from the console, and then return the result of the calculations. As arithmetic operations will be supported: addition, subtraction, multiplication, division. For simplicity, all operations will be performed on integers. As a bonus, our calculator (let's call it a project) will support the work with variables and, accordingly, the assignment operation.
')
2. Grammar Development
It's time to start ANTLRWorks and create a project with our grammar. When running, ANTLRWorks will ask what type of document we want to create. Select "ANTLR 3 Grammar (* .g)". In the window that appears, enter the name of the grammar (let's call it “Calc”), leave the type as default (“Combined Grammar”). This means that in one file we will have both the rules of the grammar of the lexical and the parser. To avoid further disagreement, let's call the lexical analyzer a lexer (Lexer), and a syntax parser - a parser (Parser). If in the drop-down list you look at other options, you will understand the entered notation. Let me remind you that the lexer from the stream of characters selects tokens (tokens): integers, identifiers, strings, etc., and the parser checks whether the lexemes are in the correct order in the stream of tokens. I also recommend checking the Identifier and Integer checkboxes so that our grammar already contains rules for identifiers and integers. The result should be the following:
Click the “Ok” button and get a grammar with two automatically added lexer rules. Let's analyze how the rules for the lexer are written using the example of the “INT” rule. The rule starts with a name (in this case, INT). Names for lexer rules must begin with a capital letter. After the name is the symbol ":", followed by the so-called alternatives . Alternatives are separated by the symbol "|" and must end with a ";".
We now look at the only alternative to the INT rule. Writing '0' .. '9' + in ANTLR means that INT is a sequence of digits with at least one digit in it. If instead of the character '+' stood, for example, the symbol of '*', then this would mean that the sequence of numbers may be empty. The ID rule is somewhat more complicated and means that the ID is a sequence of characters consisting of lowercase and uppercase Latin letters, numbers, underscores, and starting with a letter or underscore.
Well, now we will write independently the first rule for the parser or in a scientific axiom , that is, the rule with which the parser will start to check the flow of tokens. So:
calc : statement + ;
As you can see, the rules for the parser do not differ in structure from the rules for the lexer, except that the name must begin with a lowercase letter. In this case, we tell the parser that the input stream of tokens is a non-empty sequence of statements. Since the parser is not clairvoyant, it needs to know what statement is. Tell him:
statement : expr NEWLINE | Id '=' expr NEWLINE | NEWLINE ;
Those who have forgotten what alternatives are on this rule can
NEWLINE: '\ r'? '\ n' ;
Sign "?" means that the character '\ r' must be present in the sentence either once or not at all.
Now consider the rule in which two alternatives are combined into one:
expr
: multExpression ('+' multExpression | '-' multExpression) *
;
In ANTLR, this means that expr is an arbitrary sequence of addends with arbitrary signs. For example, multExpression-multExpression + multExpression-multExpression-multExpression + multExpression.
I will not consider the remaining rules (besides, there are only two of them left), but simply bring them as they are:
multExpression
: a1 = atom ('*' a2 = atom | '/' a2 = atom) *
;
atom
: ID
| Int
| '(' expr ')'
;
If you write the rules to a grammar file as you read, you probably already noticed that for each rule ANTLRWorks draws a graph. Did you notice? Fine! Now I do not need to comment on every rule:
At this grammar can be finished. Is it really that simple?
3. Generation and launch of parser and lexer
Well, we have developed a grammar. It's time to generate the parser and lexer in C #. Since ANTLRWorks is more Java-oriented, it will be easier to generate code manually (personally for me) than with the help of a visual environment. But more on that later. First, let's add a couple of lines to the grammar file. Immediately after the first line of grammar names, you need to add the following:
options
{
language = CSharp2;
}
@parser :: namespace {Generated}
@lexer :: namespace {Generated}
These lines tell ANTLR that we want to get C # code, and also want the parser and lexer classes to be in the generated namespace. Everything, it is possible to generate the code. To do this, create a .bat file, in which we add the following contents:
java -jar antlr-3.2.jar -o Generated Calc.g pause
Please note that in my case the .bat file is in the same directory as the antlr-3.2.jar and Calc.g files.
The "-o" key sets the path to the folder in which the generated files will be located. The pause is made solely for convenience - so that in case of errors, we can find out about it.
Run the .bat file and rather look into the Generated folder. There we see three files:
- CalcLexer.cs - lexer code
- CalcParser.cs - parser code
- Calc.tokens - token list service file
To start the parser, I created a console application in Visual Studio and added two received .cs files to it. For convenience, the namespace is called Generated, so as not to write any usings. It is important not to forget to add to the reference project on C # runtime distribution (Antlr3.Runtime.dll file in the DOT-NET-runtime-3-3.1.1.zip archive, downloaded from the ANTLR project site). Add the following code to the Main () function:
try
{
// As an input stream of characters set the console input
ANTLRReaderStream input = new ANTLRReaderStream (Console.In);
// Set lexer to this stream
CalcLexer lexer = new CalcLexer (input);
// Create a stream of tokens based on a lexer
CommonTokenStream tokens = new CommonTokenStream (lexer);
// Create a parser
CalcParser parser = new CalcParser (tokens);
// And run the first grammar rule !!!
parser.calc ();
}
catch (Exception e)
{
Console.WriteLine (e.Message);
}
Console.ReadKey ();
Done !!! Compile and run.
Note that the input ends when the end-of-file (EOF) character is encountered. To put this symbol in Windows, you must press CTRL + Z.
Everything is almost great. You probably noticed that no result is displayed on the screen. Disorder! To correct the annoying subtle work, we must again conjure up with grammar. Not closed ANTLRWorks yet?
4. Adding Calculator Functionality to Grammar
The time has come for the most interesting. First, we will configure ANTLR a little more by adding the following fragment to the beginning of the file with
grammar:
@header {
using System;
using System.Collections;
}
@members {
Hashtable memory = new Hashtable ();
}
I will explain. @members tells ANTLR that it is necessary to add a private member to the parser class (to store the values of variables) and, accordingly, the header says what namespaces need to be connected in order to use the Hashtable. Now you can add C # code to our grammar. Let's start with the statement statement:
statement
: expr NEWLINE {Console.WriteLine ($ expr.value); }
| Id '=' expr NEWLINE {memory.Add ($ id.text, $ expr.value); }
| NEWLINE
;
The code is written in curly brackets {}. If the statement is the first alternative, then we print the value of the arithmetic expression on the screen, if the second one, we save the variable name and its value in the memory so that it can be obtained later. Everything is very simple here, but the question arises, where does the value of the expression $ expr.value come from? And it is taken from here:
expr returns [int value]
: me1 = multExpression {$ value = me1;}
('+' me2 = multExpression {$ value + = $ me2.value;}
| '-' me2 = multExpression {$ value - = $ me2.value;}) *
;
Here, too, nothing complicated. We say ANTLR that the rule expr returns a value with the name value of type int. Note that in both the "$ expr.value" and "returns [int value]" entries, the value is not accidental. If we write:
expr returns [int tratata] ... ;
and then we turn to $ expr.value, then ANTLR will generate an error.
I made some kind of free speech, saying that “the rule returns value”, but to say it briefly in a different way, without losing meaning, it is rather difficult in my opinion.
Another subtlety. Consider the statement rule, for example, the first alternative. In the code corresponding to this alternative, we address the expr rule directly ($ expr.value). But in the statement rule, this will not work, because there are two multExpression rules in it at once, that is, in order to distinguish them, you must give them names. In this case, it is me1 and me2. It seems to be all the details
discussed, now closer to the point.
In the expr rule, two alternatives are written into one through the '|' character. This is clearly seen in part 2 of this topic. Recall that expr is a clause of the type multExpression-multExpression + multExpression-multExpression-multExpression + multExpression. Now we will look at the code in curly brackets and see that the value of the first term is assigned to the returned value first, and then the values of the subsequent terms are added or subtracted depending on the operation. Similarly, the rule looks like
multExpression:
multExpression returns [int value]
: a1 = atom {$ value = $ a1.value;}
('*' a2 = atom {$ value * = $ a2.value;}
| '/' a2 = atom {$ value / = $ a2.value;}) *
;
The last rule of the atom parser is left. There should be no problems with it:
atom returns [int value]
: ID {$ value = (int) memory [$ ID.text];}
| Int {$ value = int.Parse ($ int.text);}
| '(' expr ')' {$ value = $ expr.value;}
;
If atom is an identifier (ID), then we return its value taken from memory. If atom is an integer, then simply return the number obtained from its string representation. Finally, if atom is an expression in brackets, then we simply return the value of the expression.
It remains to generate the parser and lexer using a .bat file. Even the function code Main () does not have to be changed. We run our calculator and play.
Interestingly, the generated parser can report syntax errors and moreover recover from them. To see this, try typing some expression, for example, with spaces (we didn’t do the processing of spaces, tabs and other things):
Parser, found errors, but nevertheless correctly calculated the result. You can even write something like “2 ++ 3” and get 5.
5. Conclusion
It's time to make a small summary. The solution that we got, it seems to me, is fully consistent with the task. The expression program reads? Yes. The result calculates? Yes. On this, perhaps, you can finish. I really hope, dear Habrelovelek, that you like this topic and you want to learn how to build parse trees with the help of ANTLR on grammar and use the same ANTLR to bypass them. If you have a dream to write your own programming language, then with ANTLR it has become much closer to implementation!
6. Recommended reading
- Definite ANTLR Reference, Terence Parr, 2007.
ISBN-10: 0-9787392-5-6, ISBN-13: 978-09787392-4-9 - Language Implementation Patterns, Terence Parr, 2010.
ISBN-10: 1-934356-45-X, ISBN-13: 978-1-934356-45-6
Source: https://habr.com/ru/post/110710/
All Articles