Distribution of CPU resources between VMs in the Scalax cloud
Many of you are familiar with Oversan on articles in our blog on Habré, where we talked a lot about the architecture of DC Oversan-Mercury systems. We also talked about the architecture of the Scalaxi cloud, but mostly at specialized conferences , many of our reports and presentations are already outdated and have become irrelevant.
We think that many of the subsystems and architectural solutions in Scalaxi will be interesting to you and decided to talk about them. We decided to start with the topic of allocation of CPU resources because the issue of guaranteed computing resources is always heard: we regularly hear it from customers who are just interested, critics and bloggers.
To deal with the distribution of resources, it is necessary to consider the architecture of our virtualization system, at least in general terms, and to study in detail particulars. In this article, I will try to explain how the distribution of CPU computing power between client virtual machines works: how long a CPU goes to each VM and how it is achieved.
We in the Scalaxi team have become accustomed to some of the terms and definitions with which this text will be dazzled, so I will list them here:
Many other definitions and terms are described below, in the course of the material.
')
The easiest way to start the story about the CPU scheduler in Xen is with a short introductory description of the basic principles of the Xen hypervisor. Xen is a paravirtualization system that allows you to run several guest virtual machines on the same physical machine (host) that use Xen to access physical resources. At the same time, there are two possible ways to launch a guest VM - para-virtualization (PV), when a virtual machine starts up with a modified kernel and knows that it is running in Xen, or the machine starts up from any unmodified OS, and a special process is launched for it iron (qemu-dm), this mode is called HVM.
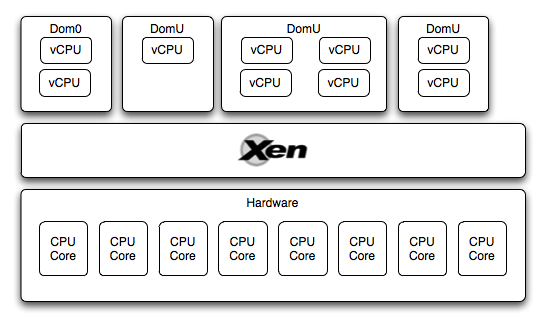
In Xen, guest virtual machines are also called domains. There is one privileged domain (Dom0) through which the hypervisor is managed, other guest machines work with I / O, and other virtual machines are managed. Guest virtual machines (DomU) can only be started after Dom0 has been loaded.

In general, the architecture of the Xen hypervisor has already been much discussed at habr, it is not worth being sprayed and disclosed in one article again.
So, it turns out that we have a hardware level at which the hypervisor runs, on top of which several guest virtual machines (Dom0 & DomU) are running. Each of these virtual machines has access to the CPU. How is it organized?
Each virtual machine works with so-called virtual CPUs (vCPU), this is a virtualized representation of a single core. The number of vCPUs is assigned to each virtual machine individually, either in its configuration or using the xm vcpu-set command. At the same time, the number of vCPU on each virtual machine can be at least one and not more than the number of host cores.
The task of the hypervisor is to properly distribute the time of the physical CPUs between the vCPUs, the solution to this problem is dealt with by a component called cpu scheduler. In the course of writing this article, I found information about the three existing schedulers and a description of a certain scheduler, which should replace the fact that the default is used in Xen now. But the purpose of this article is to tell how this works in the cloud, so I’ll dwell on only one thing: credit scheduler.
If you search, then on Habré you can find articles on this topic . Therefore, here we briefly summarize the basic principles of the scheduler and once again examine the algorithm of its work:
Now more about the algorithm:

After working one time slice (vCPU blocked, went to idle, on the contrary woke up), the CPU moves to the next vCPU in the queue. At the same time, consuming CPU time-slices, points are written off from the vCPU account, if the number of points becomes negative, the vCPU will receive the status over and take its place in the queue. If the queue runs out of under-vCPUs, the CPU will look for such vCPUs in queues of other cores. If there is no one there either - he will look for the next vCPU in himself and others with the over status, but with a cap that allows to issue vCPU for a little more time. This approach ensures that even vCPUs with sufficiently low weight will get processor time, if the CPU of the system and other virtual machines is idle, and also ensures that the VM gets its processor time.
In Skalaxi, we use Xen-hypervisor, user virtual machines run on VRT hosts. Our own development, CloudEngine, chooses which VRT host to run the machine on. The algorithm for choosing a suitable host is called an allocator, but if to explain it in a simple way, it chooses a suitable place for it on the basis of the number of VM slots so that the cloud is “properly” equipped: so that there is where to start other virtual machines and virtual the machines got more resources (in the paragraph above, we said that if the physical host is not 100% full, then the CPU will be allocated more than the guaranteed minimum).
SLES is launched in dom0, in which cap = 0 and weight = 16384. Next, client VMs sent by CloudEngine are launched in domU, and their weight is calculated based on one unit of weight per megabyte of RAM. Thus, it turns out that the total weight of domU-machines with a full load of VRT-host is 32768. That is, even if the host is loaded to capacity, dom0 will get enough computing resources if they are suddenly needed, and the host does not “choke” under the weight of domU-machines .
In fact, dom0 is almost always in idle, so we can assume that the CPU is distributed between client virtual machines with some minor losses on dom0. Frank Köhler, in his presentation, asserts that dom0 “eats up” up to 0.5% of the CPU after loading in the regular mode.
Also a very important point: CloudEngine puts the machines into the cloud so that up to 50% of its resources are used on one host. This is achieved quite simply: we are guaranteed to ensure that the cloud is reserved, that is, a drop of up to 50% of the hosts should lead to the migration of the VM to other hosts and the continuation of work, which means that a maximum of half of the cloud can be occupied. And this, in turn, means that, ideally, on each host no more than 50% of the occupied resources: this facilitates VM scaling (fewer migrations when scaling) and increases the share of CPU that goes to each machine.
In this article, I explained how CPU is distributed between VMs in a cloud. In the next I want to show how it works in practice. Wait for performance tests next week :) If you want to conduct an independent test - write, we will provide resources for this for free.
If you are interested in reading the materials on the allocation of CPU resources in Xen - below are the sources from which I used. If you find other interesting articles - write about it, please, in the comments.
Subscribe to our twitter , we try to look for interesting materials about virtualization and cloud computing for you. And come and test us / give us an idea about the functionality you need :)
We think that many of the subsystems and architectural solutions in Scalaxi will be interesting to you and decided to talk about them. We decided to start with the topic of allocation of CPU resources because the issue of guaranteed computing resources is always heard: we regularly hear it from customers who are just interested, critics and bloggers.
To deal with the distribution of resources, it is necessary to consider the architecture of our virtualization system, at least in general terms, and to study in detail particulars. In this article, I will try to explain how the distribution of CPU computing power between client virtual machines works: how long a CPU goes to each VM and how it is achieved.
Definitions
We in the Scalaxi team have become accustomed to some of the terms and definitions with which this text will be dazzled, so I will list them here:
- A VRT host or just VRT is one virtualization host, a physical server that hosts users' virtual machines;
- VM is a user's virtual machine, it is also a virtual server. In the world of classic hosting, a very simple version of this thing is called VPS.
Many other definitions and terms are described below, in the course of the material.
')
General Xen architecture
The easiest way to start the story about the CPU scheduler in Xen is with a short introductory description of the basic principles of the Xen hypervisor. Xen is a paravirtualization system that allows you to run several guest virtual machines on the same physical machine (host) that use Xen to access physical resources. At the same time, there are two possible ways to launch a guest VM - para-virtualization (PV), when a virtual machine starts up with a modified kernel and knows that it is running in Xen, or the machine starts up from any unmodified OS, and a special process is launched for it iron (qemu-dm), this mode is called HVM.
In Xen, guest virtual machines are also called domains. There is one privileged domain (Dom0) through which the hypervisor is managed, other guest machines work with I / O, and other virtual machines are managed. Guest virtual machines (DomU) can only be started after Dom0 has been loaded.
In general, the architecture of the Xen hypervisor has already been much discussed at habr, it is not worth being sprayed and disclosed in one article again.
CPU power planning & distribution
So, it turns out that we have a hardware level at which the hypervisor runs, on top of which several guest virtual machines (Dom0 & DomU) are running. Each of these virtual machines has access to the CPU. How is it organized?
Each virtual machine works with so-called virtual CPUs (vCPU), this is a virtualized representation of a single core. The number of vCPUs is assigned to each virtual machine individually, either in its configuration or using the xm vcpu-set command. At the same time, the number of vCPU on each virtual machine can be at least one and not more than the number of host cores.
The task of the hypervisor is to properly distribute the time of the physical CPUs between the vCPUs, the solution to this problem is dealt with by a component called cpu scheduler. In the course of writing this article, I found information about the three existing schedulers and a description of a certain scheduler, which should replace the fact that the default is used in Xen now. But the purpose of this article is to tell how this works in the cloud, so I’ll dwell on only one thing: credit scheduler.
If you search, then on Habré you can find articles on this topic . Therefore, here we briefly summarize the basic principles of the scheduler and once again examine the algorithm of its work:
- The scheduler works with vCPU as an object in the queue. Xen does not plan tasks inside the VM, it only controls the execution time of the vCPU, and the guest OS takes care of the work of the processes inside the VM;
- A virtual machine can limit the number of vCPUs - from one to the total number of cores;
- A virtual machine is assigned a weight, which controls the priority of the allocation of CPU time for its vCPU;
- Cap is an artificial limit on the maximum amount of CPU time allocated as a percentage of one physical core. 20 - 20% of one core, 400 - 4 cores completely, 0 - no limit;
- Dom0 also uses these parameters (and vCPU) and gets processor time according to its weight and cap parameters.
Now more about the algorithm:
- Each CPU in Xen has its own queue, in which vCPUs become. The vCPU in the queue has a credit level (number) and status (over / under), which indicates whether the virtual core received its CPU portion in this distribution period, or has not received enough;
- The settlement period is a certain period of time, once in which the external thread recalculates the number of credits of all vCPUs and changes their statuses according to the number of credits (points);
- CPU Time slice - a period of time (by default 30ms), which the CPU provides for one vCPU.
After working one time slice (vCPU blocked, went to idle, on the contrary woke up), the CPU moves to the next vCPU in the queue. At the same time, consuming CPU time-slices, points are written off from the vCPU account, if the number of points becomes negative, the vCPU will receive the status over and take its place in the queue. If the queue runs out of under-vCPUs, the CPU will look for such vCPUs in queues of other cores. If there is no one there either - he will look for the next vCPU in himself and others with the over status, but with a cap that allows to issue vCPU for a little more time. This approach ensures that even vCPUs with sufficiently low weight will get processor time, if the CPU of the system and other virtual machines is idle, and also ensures that the VM gets its processor time.
How it is organized in Scalaxi
In Skalaxi, we use Xen-hypervisor, user virtual machines run on VRT hosts. Our own development, CloudEngine, chooses which VRT host to run the machine on. The algorithm for choosing a suitable host is called an allocator, but if to explain it in a simple way, it chooses a suitable place for it on the basis of the number of VM slots so that the cloud is “properly” equipped: so that there is where to start other virtual machines and virtual the machines got more resources (in the paragraph above, we said that if the physical host is not 100% full, then the CPU will be allocated more than the guaranteed minimum).
SLES is launched in dom0, in which cap = 0 and weight = 16384. Next, client VMs sent by CloudEngine are launched in domU, and their weight is calculated based on one unit of weight per megabyte of RAM. Thus, it turns out that the total weight of domU-machines with a full load of VRT-host is 32768. That is, even if the host is loaded to capacity, dom0 will get enough computing resources if they are suddenly needed, and the host does not “choke” under the weight of domU-machines .
In fact, dom0 is almost always in idle, so we can assume that the CPU is distributed between client virtual machines with some minor losses on dom0. Frank Köhler, in his presentation, asserts that dom0 “eats up” up to 0.5% of the CPU after loading in the regular mode.
Also a very important point: CloudEngine puts the machines into the cloud so that up to 50% of its resources are used on one host. This is achieved quite simply: we are guaranteed to ensure that the cloud is reserved, that is, a drop of up to 50% of the hosts should lead to the migration of the VM to other hosts and the continuation of work, which means that a maximum of half of the cloud can be occupied. And this, in turn, means that, ideally, on each host no more than 50% of the occupied resources: this facilitates VM scaling (fewer migrations when scaling) and increases the share of CPU that goes to each machine.
What's next
In this article, I explained how CPU is distributed between VMs in a cloud. In the next I want to show how it works in practice. Wait for performance tests next week :) If you want to conduct an independent test - write, we will provide resources for this for free.
Materials on the topic
If you are interested in reading the materials on the allocation of CPU resources in Xen - below are the sources from which I used. If you find other interesting articles - write about it, please, in the comments.
- General overview of the Xen-hypervisor architecture ;
- Information about the distribution system CPU in Xen ;
- Details on credit scheduler ;
- And more about resource allocation in Xen ;
- Video presentation of Frank Kohler (Citrix) by XenServer ;
Subscribe to our twitter , we try to look for interesting materials about virtualization and cloud computing for you. And come and test us / give us an idea about the functionality you need :)
Source: https://habr.com/ru/post/109796/
All Articles