You must be kidding, Mr. Dahl, or why Node.js is the crown of web server evolution
Node.js is a thing around which there is now a lot of noise, enthusiastic reviews and angry shouts. At the same time, according to my observations, the following idea of what Node.js is in the minds of people: “this is a thing that allows writing on JavaScript on the server side and using the JavaScript engine from Google Chrome”. Fans of the language enthusiastically sighed: “Ah! It has come true! ”, The opponents said through clenched teeth:“ Well, only this nonsense with prototypes and dynamic typing was not enough for us on the servers! ”. And they ran together to break spears in blogs and forums.
At the same time, many representatives of both camps hold the opinion that Node.js is an esoteric toy, a cheerful idea for transferring the language of browser scripts to the “new wheels”. In order to be completely honest, I confess that I also adhered to this point of view. At one fine moment, I gained inspiration and decided to "dig deeper." It turned out that the creator of Node.js, Ryan Dahl, was far from a fanatic, but a person trying to solve a real problem. And his creation is not a toy, but a practical solution.
')
So what is Node.js? The official site has an inscription: "Evented I / O for V8 JavaScript". Not very meaningful, right? Well, let's try to “invent a bicycle” and “invent” this most notorious “Evented I / O for V8 JavaScript”. Of course, we will not write any code (poor Ryan still had to do it), but just try to build a chain of conclusions that will lead us to the idea of creating Node.js and how it should be arranged.
Keep it simple, stupid
So, you know that web applications use a client-server software model . The client is the user's browser, and the server is, for example, one of the machines in the data center of a certain hoster (select any one to your taste). The browser requests a resource from the server, which, in turn, gives it to the client. This way of communication between the client and the server is called “ client pull ”, because the client literally pulls ( English pull) the server - “Give me that page, give me ...”. The server "ponders" the answer to the question of the annoying client and gives it to him in a digestible form.
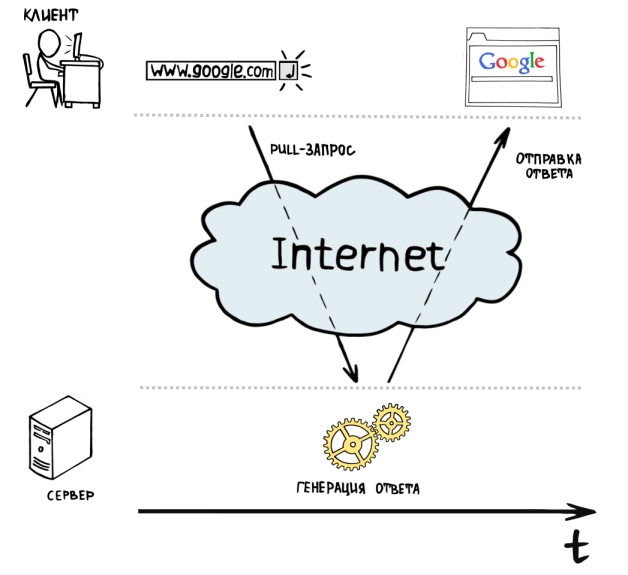
So, we have a simplest web server model - a program that accepts requests from client browsers, processes them and returns a response.
Parallel universe
This is great, but such a simple server can communicate with only one user at a time. If at the time of processing the request to contact another client, then he will have to wait until the server responds first. So we need to parallelize the processing of requests from users. The obvious solution: handle user requests in separate threads or operating system processes . Let's call each such process or thread worker ( English worker).

In one form or another, many of the most popular web servers today (for example, Apache and IIS ) adhere to this approach. This model is relatively simple to implement and at the same time can meet the needs of most small and medium-sized web resources today.
But this model is completely incapable, if you need to process thousands of requests simultaneously. There are several reasons for this. First, creating processes and threads is a damn expensive thing for any operating system. But we can go to the trick and create threads or processes in advance and use them as needed. OK, we just came up with mechanisms called thread pool for threads and process prefork . This will help us not to waste resources on creating processes and threads, since this invoice operation can be performed, for example, when the server is started. Secondly, what to do if all the workers created are busy? Create new? But we already fully loaded all the processor cores of our server; if we add several more threads or processes, they will compete for processor time with threads and processes already running. So both those and others will work even more slowly. Yes, and as noted earlier, creating and servicing threads and processes is a costly thing in terms of memory consumption, and if we create a stream for each of the thousands of users, then we may soon find ourselves in a situation where there is simply no memory left on the server and worker You will be in a state of constant competition for hardware resources.
To infinity and beyond!
It would seem that we were in an unsolvable situation with the available computing resources. The only solution is to scale hardware resources , which is costly in all respects. Let's try to look at the problem from the other side: what are the majority of our workers doing? They accept the request from the client, create a response and send it to the client. So where is the weak link? There are two of them here - receiving a request from a client and sending a response. To understand that this is so, it is enough just to remember the average speed of the Internet connection today. But after all, the I / O subsystem can work in asynchronous mode , and therefore it can not block workers. Hmm, then it turns out that the only thing our workers will do is generate a response for the client and manage tasks for the I / O subsystem. Previously, each worker could serve only one client at a time, since he took responsibility for the execution of the entire request processing cycle. Now, when we delegated the network I / O to the I / O subsystem, one worker can simultaneously serve several requests, for example, generating a response for one client while the answer for another is given by the I / O subsystem. It turns out now that we do not need to allocate a thread for each of the users, and we can create one worker per server processor, thus giving him a maximum of hardware resources.
In practice, such delegation is implemented using the event-oriented programming paradigm. Programs developed according to this paradigm can be implemented as a state machine . Certain events translate this automaton from one state to another. In our case, the server will be implemented as an infinite loop that will generate responses for clients, query I / O subsystem descriptors for their readiness to perform a particular operation, and, if successful, send them a new task. The process of polling I / O subsystem descriptors is called “ polling ”. The fact is that effective polling implementations are currently available only in * nix-systems, since the latter provide very fast linear execution time system calls for these purposes (for example, epoll on Linux and kqueue on BSD systems). This is a very efficient server model, because it allows you to use hardware resources to the maximum. In fact, none of the server subsystems are idle idle, as can be easily seen by looking at the figure.
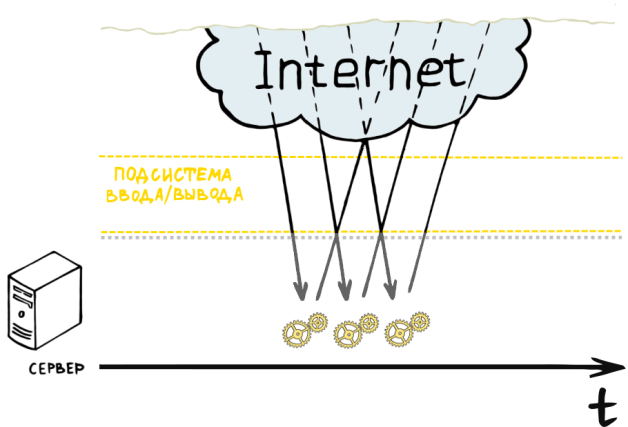
A similar concept is used by servers such as nginx and lightppd , which have proven themselves in high-load systems.
Let's come together
But (there is always “one thing”), before that we were repelled by the idea that generating an answer takes an order of magnitude less time than communicating with a client. And this is partly true. However, sometimes generating a response can be a complex and complex task, which can include reading and writing to disk, working with a database (which can also be located on a remote server). Well, it turns out we actually returned to the original problem. In practice, it is resolved as follows: the system is divided into two parts - the front-end and the back-end . The front-end is the server with which the client directly communicates. As a rule, this is a server with an asynchronous event model that can quickly communicate with clients and give them query results (for example, nginx). A back-end is a server with a blocking I / O model (for example, Apache), to which the front-end delegates the creation of a response for the client, just as it does with the I / O subsystem. Such a front-end is also called “ reverse proxy ”, because in fact it is a regular proxy server , but installed in the same server environment as the server to which it redirects requests.
If we draw analogies with real life, then the front-end is a manager with teeth shining in whiteness and in an expensive suit, the back-end is a group of workers at the plant, and the I / O subsystem is the transport department of the company that the manager works for and which owns factory. Clients contact the manager by sending him letters through the transport department. The manager makes a deal with the customer for the delivery of a batch of products and sends an instruction to the workers to make a batch. The manager himself, in turn, does not expect the workers to finish the execution of the order, but continues to take care of their immediate responsibilities - concludes transactions with clients and ensures that the whole process proceeds in a coordinated and fine manner. Periodically, the manager contacts the workers to inquire about the degree of readiness of the order, and if the party is ready, he instructs the transport department to send the order to the client. Well, of course, periodically it follows that the goods reach the customer. This is how the idea of the division of labor which was invented thousands of years ago found an unexpected application in high technology.
And the reaper, and the Swiss, and on the dude igrets (it would seem, and here JavaScript?)
Well, all this works fine, but somehow our system is extremely complicated, isn’t it? Yes, even though we delegate the generation of a response to another server, this is still not the fastest process, because during it, blocking can occur due to file I / O and database operation, which inevitably leads to processor idle time. So how do we restore integrity to the system and at the same time eliminate bottlenecks in the process of generating an answer? Elementary, Watson - we will do all the input / output and work with the database non-blocking, built on events (yes, that evented I / O )!
“But this also changes the whole paradigm of creating web applications, and most of the existing frameworks are no longer applicable or applicable, but solutions using them are not elegant!” - you say and you will be right. Yes, and the human factor cannot be excluded - applying the Murphy law it can be argued that “ if there is a possibility to use the functions of blocking I / O, then someone will do it sooner or later ”, thus breaking the whole initial idea. It is only a matter of time, project scope, and programmer qualifications. “Be careful making abstractions. You might have to use them. "( Eng. " Be careful in creating abstractions, because you may have to use them ") - says Ryan in his speech on Google Tech Talk . So let's stick to minimalism and create only a foundation that will allow us to develop web applications and at the same time will be so well sharpened by an asynchronous programming model that we will not have the opportunity, and most importantly - the desire, to retreat from it. So what is the minimum we need?
Obviously, we first need an execution environment , the main requirements for which are fast execution of the response generation code and asynchronous I / O. What modern programming language is designed for an event model, is it known to all web developers and at the same time has fast and actively developing implementations? The answer is obvious - this is javascript. Moreover, we have at our disposal a JavaScript V8 engine from Google , distributed under a very liberal BSD license. V8 is beautiful in many aspects: firstly, it uses JIT compilation and many other optimization techniques , and secondly, it is an example of a well-made, thoughtful and actively developing software product (I usually cite V8 as an example of really high-quality C ++ code for colleagues at work). Add to all this the library libev , which will allow us to easily organize an event loop and provide a higher level wrapper for the polling mechanisms (so that we do not have to worry about the features of its implementation for various operating systems). We also need the libeio library for fast asynchronous file I / O. Well, on this our performing environment can be considered finished.
And, of course, we need a standard library that will contain JavaScript wrappers for all basic I / O operations and functions, without which web development cannot go far (for example, parsing HTTP headers and URLs, hash counting, DNS rezolving, etc.).
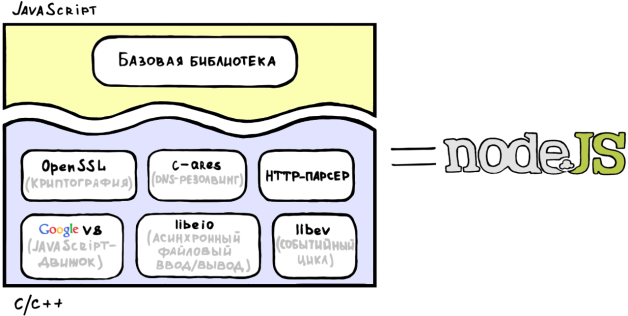
It is probably worth congratulating us - we just came up with the concept of a very fast server - Node.js.
I'm just sayin '
Summarizing, I would like to say that Node.js is a very young project that, if properly used, can make a revolution in the world of web development in due time. Today the project has a number of unsolved problems that complicate its use in real high-load systems (although there are already precedents ). For example, Node.js is essentially only one worker. If you have, say, a dual-core processor, then the only way to fully use its hardware resources with Node.js is to run two server instances (one for each core) and use reverse proxy (for example, the same nginx) to load balance between them.
But all such problems are solvable and active work is being done on them, and a huge community is being built around Node.js, and many large companies are paying considerable attention to this development. It remains only to wish Mr. Dal to finish his job (in which, by the way, you can help him ), and you, dear reader, spend a lot of pleasant time working on Node.js.
Source: https://habr.com/ru/post/108241/
All Articles