Large traffic flows and interrupt management in Windows
I really liked the topic about the load distribution from interruptions of the network adapter across processors, so I decided to describe how this is done in Windows.
Disclaimer: judging by some of the comments in previous posts, I should repeat what I started with the first post: I do not give (and can not give) generally applicable recipes. This is especially true of performance, where the smallest unrecorded part can have a disastrous effect on the result. Rather, the recommendation I give: TESTING AND ANALYSIS. The point of my writing is to give people as much information as possible for analysis, because the more you understand how something works, the easier it is to find ways to eliminate bottlenecks.
So, network bandwidth scalability. Requires Windows Server 2003 SP2 +. A network card that supports Receive Side Scaling (you can say with a fair degree of confidence that any server network card released in the past 5 years or any general 1Gb + NIC will work, although you can often see RSS and 100Mb). Install Windows Server and drivers on the card ...
')
EVERYTHING. Setup complete. RSS is enabled by default in all versions of Windows in which it is supported.
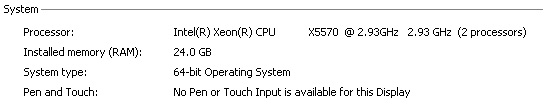
Take a not-so-new Dell server with two quad core xeons:
There are two dual-port 1Gb network cards and one 10Gb onboard, but I didn’t find a 10Gb switch, so I couldn’t get it - but oh well:

What is interesting about these cards is that despite RSS support in 8 queues, they do not support MSI-X or even MSI. Moreover, out of the four available pin-based interrupt lines, only one is allocated to each network port (accordingly, it is no longer possible to force interrupts to come to different processors — this is a hardware limitation of this configuration). 10 gigabits registered to themselves either 32 or 64 (by eye) interrupt vectors, but using it is not destiny. Can Hindu crafts to run games to cope with the task?

Just in case, check the RSS (although if it is not - it will be noticeable and so):

First, turn off RSS (I turned it back on after testing, but in the same window)

and run the load test:
Fully loaded two cores, all others are idle
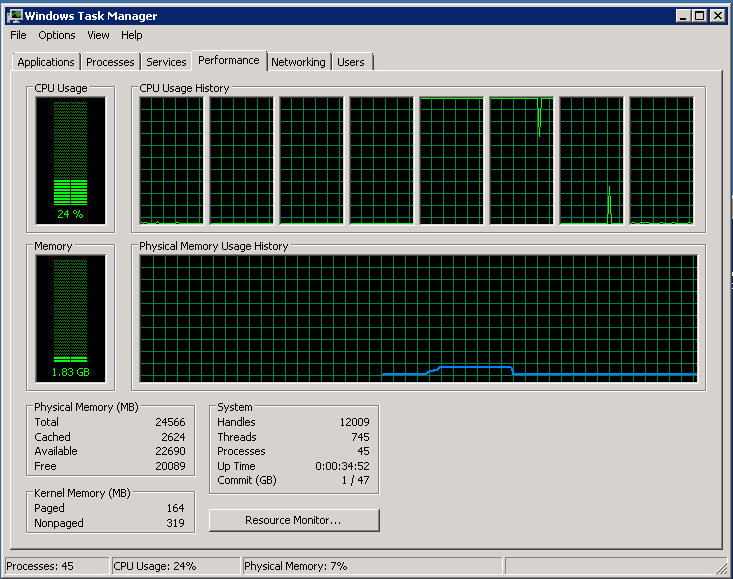
Network loaded by third:
50% of one processor is clogged with interrupt processing, another 20% of the same processor is DPC processing. The rest is the tcpip stack and the application that gives traffic.
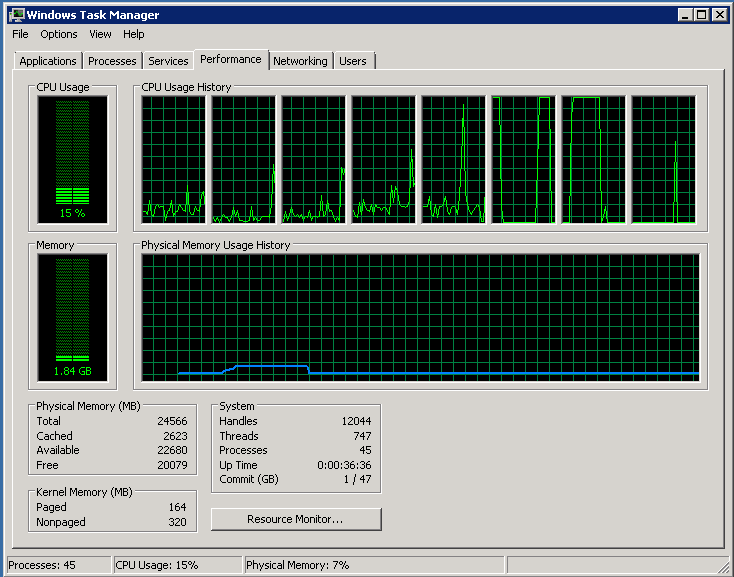
Turn on RSS (screenshot above). CPU:
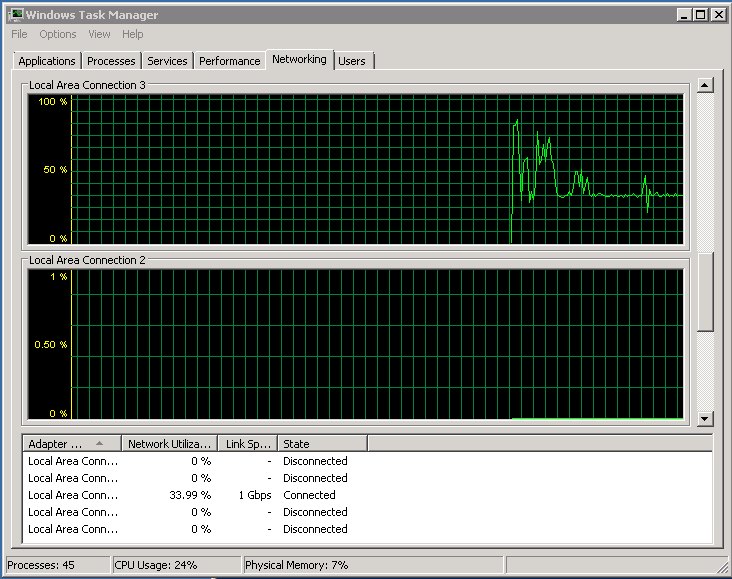
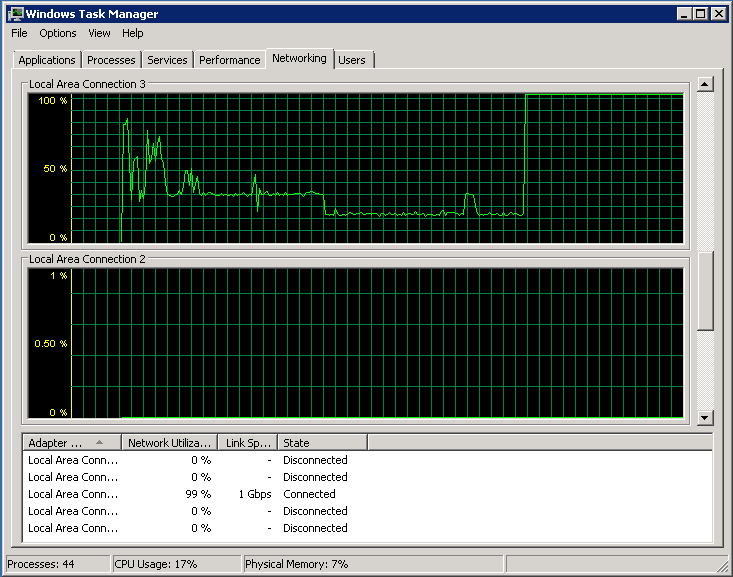
Network:
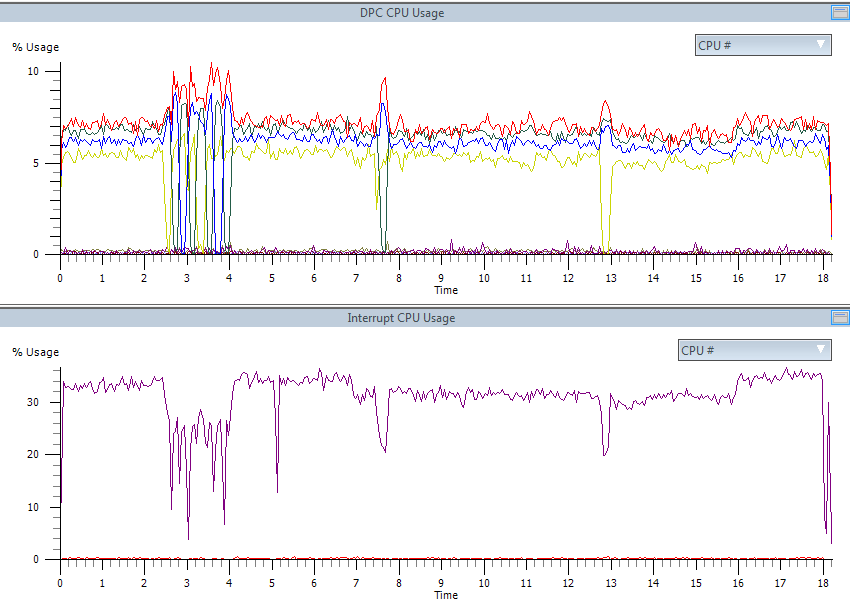
One third of the processor is full of interrupts, but the DPCs are perfectly parallelized.
In general, on this configuration it would be possible to give about 3 gigabits (from one network card) and only then we would meet a bottle neck.
Just in case, I will say that RSS has a less well-known relative - Send Side Scaling. If you set the hash value before sending the list of buffers, the interruption after the completion of the parcel will be delivered in accordance with the established indirection tables.
Here you can read about RSS, and here there is a good presentation in pictures explaining the work of RSS. If it is interesting, I can try to describe in my own words the mechanisms of RSS operation, but as for me it is better to read the original sources.
If something like RSS in Linux is about to appear (I did not find any mention of support for normal hardware RSS in Linux: who knows - give the link - pro-update post). That's all officially difficult with TOE in Linux. The patch from Chelsio (one of the manufacturers of high-end network cards) that implements TOE support was rejected, and instead some kind of completely idiotic excuses started (when you read it, you should bear in mind that BSD and Windows have had normal TOE support for many years) .
So what is it? TOE is a complete TCPIP implementation at the hardware level: with delivery confirmation, retransmitting for errors, window control, etc .: a DMA network card directly takes data from memory, cuts packets, attaches headers, and reports (using interrupts) only the most extreme cases.
By default, TOE is in automatic mode. Watch Chimney Offload State:
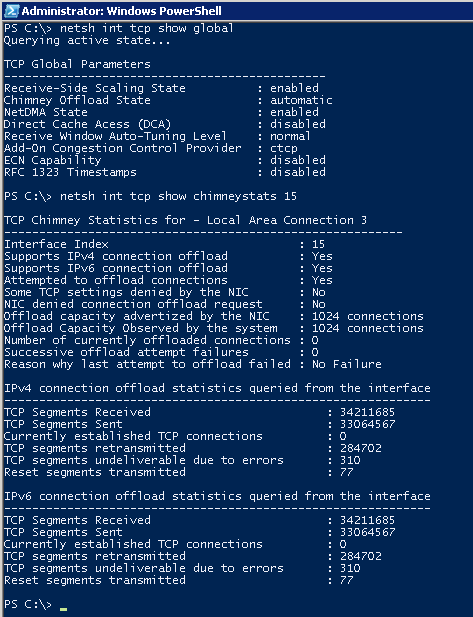
The screenshot was taken during active testing, but in statistics it is clear that there is not a single “unloaded” connection to the network interface card (for the reasons later). We turn on forcibly (and after a while request statistics):
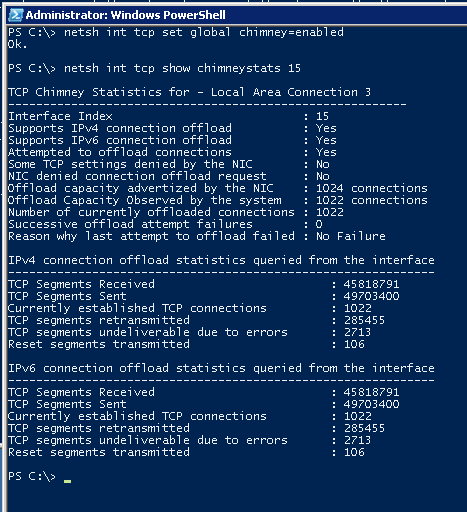
And here is the reason: only 1024 connections can be unloaded into this network card (but the system has really been able to unload 1022). Quite an expensive resource, so you can unload everything. The system heuristically tries to detect connections (get / put large files over http, transferring file content to file servers, etc.) that will last a long time and unloads them in the first place.
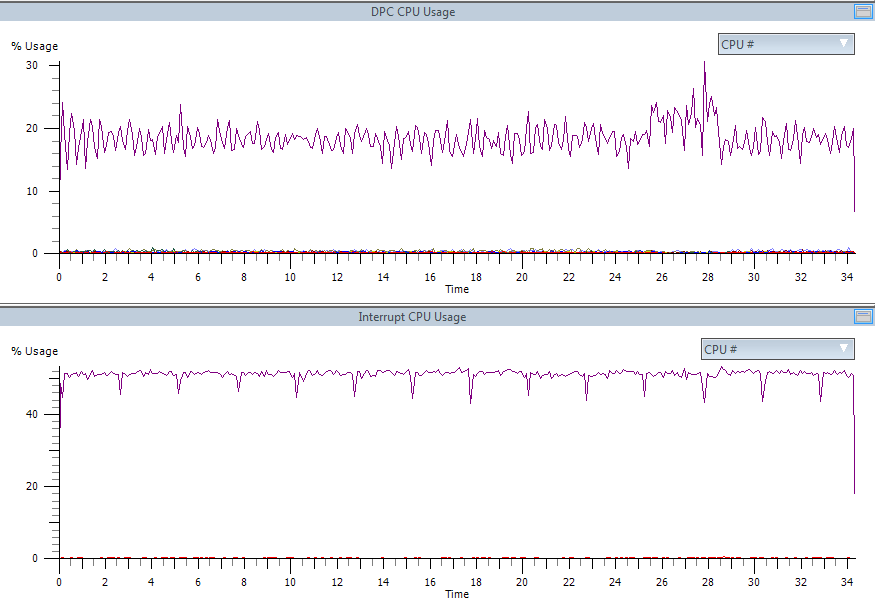
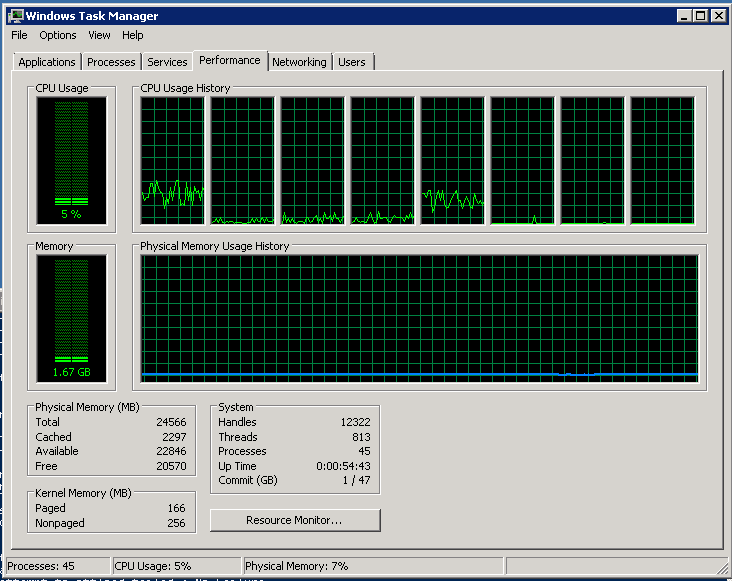
But still look what happened. The processor has tripled three times:
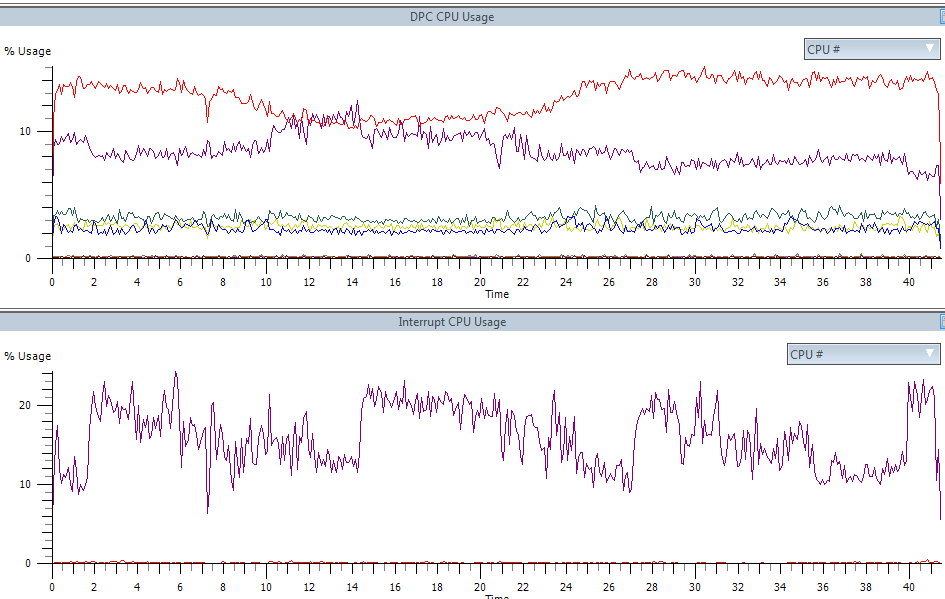
The number (and time spent in) of both the ISR and the DPC has drastically decreased:
Disclaimer: judging by some of the comments in previous posts, I should repeat what I started with the first post: I do not give (and can not give) generally applicable recipes. This is especially true of performance, where the smallest unrecorded part can have a disastrous effect on the result. Rather, the recommendation I give: TESTING AND ANALYSIS. The point of my writing is to give people as much information as possible for analysis, because the more you understand how something works, the easier it is to find ways to eliminate bottlenecks.
So, network bandwidth scalability. Requires Windows Server 2003 SP2 +. A network card that supports Receive Side Scaling (you can say with a fair degree of confidence that any server network card released in the past 5 years or any general 1Gb + NIC will work, although you can often see RSS and 100Mb). Install Windows Server and drivers on the card ...
')
EVERYTHING. Setup complete. RSS is enabled by default in all versions of Windows in which it is supported.
Testing
Take a not-so-new Dell server with two quad core xeons:
There are two dual-port 1Gb network cards and one 10Gb onboard, but I didn’t find a 10Gb switch, so I couldn’t get it - but oh well:
What is interesting about these cards is that despite RSS support in 8 queues, they do not support MSI-X or even MSI. Moreover, out of the four available pin-based interrupt lines, only one is allocated to each network port (accordingly, it is no longer possible to force interrupts to come to different processors — this is a hardware limitation of this configuration). 10 gigabits registered to themselves either 32 or 64 (by eye) interrupt vectors, but using it is not destiny. Can Hindu crafts to run games to cope with the task?
Just in case, check the RSS (although if it is not - it will be noticeable and so):
First, turn off RSS (I turned it back on after testing, but in the same window)
and run the load test:
Fully loaded two cores, all others are idle
Network loaded by third:
50% of one processor is clogged with interrupt processing, another 20% of the same processor is DPC processing. The rest is the tcpip stack and the application that gives traffic.
Turn on RSS (screenshot above). CPU:
Network:
One third of the processor is full of interrupts, but the DPCs are perfectly parallelized.
In general, on this configuration it would be possible to give about 3 gigabits (from one network card) and only then we would meet a bottle neck.
Just in case, I will say that RSS has a less well-known relative - Send Side Scaling. If you set the hash value before sending the list of buffers, the interruption after the completion of the parcel will be delivered in accordance with the established indirection tables.
Here you can read about RSS, and here there is a good presentation in pictures explaining the work of RSS. If it is interesting, I can try to describe in my own words the mechanisms of RSS operation, but as for me it is better to read the original sources.
TCP Offload Engine
If something like RSS in Linux is about to appear (I did not find any mention of support for normal hardware RSS in Linux: who knows - give the link - pro-update post). That's all officially difficult with TOE in Linux. The patch from Chelsio (one of the manufacturers of high-end network cards) that implements TOE support was rejected, and instead some kind of completely idiotic excuses started (when you read it, you should bear in mind that BSD and Windows have had normal TOE support for many years) .
So what is it? TOE is a complete TCPIP implementation at the hardware level: with delivery confirmation, retransmitting for errors, window control, etc .: a DMA network card directly takes data from memory, cuts packets, attaches headers, and reports (using interrupts) only the most extreme cases.
By default, TOE is in automatic mode. Watch Chimney Offload State:
The screenshot was taken during active testing, but in statistics it is clear that there is not a single “unloaded” connection to the network interface card (for the reasons later). We turn on forcibly (and after a while request statistics):
And here is the reason: only 1024 connections can be unloaded into this network card (but the system has really been able to unload 1022). Quite an expensive resource, so you can unload everything. The system heuristically tries to detect connections (get / put large files over http, transferring file content to file servers, etc.) that will last a long time and unloads them in the first place.
But still look what happened. The processor has tripled three times:
The number (and time spent in) of both the ISR and the DPC has drastically decreased:
Source: https://habr.com/ru/post/108302/
All Articles