[Translation] Java Best Practices. Convert Char to Byte and Back
The Java Code Geeks site occasionally publishes posts in the Java Best Practices series - production-tested solutions. Having received permission from the author, translated one of the posts. Further more.
Continuing the series of articles on some aspects of Java programming, we will touch on the performance of String today, especially when converting a character to a byte-sequence and back again when the default encoding is used. Finally, we will apply a performance comparison between non-classical and classical approaches for converting characters to byte-sequence and vice versa.
All surveys are based on problems in developing highly efficient systems for telecommunication tasks (ultra high performance production systems for the telecommunication industry) .
')
Before each part of the article we highly recommend you to familiarize yourself with the Java API for more information and code examples.
Experiments were performed on Sony Vaio with the following characteristics:
OS: openSUSE 11.1 (x86_64)
Processor (CPU): Intel® Core (TM) 2 Duo CPU T6670 @ 2.20GHz
Frequency: 1,200.00 MHz
RAM (RAM): 2.8 GB
Java: OpenJDK 1.6.0_0 64-Bit
With the following parameters:
Simultaneously threads: 1
The number of iterations of the experiment: 1000000
Total tests: 100
The task of converting Char to Byte and back is widespread in the field of communications, where the programmer is obliged to process byte sequences, serialize String, and implement protocols, etc.
There is a toolkit for this in Java .
The “getBytes (charsetName)” method of the String class is probably one of the most popular tools for converting a String into its byte equivalent. The charsetName parameter points to the String encoding; in the absence of this, the method encodes the String into a sequence of bytes using the default encoding in the OS.
Another classic approach to converting a character array to its byte equivalent is to use the ByteBuffer class from the NIO ( New Input Output ) package.
Both approaches are popular and, of course, fairly easy to use, but they have serious performance problems compared to more specific methods. Remember: we do not convert from one encoding to another, for this you must follow the “classical” approaches using either “String.getBytes (charsetName)” or the capabilities of the NIO package.
In the case of ASCII, we have the following code:
An array b is created by casting ( casting ) the values of each character into its byte equivalent, while taking into account the ASCII- range (0-127) characters, each of which occupies one byte.
Array b can be converted back to a string using the constructor “new String (byte [])” :
For the default encoding, we can use the following code:
Each character in Java takes 2 bytes, to convert a string to a byte equivalent, you must translate each character of a string into its two-byte equivalent.
And back to the line:
We restore each character of a string from its two-byte equivalent and then, again using the String constructor (char []) , create a new object.
Examples of using the features of the NIO package for our tasks:
And now, as promised, the graphics.
String in byte array :
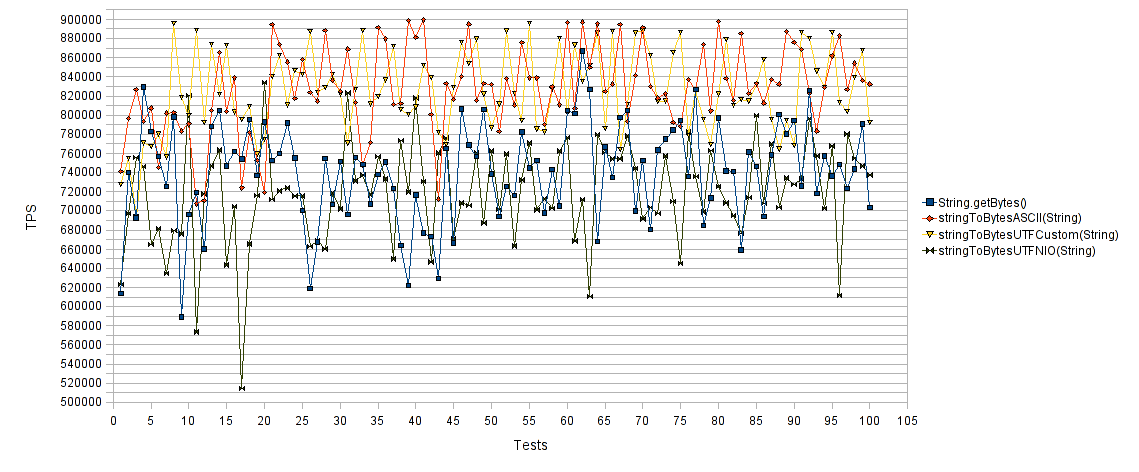
The abscissa axis is the number of tests, the ordinate is the number of operations per second for each test. What is higher is faster. As expected, "String.getBytes ()" and "stringToBytesUTFNIO (String)" worked much worse than "stringToBytesASCII (String)" and "stringToBytesUTFCustom (String)" . Our implementations, as can be seen, achieved almost a 30% increase in the number of operations per second.
Byte array to String :
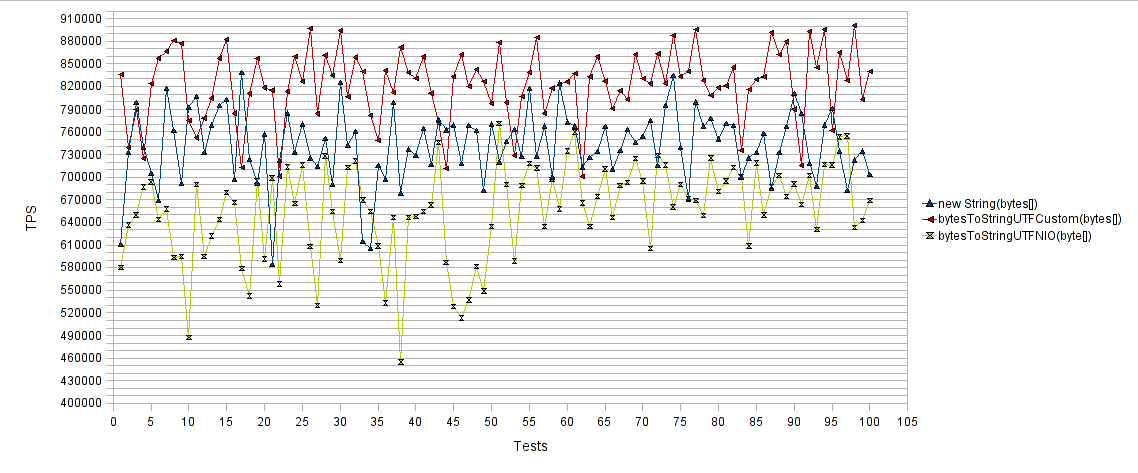
The results again are encouraging. Our own methods have achieved a 15% increase in the number of operations per second compared to the “new String (byte [])” and a 30% increase in the number of operations per second compared to the “bytesToStringUTFNIO (byte [])” .
As output: in the event that you need to convert a byte sequence to a string or vice versa, without having to change the encodings, you can get a remarkable performance gain using handwritten methods. As a result, our methods achieved an overall 45% acceleration compared to classical approaches.
Happy coding.
Continuing the series of articles on some aspects of Java programming, we will touch on the performance of String today, especially when converting a character to a byte-sequence and back again when the default encoding is used. Finally, we will apply a performance comparison between non-classical and classical approaches for converting characters to byte-sequence and vice versa.
All surveys are based on problems in developing highly efficient systems for telecommunication tasks (ultra high performance production systems for the telecommunication industry) .
')
Before each part of the article we highly recommend you to familiarize yourself with the Java API for more information and code examples.
Experiments were performed on Sony Vaio with the following characteristics:
OS: openSUSE 11.1 (x86_64)
Processor (CPU): Intel® Core (TM) 2 Duo CPU T6670 @ 2.20GHz
Frequency: 1,200.00 MHz
RAM (RAM): 2.8 GB
Java: OpenJDK 1.6.0_0 64-Bit
With the following parameters:
Simultaneously threads: 1
The number of iterations of the experiment: 1000000
Total tests: 100
Convert Char to Byte and Back:
The task of converting Char to Byte and back is widespread in the field of communications, where the programmer is obliged to process byte sequences, serialize String, and implement protocols, etc.
There is a toolkit for this in Java .
The “getBytes (charsetName)” method of the String class is probably one of the most popular tools for converting a String into its byte equivalent. The charsetName parameter points to the String encoding; in the absence of this, the method encodes the String into a sequence of bytes using the default encoding in the OS.
Another classic approach to converting a character array to its byte equivalent is to use the ByteBuffer class from the NIO ( New Input Output ) package.
Both approaches are popular and, of course, fairly easy to use, but they have serious performance problems compared to more specific methods. Remember: we do not convert from one encoding to another, for this you must follow the “classical” approaches using either “String.getBytes (charsetName)” or the capabilities of the NIO package.
In the case of ASCII, we have the following code:
public static byte[] stringToBytesASCII(String str) { char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length]; for (int i = 0; i < b.length; i++) { b[i] = (byte) buffer[i]; } return b; } An array b is created by casting ( casting ) the values of each character into its byte equivalent, while taking into account the ASCII- range (0-127) characters, each of which occupies one byte.
Array b can be converted back to a string using the constructor “new String (byte [])” :
System.out.println(new String(stringToBytesASCII("test"))); For the default encoding, we can use the following code:
public static byte[] stringToBytesUTFCustom(String str) { char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length << 1]; for(int i = 0; i < buffer.length; i++) { int bpos = i << 1; b[bpos] = (byte) ((buffer[i]&0xFF00)>>8); b[bpos + 1] = (byte) (buffer[i]&0x00FF); } return b; } Each character in Java takes 2 bytes, to convert a string to a byte equivalent, you must translate each character of a string into its two-byte equivalent.
And back to the line:
public static String bytesToStringUTFCustom(byte[] bytes) { char[] buffer = new char[bytes.length >> 1]; for(int i = 0; i < buffer.length; i++) { int bpos = i << 1; char c = (char)(((bytes[bpos]&0x00FF)<<8) + (bytes[bpos+1]&0x00FF)); buffer[i] = c; } return new String(buffer); } We restore each character of a string from its two-byte equivalent and then, again using the String constructor (char []) , create a new object.
Examples of using the features of the NIO package for our tasks:
public static byte[] stringToBytesUTFNIO(String str) { char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length << 1]; CharBuffer cBuffer = ByteBuffer.wrap(b).asCharBuffer(); for(int i = 0; i < buffer.length; i++) cBuffer.put(buffer[i]); return b; } public static String bytesToStringUTFNIO(byte[] bytes) { CharBuffer cBuffer = ByteBuffer.wrap(bytes).asCharBuffer(); return cBuffer.toString(); } And now, as promised, the graphics.
String in byte array :
The abscissa axis is the number of tests, the ordinate is the number of operations per second for each test. What is higher is faster. As expected, "String.getBytes ()" and "stringToBytesUTFNIO (String)" worked much worse than "stringToBytesASCII (String)" and "stringToBytesUTFCustom (String)" . Our implementations, as can be seen, achieved almost a 30% increase in the number of operations per second.
Byte array to String :
The results again are encouraging. Our own methods have achieved a 15% increase in the number of operations per second compared to the “new String (byte [])” and a 30% increase in the number of operations per second compared to the “bytesToStringUTFNIO (byte [])” .
As output: in the event that you need to convert a byte sequence to a string or vice versa, without having to change the encodings, you can get a remarkable performance gain using handwritten methods. As a result, our methods achieved an overall 45% acceleration compared to classical approaches.
Happy coding.
Source: https://habr.com/ru/post/108076/
All Articles