Regular Expression Search
What is important when developing a text editor? Of course, “equip” it with rich functionality and ensure stable operation. However, many will say that this is not enough for the project to be truly successful. You need to make it also “convenient” for the end user. And what is important when developing such a component as a text editor? Yes, perhaps the same, only it should be convenient not only for the end user, but also for the developer who will write an application based on it.
At first glance, it will not be easy to satisfy those and others - one needs a clear UI, equipped with a set of useful tools, others need an API that allows you to perform a wide range of tasks. However, often these tasks are related to each other.
In the course of developing and supporting the XtraRichEdit text editor , we have seen that some developers write a programming language editor based on it. The main requirement of such users was the ability to implement syntax highlighting. To do this, support for regular expression search is necessary to ensure that syntactic blocks and individual keywords can be extracted from the text.
')
At the same time, it is difficult to imagine an editor who does not provide a search by text. Of course, not every editor provides the ability to search for substrings by regular expressions, but “the poor one is an ordinary one who doesn’t dream of becoming a general,” so we relied on more “advanced” products like MS Word.
Implementing a regular expression search algorithm would take a lot of time, including debugging and testing. In order not to reinvent the wheel, we decided to use the implementation available in the .NET Framework.
At the same time, the main difficulty was that the content of the document in XtraRichEdit (as well as in most text editors) is represented not just by a string, but by a collection of objects representing text fragments with uniform formatting.
A .NET RegEx accepts a string as input and only a string (which prevented me from doing something like an IEnumerable <char> as an input is still a mystery to me. As a result, even a search by a regular expression in Stream becomes a headache).
But even having received the contents of the document in the form of a string (which is not very difficult), it is quite difficult to convert the result of the search in the position of the document model. This is due to the presence in the document of hidden characters and text that may not be displayed, but be represented in the overall structure of the document.
However, we found a way out. The main idea was as follows: a fragment of the document is extracted into the buffer and stored as a string (Fig. 1). Dealing with a small fragment of the document and knowing the buffer offset relative to the beginning of the search in absolute value (taking into account the hidden text), it is easy to determine the position of the found substring.
In addition, this is done without having to extract the entire document into a string (which affects the performance of the application quite strongly), the search speed increases. Regular expression matching is performed within this buffer. If no match is found, the buffer is shifted relative to the document by a certain length — the offset value (Fig. 2) and the search is performed again.

Fig. one.
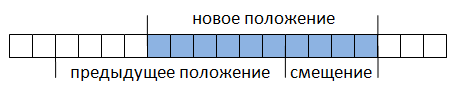
Fig. 2
The size of the buffer and the offset depend on the possible length of the search result, i.e. the maximum length of the largest result should not exceed the length of the buffer. The found match is considered to be sought in the following cases:
A non-zero offset indicates that the result was not found in the previous buffer position, therefore, the result lying at the beginning of the buffer was obtained by cutting the search string during the offset (Fig. 3).
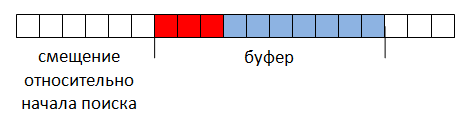
Fig. 3
The result that lies at the end of the buffer is discarded for the same reason: the search string is limited by the buffer size and the actual result can cross the buffer boundary.
Let's give an example. There is a line - “DevExpress is a great company!” . The contents of the buffer at the moment - “press is a gre” (Fig. 4).

Fig. four.
Let it be necessary to find all words whose length is greater than or equal to three characters. The regular expression in this case should be: “\ b \ w {3,} \ b” . Having made a search, we get the first match - “press” . It fully satisfies the desired expression, but is not the result. Looking for the next match gives us “gre” , which is also not the result. If the buffer offset value is four characters, then the next value of the buffer corresponds to the substring “s is a great c” . The search result “great” is in the middle of the buffer and fully corresponds to the regular expression and therefore can be considered the desired result.
We now consider the case when the result found lies at the beginning of the buffer and the buffer offset is zero. In which case this result can be considered the desired one? Obviously, if the beginning of the search interval coincides with the beginning of the document. If this is not the case, then an additional check is needed to see if the result does not cross the search interval boundary. To do this, before starting the search, shift the left border of the interval one character to the left. If the result found is at the beginning of the offset search interval, then this result is not the desired one. The same check must be made with the result adjacent to the right edge of the search interval.
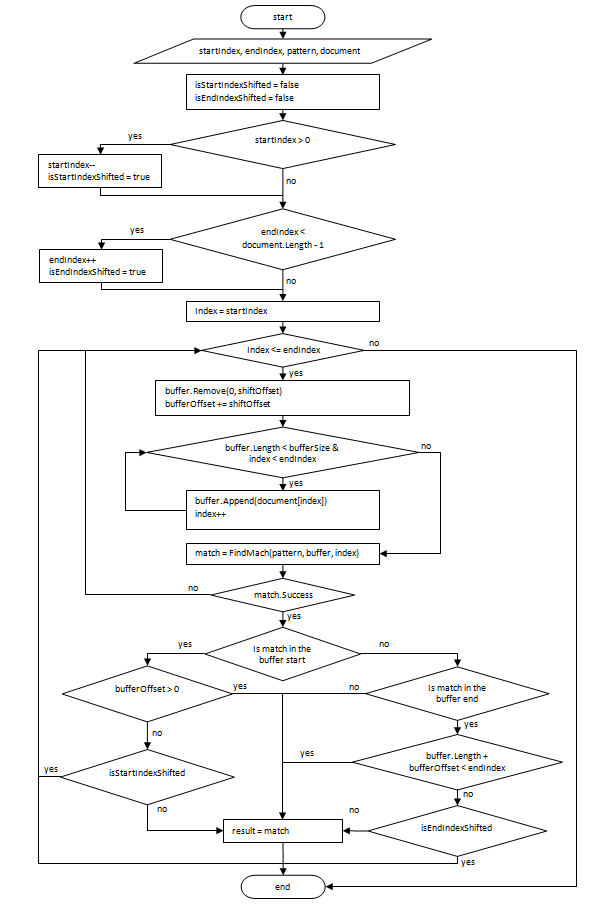
A block diagram of the search algorithm is presented below.
Input parameters:
Using this algorithm, you can make the implementation of a search for regular expressions in a document, represented not by a string, but by a collection of arbitrary objects. In this case, the mechanism does not require the implementation of the algorithm "from scratch" and the use of third-party libraries.
At first glance, it will not be easy to satisfy those and others - one needs a clear UI, equipped with a set of useful tools, others need an API that allows you to perform a wide range of tasks. However, often these tasks are related to each other.
In the course of developing and supporting the XtraRichEdit text editor , we have seen that some developers write a programming language editor based on it. The main requirement of such users was the ability to implement syntax highlighting. To do this, support for regular expression search is necessary to ensure that syntactic blocks and individual keywords can be extracted from the text.
')
At the same time, it is difficult to imagine an editor who does not provide a search by text. Of course, not every editor provides the ability to search for substrings by regular expressions, but “the poor one is an ordinary one who doesn’t dream of becoming a general,” so we relied on more “advanced” products like MS Word.
Implementing a regular expression search algorithm would take a lot of time, including debugging and testing. In order not to reinvent the wheel, we decided to use the implementation available in the .NET Framework.
At the same time, the main difficulty was that the content of the document in XtraRichEdit (as well as in most text editors) is represented not just by a string, but by a collection of objects representing text fragments with uniform formatting.
A .NET RegEx accepts a string as input and only a string (which prevented me from doing something like an IEnumerable <char> as an input is still a mystery to me. As a result, even a search by a regular expression in Stream becomes a headache).
But even having received the contents of the document in the form of a string (which is not very difficult), it is quite difficult to convert the result of the search in the position of the document model. This is due to the presence in the document of hidden characters and text that may not be displayed, but be represented in the overall structure of the document.
However, we found a way out. The main idea was as follows: a fragment of the document is extracted into the buffer and stored as a string (Fig. 1). Dealing with a small fragment of the document and knowing the buffer offset relative to the beginning of the search in absolute value (taking into account the hidden text), it is easy to determine the position of the found substring.
In addition, this is done without having to extract the entire document into a string (which affects the performance of the application quite strongly), the search speed increases. Regular expression matching is performed within this buffer. If no match is found, the buffer is shifted relative to the document by a certain length — the offset value (Fig. 2) and the search is performed again.
Fig. one.
Fig. 2
The size of the buffer and the offset depend on the possible length of the search result, i.e. the maximum length of the largest result should not exceed the length of the buffer. The found match is considered to be sought in the following cases:
- the result lies at the beginning of the buffer, provided that the position of the buffer relative to the beginning of the search is zero
- the result lies in the middle of the buffer.
A non-zero offset indicates that the result was not found in the previous buffer position, therefore, the result lying at the beginning of the buffer was obtained by cutting the search string during the offset (Fig. 3).
Fig. 3
The result that lies at the end of the buffer is discarded for the same reason: the search string is limited by the buffer size and the actual result can cross the buffer boundary.
Let's give an example. There is a line - “DevExpress is a great company!” . The contents of the buffer at the moment - “press is a gre” (Fig. 4).
Fig. four.
Let it be necessary to find all words whose length is greater than or equal to three characters. The regular expression in this case should be: “\ b \ w {3,} \ b” . Having made a search, we get the first match - “press” . It fully satisfies the desired expression, but is not the result. Looking for the next match gives us “gre” , which is also not the result. If the buffer offset value is four characters, then the next value of the buffer corresponds to the substring “s is a great c” . The search result “great” is in the middle of the buffer and fully corresponds to the regular expression and therefore can be considered the desired result.
We now consider the case when the result found lies at the beginning of the buffer and the buffer offset is zero. In which case this result can be considered the desired one? Obviously, if the beginning of the search interval coincides with the beginning of the document. If this is not the case, then an additional check is needed to see if the result does not cross the search interval boundary. To do this, before starting the search, shift the left border of the interval one character to the left. If the result found is at the beginning of the offset search interval, then this result is not the desired one. The same check must be made with the result adjacent to the right edge of the search interval.
A block diagram of the search algorithm is presented below.
Input parameters:
- pattern is a regular expression;
- shiftOffset - the size of the buffer offset at each step, the costant;
- bufferOffset - offset of the buffer relative to the start of the search;
- document - an object representing the document;
- startIndex, endIndex - search boundaries;
Using this algorithm, you can make the implementation of a search for regular expressions in a document, represented not by a string, but by a collection of arbitrary objects. In this case, the mechanism does not require the implementation of the algorithm "from scratch" and the use of third-party libraries.
Source: https://habr.com/ru/post/107733/
All Articles