NLP: spell checker - an inside look (part 4)
(Parts 1 , 2 , 3 ) In the fourth part we will talk about checking the grammar outside of tokenized additions.
As already mentioned, the division of sentences into tokens and POS-markup already allows you to create a simple tool for checking the grammatical correctness of the text. At the very least, the LanguageTool plugin for Open Office works that way. Obviously, a lot of errors can be caught at the level of marked tokens. However, it is also clear that not less extensive classes of errors remain outside the capabilities of our module. Take at least such a simple thing as matching the subject and the predicate: “the lady loved dogs”, “loved the dogs lady”, “dogs the lady loved” ... how to create a pattern for the rule “predicate should have the same gender as the subject?” Even for English with a more or less clear word order is difficult; it’s not at all necessary to talk about Russian.
The authors of LanguageTool try to formulate separate grammatical patterns. In practice, quite complex structures are obtained that work in a limited number of cases. For example:
')
“A sentence begins with a defining word, then a noun comes in plural, then a verb in the third person, singular.” Fragments like “The cats drinks milk” fall under this definition. Obviously, the verb should be in the form of first person (drink). As you can see, this rule only works at the beginning of a sentence and only for a clearly defined situation. The authors are probably reinsured in order to avoid false positives (it is clear that not every pair of closely spaced words “noun + verb” is a bundle of the form “subject + predicate”).
I see a more reliable variant involving the parser of a natural language.

There are different ideas about how words should be connected. Instead of the direct “word-word” edges, you can, for example, select the constituent members of a sentence:
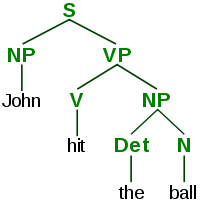
This approach was promoted by Chomsky, and it is still popular among English-speaking researchers. However, there are more and more supporters of “word-word” links (dependency links), especially in Europe, since it is believed that Chomsky trees are not well suited for languages with a freer word order (and there are a lot of such languages in Europe).
Perhaps, on the parser, I had the first plug in the work. It is difficult to find a good parser (by the way, sentence splitter and POS tagger too, but you can quickly write them yourself, since there are auxiliary libraries). We still have a practical project, and we would like this module to be (a) in C / C ++ (since our entire project is on it); (b) was free or cost reasonable money; (c) supported dependency links; (d) was adaptable to new languages.
I spent a lot of time searching, tried a lot of parsers. There is complete confusion here - someone does not hold onto the parser (LGPL), someone wants unreal money (I was called prices of 100 and even 300 thousand euros - in my opinion, this is beyond good and evil), and then you need a percentage of sales. Okay, the parser would be the main module in the system, but this is not the case, it’s just part of the grammar checker module!
A few months ago I decided to stop at the MaltParser project. He is good at everything (even supports so-called non-projective connections, which is nice), except for the language chosen by the authors - Java. I was ready to bite the bullet and rewrite the code in C ++ (and there is a lot of code ...), but just recently a new project was drawn called LDPar . I do not know how it is with the quality of analysis, but it suits the other criteria. The Chinese will save the world! Well, or at least our project :)
In truth, I am not yet ready to give here specific examples of grammatical rules that are analyzed with the help of the parser - we just started experimenting with this module. But the simplest ideas are already clear. For example, how to check the compatibility of the subject with the predicate (for English):
We take the root of the tree, check that the root is a verb - then this predicate.
Looking for the first noun or pronoun associated with it - this is the subject.
We check the compatibility in the face and number.
Of the obvious potential problems, I can name the incomprehensible quality of parsing incorrect proposals. That is, it is not immediately clear whether the parser will consider the words I and has as subject and predicate in the sentence “I has dogs”. On this topic you need to conduct research, while there are none. In the comments, the corpus was somehow mentioned with errors (authored by J. Foster) - here I personally tested some parsers. Most of them correctly analyzed even phrases with errors, but additional study of the question definitely would not hurt.
So, for today I finish, and in the next part we will talk a little more about the three banks.
As already mentioned, the division of sentences into tokens and POS-markup already allows you to create a simple tool for checking the grammatical correctness of the text. At the very least, the LanguageTool plugin for Open Office works that way. Obviously, a lot of errors can be caught at the level of marked tokens. However, it is also clear that not less extensive classes of errors remain outside the capabilities of our module. Take at least such a simple thing as matching the subject and the predicate: “the lady loved dogs”, “loved the dogs lady”, “dogs the lady loved” ... how to create a pattern for the rule “predicate should have the same gender as the subject?” Even for English with a more or less clear word order is difficult; it’s not at all necessary to talk about Russian.
The authors of LanguageTool try to formulate separate grammatical patterns. In practice, quite complex structures are obtained that work in a limited number of cases. For example:
')
<token postag = "SENT_START" > </ token>
<token postag = "DT" > </ token>
<token postag = "NNS" > </ token>
<token postag = "VBZ" > </ token>
* This source code was highlighted with Source Code Highlighter .
“A sentence begins with a defining word, then a noun comes in plural, then a verb in the third person, singular.” Fragments like “The cats drinks milk” fall under this definition. Obviously, the verb should be in the form of first person (drink). As you can see, this rule only works at the beginning of a sentence and only for a clearly defined situation. The authors are probably reinsured in order to avoid false positives (it is clear that not every pair of closely spaced words “noun + verb” is a bundle of the form “subject + predicate”).
I see a more reliable variant involving the parser of a natural language.
About parsing
A parser is a module that builds an input tree of words for an input sentence. An example of such a tree for the phrase “I love big dogs” was cited in the second part of the notes:There are different ideas about how words should be connected. Instead of the direct “word-word” edges, you can, for example, select the constituent members of a sentence:
This approach was promoted by Chomsky, and it is still popular among English-speaking researchers. However, there are more and more supporters of “word-word” links (dependency links), especially in Europe, since it is believed that Chomsky trees are not well suited for languages with a freer word order (and there are a lot of such languages in Europe).
Perhaps, on the parser, I had the first plug in the work. It is difficult to find a good parser (by the way, sentence splitter and POS tagger too, but you can quickly write them yourself, since there are auxiliary libraries). We still have a practical project, and we would like this module to be (a) in C / C ++ (since our entire project is on it); (b) was free or cost reasonable money; (c) supported dependency links; (d) was adaptable to new languages.
I spent a lot of time searching, tried a lot of parsers. There is complete confusion here - someone does not hold onto the parser (LGPL), someone wants unreal money (I was called prices of 100 and even 300 thousand euros - in my opinion, this is beyond good and evil), and then you need a percentage of sales. Okay, the parser would be the main module in the system, but this is not the case, it’s just part of the grammar checker module!
A few months ago I decided to stop at the MaltParser project. He is good at everything (even supports so-called non-projective connections, which is nice), except for the language chosen by the authors - Java. I was ready to bite the bullet and rewrite the code in C ++ (and there is a lot of code ...), but just recently a new project was drawn called LDPar . I do not know how it is with the quality of analysis, but it suits the other criteria. The Chinese will save the world! Well, or at least our project :)
In truth, I am not yet ready to give here specific examples of grammatical rules that are analyzed with the help of the parser - we just started experimenting with this module. But the simplest ideas are already clear. For example, how to check the compatibility of the subject with the predicate (for English):
We take the root of the tree, check that the root is a verb - then this predicate.
Looking for the first noun or pronoun associated with it - this is the subject.
We check the compatibility in the face and number.
Of the obvious potential problems, I can name the incomprehensible quality of parsing incorrect proposals. That is, it is not immediately clear whether the parser will consider the words I and has as subject and predicate in the sentence “I has dogs”. On this topic you need to conduct research, while there are none. In the comments, the corpus was somehow mentioned with errors (authored by J. Foster) - here I personally tested some parsers. Most of them correctly analyzed even phrases with errors, but additional study of the question definitely would not hurt.
So, for today I finish, and in the next part we will talk a little more about the three banks.
Source: https://habr.com/ru/post/109382/
All Articles