Data Deduplication - NetApp Approach

Data deduplication is a technology by which redundant data is detected and eliminated in disk storage. As a result, this reduces the amount of physical media for storing the same amount of data.
Data deduplication is one of the hottest topics in data storage systems of the last two or three years. After all, it is obvious that in the huge amount of data that modern storage systems now have to store, inevitably there are duplicates and identical data, by eliminating which it would be possible to significantly reduce storage volumes.
Perhaps the most successful were the implementation of deduplication technologies in the field of disk backup systems (for example, EMC Avamar, Data Domain), but NetApp was the first to announce the possibility of using deduplication for the so-called “primary storage”, that is, the main “combat” active data storage, as she was able to offer deduplication technology that practically does not reduce the productivity of his work.
Today I would like to tell you how and by what means it was possible, and why it is not yet possible with others.
So, deduplication is the elimination of duplicate data when it is stored on storage disks. How?
Under the common name "deduplication" can be hid at once a number of different implementations. The simplest of these is the implementation of deduplication at the “file” level. This is something that has long been implemented in "UNIX-like" file systems using the "links" mechanism. The same physical block chain can be addressed from different points in the file system. If, for example, the same standard library is used without modification by many different programs, then instead of copying the same file to dozens of places on the disk, we store one copy and replace the rest with a link. When an OS or an application accesses the file system for this file, the file system transparently redirects this reference to that single instance via a link.
But what to do if a new version of the library was released, which, although it differs by only a couple of hundred bytes of content, is already a whole different file? Such a mechanism will not work. It also does not work for “non-file” data, for example, in SAN storages operating on FC or iSCSI. It is for this reason that the link mechanisms, or “file deduplication”, are currently used in a relatively limited way. Now, if it were possible to link to part of the content via a link!
Such a mechanism began to be called sub-file or block deduplication. It is no longer implemented at the level of the standard UNIX-like file system, since links in it can only be addressed to files, and to files as a whole.
')
If you recall my article on the foundation of all NetApp storage systems, the WAFL file structure, you will see why NetApp was so interested in deduplication. After all, sub-file, block deduplication is absolutely naturally implemented in terms of WAFL, where “everything is links” to storage blocks.
Where can deduplication be applied?
I have already mentioned the backup storage, and in this area deduplication has been used for a relatively long time and successfully (often the same narrowly modified content, extensive files, user documents, including copies, for example, in different folders different users,). But there are other promising applications.
One of them is storing virtual machine data in a VMware ESX server virtualization environment, MS Hyper-V, Xen Server, and so on.
However, using deduplication methods that work well with backups will most often fail. No one wants to pay for space by a catastrophic drop in disk storage performance, as often happens.
What is suitable for backups is not suitable for primary storage.
It is necessary not only to eliminate duplicates, but also to do this in such a way that performance does not suffer.
What makes deduplication so effective on virtual infrastructure data?
Let me give you some of the most egregious example. Suppose you are deploying a server virtualization system in a VMware environment, and you have a dozen Windows or Linux servers in the ESX data servers, each performing its own task. All virtual machines of the same type, of course, are deployed from a previously prepared “template” containing the reference OS, with all the necessary patches, settings and service packs.
To create a new server, you simply copy this template and get a new, already configured and updated virtual machine consisting of individual settings file and a large “virtual disk” file containing all the files of the “guest OS” and its applications.
But at the same time, for a dozen of such virtual machines, you have a dozen almost completely identical virtual disks with folders / Windows / System32 (or / usr) inside, differing in only a few tens of kilobytes of individual settings in the registry and configuration files.
Despite the fact that, formally, they are almost identical in content, each virtual machine will use its own “C:” drive on its storage system for a dozen gigabytes. Multiplied by ten virtual machines, it already gives a weighty figure.
Even more egregious situations are possible in the case of VDI (Virtual Desktop Infrasructure), where the number of “virtual desktops” can amount to hundreds, and they all, as a rule, use the same OS.
The practice of using deduplication on these virtual disk files shows that the results of space savings often reach 75-90% of the initially occupied volume, "without deduplication".
This is quite tempting, without much risk and overhead, without sacrificing performance, to free up on a terabyte of storage 750-900 gigabytes previously occupied by images of virtual machines of volume.
Due to the fact that deduplication is carried out at the "sub-file" block level, different and not only identical files can be deduplicated, if only they have fragments of identical content within themselves within one 4KB block of the file system.
Deduplication can be carried out directly at the time of writing data to discs, it is called "online deduplication", or it can be implemented by a "postprocess" offline.
Rejecting the "online" deduplication, the one that occurs immediately upon receipt of data, Something we certainly lose.
For example, if we record strongly duplicated data, say 1TB, of which 900GB are zeros, we will first have to allocate a place for the recording, 1TB in size, fill it with our “zeroes by 90%”, and only then, during the deduplication process, 90% this space will become free.
However, "offline" deduplication gives us a lot of very significant advantages.
- We can use more efficient and accurate (read: slow and “processor intensive”) duplicate data detection algorithms. We do not need to make compromises in order not to overload the processor and not to reduce the performance of the storage system with deduplication.
- We can analyze and process significantly large amounts of data, since in the case of offline, we have available for analysis and use for deduplication all storage space, and not just the current, directly recorded portion of data.
- Finally, we can do deduplication when and where it is convenient for us.
Thus, it is not surprising that NetApp storage systems have chosen to use the “offline” method, because it allowed them to do deduplication with minimal impact on the actual disk performance of the system.
As far as I know, today NetApp is the only manufacturer of storage systems that use deduplication, which is not afraid to officially recommend its use for so-called primary data, that is, basic, operational data, and not just backups and archives.
How physically is the mechanism used in NetApp deduplication?
We often hear that the NetApp storage systems FC and SAS hard drives use a “non-standard sector size” of 520, instead of 512 bytes. “Non-standard” in quotes, because, oddly enough, it sounds, but the 520-byte sector (512b data + 8b CRC) should be considered “standard” today, since it is this value that is approved by the “T10 committee”, an organization engaged in development and approval of standards in the field of SCSI. Alas, quite a few storage systems have followed this new standard (except for NetApp, I only know EMC Clariion, as well as the highend-class systems, such as EMC Symmetrix and HDS USP), and using this sector format gives many correct and useful bonuses in operation. introducing additional protection against non-monitored RAID damage to the contents of a recorded sector. The probability of such errors is very low, but still non-zero.
However, in addition to this protection, NetApp uses such additional 8 bytes per sector to organize its data deduplication mechanism.
 (pic)
(pic)The data block in WAFL is 4096 bytes. A data block is something in file systems sometimes referred to as a “disk cluster”, a single addressable piece of data, not to be confused with a “high availability” computer cluster. This block, as you can see, consists of 8 sectors of 512 bytes.
As I said earlier, each of these 512 bytes of data is “given” at the system disk level another 8 bytes of CRC. So, for a 4KB WAFL block, we have 64 bytes of the CRC “checksum”.
The CRC has one big plus - it is very quickly and simply calculated. However, there is also a minus - a so-called “hash-collision” is possible, a situation when two blocks of different contents have the same hash result. If we are guided only by the results of the comparison of the hashes, then we may well take for identical (and one of them to permanently delete) two blocks of different contents. This probability is small, but it exists, and I’m sure you don’t want it to happen to your data.
How to deal with hash collision? The solution is to extend the hash and complicate the calculation algorithm. However, this option is very resource-intensive, especially with regard to the storage system processor. That is why CAS systems are Content-Addressable Storage, so-called “first-generation deduplication,” for example, EMC Centera, VERY slow to write, and only suitable for archival storage of less-changing documents.
But for online deduplicating, we most often simply have no other option.
However, “going offline” we get many new features at once, without being tied to the actual process of writing data to disk.
The deduplication process, working in the background, makes up the base of the hashes of all blocks of the disk volume, and, by sorting it, gets a list of “data duplication suspects”. Further, having received this list, and having sharply reduced the circle of “suspects”, and the volume of further work, the deduplication process goes through the disk, and over all potential duplicates it performs a trivial byte-by-step comparison operation. And only after making sure that the contents of the considered blocks coincide completely and unconditionally, one of them frees up at the file system level, and the other changes the inode pointer, which previously pointed to the now released block. The mechanism is somewhat similar to the mechanism of links in UNIX file systems, only applied not to files, but directly to blocks of file system data.
“What prevents such a mechanism to apply on a regular file system?” - you ask. If you read my previously published post, about the WAFL device , you can easily answer your question. Because on these file systems data blocks can be subsequently changed, overwritten. Imagine that we have two different files, A and B, each consisting of three data blocks (4096Kb each), it so happens that the average of these three blocks is the same for both files (the other two are different). We find this out, we use such “links”, and instead of a link to the middle block of file B, we establish a link to the second block of file A.
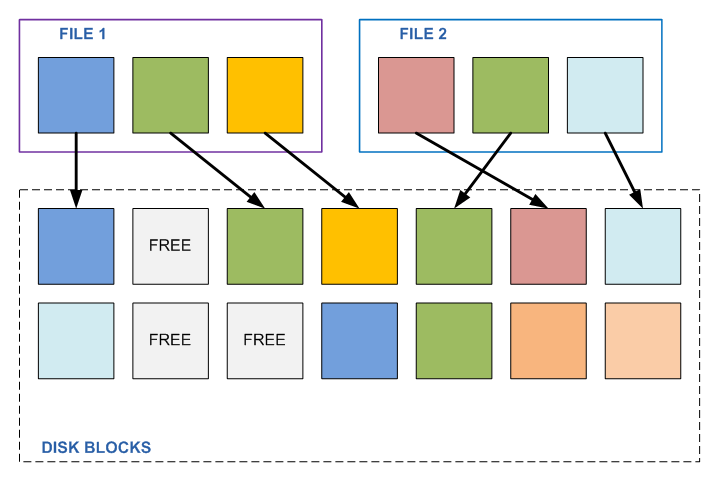
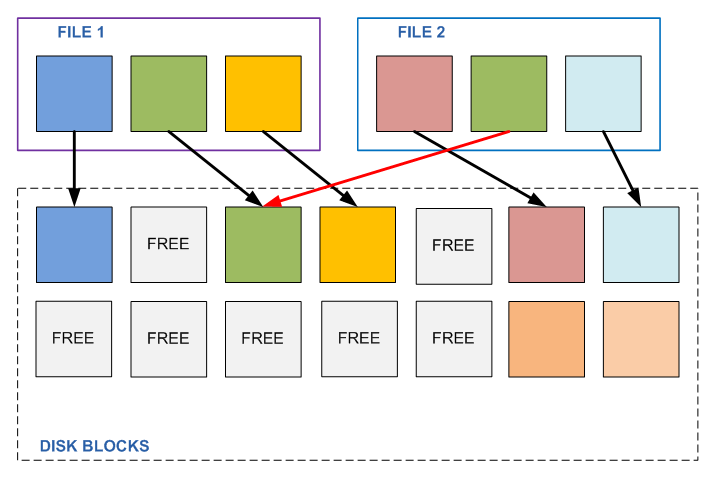
All is well, until any program needs to change this second block in any of these files. By changing the contents of one file, we automatically change the contents of the second file as well. Which, generally speaking, did not plan to change, it has its own content, and it belongs to a completely different task. It just so happened that in the middle it turned out to be the same piece as the other file (for example, trivially, a sequence of zeros), until this file was changed.
And what will happen if the block is changed? Nothing good. It turns out that the program, without knowing it, changed the contents of a completely extraneous file. Now imagine that there are a hundred of these files in different places, and if some of them are read at the same time?
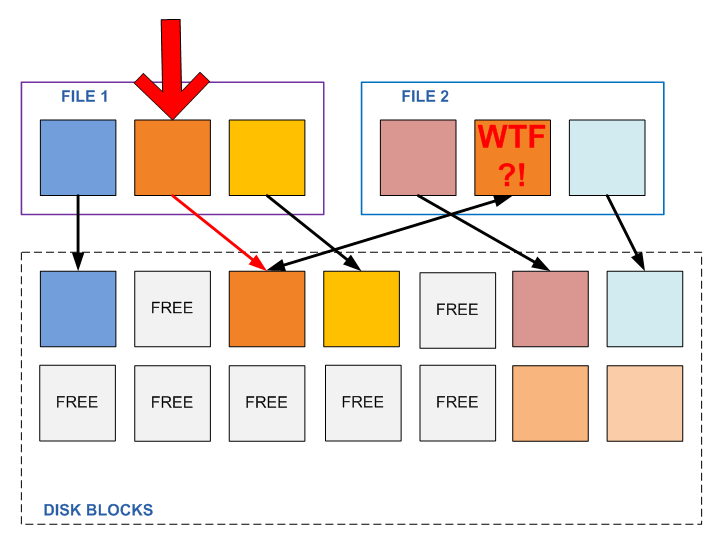
This could work for backups, which are usually written only once, and no longer change, but absolutely not suitable for active “primary data”, which can be changed arbitrarily.
As you remember from the article about the WAFL device , it is designed in such a way that the block once written is no longer overwritten and changed as long as the file exists, and as long as there is at least one link from the active file system or any snapshot to the block. And if you need to write a change to the file data, from the pool of free blocks, the place where the recording is made is allocated, then the pointer of the active file system is rearranged to this block (and the snapshot pointers remain on the previous blocks, so we have access to the new file contents simultaneously, "Active file system", and to its old contents, in a snapshot, if it was made.
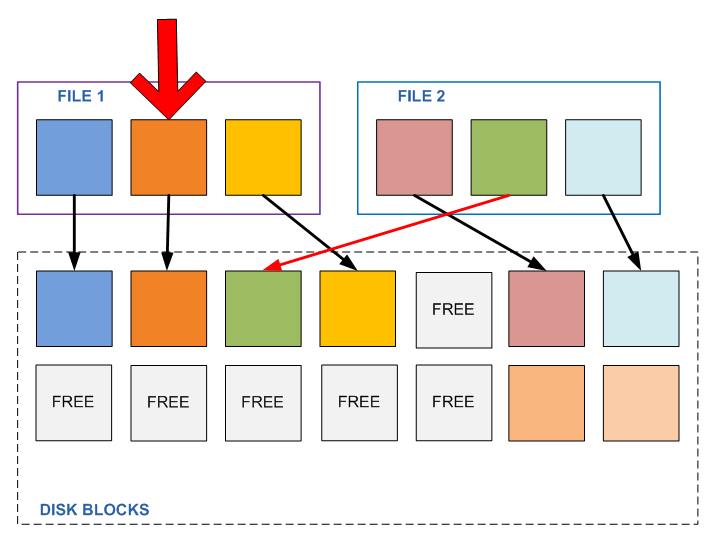
Such a storage device scheme is a guarantee that the situation of undesirable changes in the contents inside the file will not occur.
Once recorded, blocks are guaranteed not to change, and we can perform any operations we need over them, being sure of their continued immutability, for example, replacing blocks with duplicate content with a link to a block with a single copy of this “content”.
Probably the most frequently asked question about deduplication will be: How does deduplication affect the performance of the storage system using it?
First, it is necessary to take into account that, as mentioned above, deduplication, as a process, occurs “offline”, searching, finding and eliminating duplicate data blocks is a process with a background, the lowest priority, lower than that of workload processes. Thus, even with running deduplication (which can be assigned to the lowest load hours), the controller's processor resources to the detriment of the workload are not involved.
Secondly, although the deduplicated volumes of data have somewhat large amounts of associated metadata, which theoretically can increase the load on the system with large volumes of I / O, most users do not notice the effect of reducing the performance of deduplicated data at all. And in some cases, by reducing read volumes and better cache load (and NetApp cache knows and can properly use deduplicated data), even an increase in performance can be observed, for example, during times of the so-called 'boot storm', simultaneous loading of several dozen or even hundreds of virtual machines when the vast majority of data read from disks are the same OS files loaded into memory for many different machines.
However, nevertheless, NetApp gives a “conservative” recommendation in the documentation to expect a performance degradation of between 5-10% in the worst combination of stored data load, sizing and testing deduplication before making a decision about “output to production”. For admins, it will be nice to know that if any undesirable effects are detected, the data at any time can be painlessly “de-deduplicated” and “pumped out” to its original state.
Nevertheless, I repeat, numerous reviews of practical installations indicate the absence of any noticeable negative effect on performance at all.
Saving space on tasks that are well amenable to deduplication, for example, on the contents of virtual machine disks, shows a saving of space from 50% (half of the volume previously occupied on disks) to 75% (three quarters of the previously occupied volume is released).
By the way, deduplication, along with other NetApp technologies, such as RAID-DP, already described by Thin Provisioning, and snapshots, which was briefly in the WAFL article, allowed NetApp to announce an unprecedented 50% share of the industry saving two years ago. guarantee ", according to which NetApp ensures that the same amount of virtual machine data stored on any third-party storage system will fit on NetApp by half the amount of disks. And in case of non-fulfillment of this promise - to deliver free missing disks. However, as I know, nobody asked for the disks.
And finally, it should be said that the data deduplication function is available on any NetApp storage system for free, and usually a license to activate it comes by default with any storage system, and if you suddenly had a system sold without it, you can get it for free from your vendor .
Source: https://habr.com/ru/post/110482/
All Articles