Successful branching model for Git
Translation of the article by Vincent Driessen: A successful Git branching model
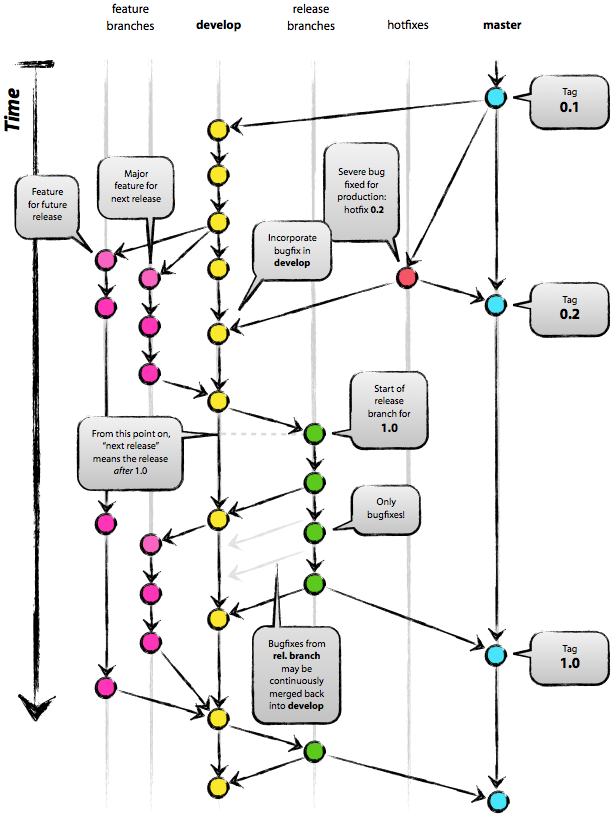
In this article, I present a development model that I use for all my projects (both working and private) for a year, and which has shown itself to be a good one. I was going to write about her for a long time, but still have not found free time. I will not talk about all the details of the project, I will touch only the branching strategy and release management.
')
As a tool for managing the version of the entire source code, it uses Git .
For a full discussion of all the advantages and disadvantages of Git versus centralized version control systems, contact the worldwide network . There you will find a sufficient amount of controversy on this topic. Personally, as a developer, I currently prefer Git to all other tools. Git really was able to change the attitude of developers towards merging and branching. In the classic world, CVS / Subversion, from which I came, branching and merging are usually considered dangerous (“beware of merge conflicts, they bite painfully!”) And therefore are held as little as possible.
But with Git, these actions are extremely simple and cheap, and therefore, in fact, they become central elements of the usual daily workflow. Just compare: in the CVS / Subversion books , branching and merging are usually covered in the last chapters (for advanced users), while in any Git book they are already mentioned for the third chapter (basics).
Because of their simplicity and predictability, branching and merging are no longer actions to be feared. Now versioning tools can help branch and merge more than any other.
But stop talking about tools, let's move on to the development model. The model I want to present is, in essence, just a set of procedures that each team member executes, so that everyone can achieve high controllability of the development process.
The proposed branch model is based on a project configuration that contains one central “true” repository. Note that this repository is only considered central (since Git is DVCS, it does not have such a thing as a main repository at a technical level). We will call this repository the term origin, since This name is so familiar to all Git users.
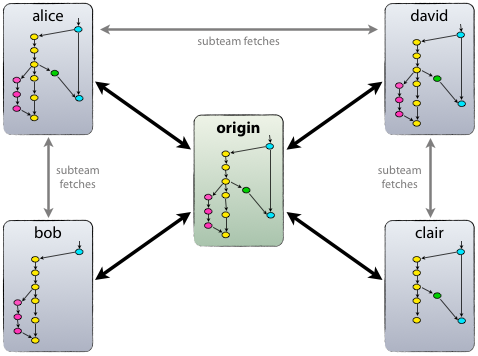
Each developer takes and publishes changes (pull & push) to origin. But, in addition to the centralized push-pull relationship, each developer can also pick up changes from the rest of the colleagues within his micro-team. For example, this method may be convenient in a situation where two or more developers are working together on a great new feature, but cannot publish an unfinished work to origin ahead of time. The picture above shows the subgroups of Alice and Bob, Alice and David, Claire and David.
Technically, this is easy to implement: Alice creates a remote Git branch called bob that points to Bob’s repository, and Bob does the same with hers repository.
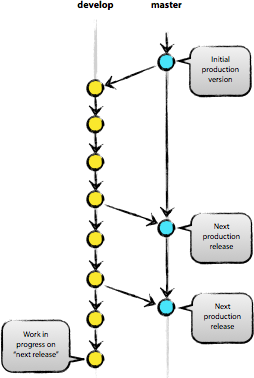
The core of the development model is no different from most existing models. The central repository contains two main branches that exist all the time.
The master branch is created when the repository is initialized, which should be familiar to every Git user. In parallel, we also create a branch for the development called develop.
We consider origin / master as the main branch. That is, the source code in it must be in a production-ready state at any arbitrary point in time.
We consider the origin / develop branch as the main branch for development. The code stored in it at any time should contain the most recent changes made necessary for the next release. This branch can also be called "integration". It serves as a source for building automatic night builds.
When the source code in the develop branch reaches a stable state and is ready for release, all changes must be merged into the master branch in a certain way and tagged with the release number. Below we look at this process in detail.
Therefore, each time changes change into the master branch, we get a new release by definition . We try to treat this rule very strictly, so, in principle, we could use Git hooks to automatically collect our products and upload them to the working servers at each commit to the master branch.
In addition to the main master and develop branches, our development model contains a number of types of auxiliary branches, which are used to parallelize development between team members, to simplify the introduction of new features (features), to prepare releases and to quickly fix problems in the production version of the application. Unlike the main branches, these branches always have a limited lifespan. Each of them eventually ends sooner or later.
We use the following types of branches:
Each type of branch has its own specific purpose and strict set of rules, from which branches they can be generated, and which ones should be merged. Now we consider them in turn.
Of course, from a technical point of view, these branches have nothing “specific”. The division of branches into categories exists only in terms of how they are used. In all other respects, these are the good old branches of Git.
May originate from: develop
Should be poured into: develop
Naming convention: everything except master, develop, release- * or hotfix- *
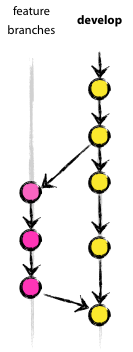
The branches of functionality (feature branches), also sometimes called thematic branches (topic branches), are used to develop new functions that should appear in current or future releases. At the beginning of work on the functionality (features) it may still be unknown in which release it will be added. The meaning of the existence of a branch of functionality (feature branch) is that it lives for as long as the development of this functionality (feature) continues. When the work in the branch is completed, the latter is merged back into the main development branch (which means that the functionality will be added to the upcoming release) or deleted (in case of an unsuccessful experiment).
The branches of functionality (feature branches) usually exist in the repositories of developers, but not in the main repository (origin).
When starting work on a new functionality, a branch from the develop branch is developed.
Completed functionality (feature) merges back into the develop branch (development) and falls into the next release.
The --no-ff flag causes Git to always create a new commit object during a merge, even if the merge can be performed with the fast-forward algorithm. This allows you to not lose the information that the branch existed, and groups together all the changes. Compare:
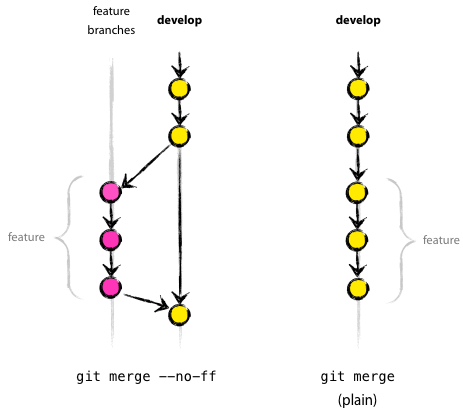
In the second case, it is impossible to see in the change history exactly which objects of the commits together form the functionality, for this you have to manually read all the messages in the commits. Abolishing the entire functionality (i.e., a group of commits) is then impossible without a headache, and with the --no-ff flag this is done elementary.
Of course, such an approach creates a certain additional amount of (empty) commit objects, but the benefit obtained more than justifies such a price.
Unfortunately, I have not yet found how to configure Git so that --no-ff is the default behavior for merges. But this method must be implemented.
May originate from: develop
Must join: develop and master
Naming convention: release- *
Release branches (release branches) are used to prepare for the release of new versions of the product. They allow you to place the final points on i before the release of a new version. In addition, they can add minor fixes, as well as prepare the metadata for the next release (version number, build date, etc.). When all of this work is placed in the release branch, the main development branch (develop) is cleared to add further features (which will be included in the next big release).
A new release branch should be spawned at the moment when the state of the development branch fully or almost fully meets the requirements of the new release. At least, all the necessary functionality intended for this release is already injected into the develop branch. The functionality intended for the following releases may not be infused. It is even better if the branches for these functionalities wait until the current release branch spans off from the develop branch.
The next release gets its version number only at the moment when a new branch is created for it, but by no means earlier. Up to this point, the development branch contains changes for the “new release”, but until the release branch is separated, it is not known whether this release will have version 0.3, or 1.0, or some other. The decision is made when creating a new release branch and depends on the rules adopted in the draft for numbering versions of the project.
The release branch is created from the develop branch. Let, for example, the current released release has version 1.1.5, and on the way a new big release, full of changes. The development branch (develop) is ready for the “next release”, and we decide that this release will be version 1.2 (and not 1.1.6 or 2.0). In this case, we create a new branch and give it a name corresponding to the new version of the project:
We created a new branch, switched to it, and then set the version number (bump version number). In our example, bump-version.sh is a fictional script that modifies some of the files in the working copy by writing a new version to them. (Of course, these changes can be made manually; I just draw your attention to the fact that some files are changed.) Then we make a commit with the indication of the new version of the project.
This new branch may exist for some time, until the new release is finally ready for release. During this time, corrections of found bugs can be added to this branch (and not to develop). But adding major new changes to this branch is strictly prohibited. They should always join the development branch (develop) and wait for the next big release.
When we decide that the release branch is finally ready for release, we need to do a few things. First of all, the release branch merges into the main branch (I remind you, every commit to master is, by definition, a new release). Further, this commit in master should be tagged so that you can easily access any existing version of the product in the future. Finally, changes made to the release branch must be added back to the development (the develop branch) so that future releases also contain bug fixes.
The first two steps in git:
Now the release is published and tagged.
Note : if you wish, you can also use the -s or -u <key> flags to sign the tag cryptographically.
To save changes in subsequent releases, we need to put these changes back into development. We do it like this:
This step, in principle, can lead to a merge conflict (it often happens that the cause of a conflict is a change in the version number of the project). If this happens, correct them and make a commit.
Now we have finally finished with the release branch. You can delete it because we no longer need it:

May be generated by: master
Must join: develop and master
Naming convention: hotfix- *
Hotfix branches are very similar to release branches, as they are also used to prepare new product releases, unless they are unplanned. They are caused by the need to immediately correct unwanted behavior of the production version of the product. When there is a bug in the production version that requires immediate correction, a new branch is generated from the corresponding master tag tag (master) to work on the fix.
The meaning of its existence is that the team’s work on the develop branch can continue quietly, while one prepares a quick fix for the production version.
Hotfix branches are created from the master branch. Let, for example, the current production release has version 1.2, and in it (suddenly!) A serious bug is detected. A change in the development branch (develop) is still not stable enough to publish them in a new release. But we can create a new branch of fixes and start working on solving the problem:
Do not forget to update the version number after creating a branch!
Now you can fix the bug, and publish the changes with at least one commit or at least a few.
When the bug is fixed, the changes need to be poured back into the main branch (master), as well as into the development branch (develop), to ensure that this fix will be in the next release. This is very similar to how a release branch closes.
First of all, you need to update the main branch (master) and mark the new version with a tag.
Note : if you wish, you can also use the -s or -u <key> flags to cryptographically sign the tag.
The next step is to transfer the fix to the develop branch.
There is one exception to this rule: if there is a release branch at the moment, the hotfix branch should be merged into it, not the develop branch . In this case, the fixes will be included in the development branch along with the entire release branch when it is closed. (Although, if work in develop requires an immediate correction of the bug and cannot wait until the current release is completed, you can still pour fixes (bugfix) into the develop branch, and it will be completely safe).
Finally, delete the temporary branch:
Although there is absolutely nothing fundamentally new in this branching model, the “big picture” that this article begins with has proven itself in our projects from the very best side. It forms an elegant mental model that is easy to fully cover with one glance, and which allows the team to form a joint understanding of the branching and merging processes that are involved in the project.
A high-quality PDF version of this picture is free for download here . Print it out and hang it on your wall so that you can access it at any time.
Note translator: the article is not new, the link to the original has already appeared on the site . This translation is for those to whom English is still not so easy (as well as for my colleagues, among whom I do propaganda, hehe). To automate the procedures described in this article, the author has created a gitflow project, which can be found on github .
In this article, I present a development model that I use for all my projects (both working and private) for a year, and which has shown itself to be a good one. I was going to write about her for a long time, but still have not found free time. I will not talk about all the details of the project, I will touch only the branching strategy and release management.
')
As a tool for managing the version of the entire source code, it uses Git .
Why git?
For a full discussion of all the advantages and disadvantages of Git versus centralized version control systems, contact the worldwide network . There you will find a sufficient amount of controversy on this topic. Personally, as a developer, I currently prefer Git to all other tools. Git really was able to change the attitude of developers towards merging and branching. In the classic world, CVS / Subversion, from which I came, branching and merging are usually considered dangerous (“beware of merge conflicts, they bite painfully!”) And therefore are held as little as possible.
But with Git, these actions are extremely simple and cheap, and therefore, in fact, they become central elements of the usual daily workflow. Just compare: in the CVS / Subversion books , branching and merging are usually covered in the last chapters (for advanced users), while in any Git book they are already mentioned for the third chapter (basics).
Because of their simplicity and predictability, branching and merging are no longer actions to be feared. Now versioning tools can help branch and merge more than any other.
But stop talking about tools, let's move on to the development model. The model I want to present is, in essence, just a set of procedures that each team member executes, so that everyone can achieve high controllability of the development process.
Decentralized but centralized
The proposed branch model is based on a project configuration that contains one central “true” repository. Note that this repository is only considered central (since Git is DVCS, it does not have such a thing as a main repository at a technical level). We will call this repository the term origin, since This name is so familiar to all Git users.
Each developer takes and publishes changes (pull & push) to origin. But, in addition to the centralized push-pull relationship, each developer can also pick up changes from the rest of the colleagues within his micro-team. For example, this method may be convenient in a situation where two or more developers are working together on a great new feature, but cannot publish an unfinished work to origin ahead of time. The picture above shows the subgroups of Alice and Bob, Alice and David, Claire and David.
Technically, this is easy to implement: Alice creates a remote Git branch called bob that points to Bob’s repository, and Bob does the same with hers repository.
Main branches
The core of the development model is no different from most existing models. The central repository contains two main branches that exist all the time.
- master
- develop
The master branch is created when the repository is initialized, which should be familiar to every Git user. In parallel, we also create a branch for the development called develop.
We consider origin / master as the main branch. That is, the source code in it must be in a production-ready state at any arbitrary point in time.
We consider the origin / develop branch as the main branch for development. The code stored in it at any time should contain the most recent changes made necessary for the next release. This branch can also be called "integration". It serves as a source for building automatic night builds.
When the source code in the develop branch reaches a stable state and is ready for release, all changes must be merged into the master branch in a certain way and tagged with the release number. Below we look at this process in detail.
Therefore, each time changes change into the master branch, we get a new release by definition . We try to treat this rule very strictly, so, in principle, we could use Git hooks to automatically collect our products and upload them to the working servers at each commit to the master branch.
Auxiliary branches
In addition to the main master and develop branches, our development model contains a number of types of auxiliary branches, which are used to parallelize development between team members, to simplify the introduction of new features (features), to prepare releases and to quickly fix problems in the production version of the application. Unlike the main branches, these branches always have a limited lifespan. Each of them eventually ends sooner or later.
We use the following types of branches:
- Feature branches
- Release branches
- Fixes (Hotfix branches)
Each type of branch has its own specific purpose and strict set of rules, from which branches they can be generated, and which ones should be merged. Now we consider them in turn.
Of course, from a technical point of view, these branches have nothing “specific”. The division of branches into categories exists only in terms of how they are used. In all other respects, these are the good old branches of Git.
Feature branches
May originate from: develop
Should be poured into: develop
Naming convention: everything except master, develop, release- * or hotfix- *
The branches of functionality (feature branches), also sometimes called thematic branches (topic branches), are used to develop new functions that should appear in current or future releases. At the beginning of work on the functionality (features) it may still be unknown in which release it will be added. The meaning of the existence of a branch of functionality (feature branch) is that it lives for as long as the development of this functionality (feature) continues. When the work in the branch is completed, the latter is merged back into the main development branch (which means that the functionality will be added to the upcoming release) or deleted (in case of an unsuccessful experiment).
The branches of functionality (feature branches) usually exist in the repositories of developers, but not in the main repository (origin).
Creating a branch of functionality (feature branch)
When starting work on a new functionality, a branch from the develop branch is developed.
$ git checkout -b myfeature develop
Switched to a new branch "myfeature"Adding completed functionality to develop
Completed functionality (feature) merges back into the develop branch (development) and falls into the next release.
$ git checkout develop
Switched to branch 'develop'
$ git merge --no-ff myfeature
Updating ea1b82a..05e9557
( )
$ git branch -d myfeature
Deleted branch myfeature (was 05e9557).
$ git push origin developThe --no-ff flag causes Git to always create a new commit object during a merge, even if the merge can be performed with the fast-forward algorithm. This allows you to not lose the information that the branch existed, and groups together all the changes. Compare:
In the second case, it is impossible to see in the change history exactly which objects of the commits together form the functionality, for this you have to manually read all the messages in the commits. Abolishing the entire functionality (i.e., a group of commits) is then impossible without a headache, and with the --no-ff flag this is done elementary.
Of course, such an approach creates a certain additional amount of (empty) commit objects, but the benefit obtained more than justifies such a price.
Unfortunately, I have not yet found how to configure Git so that --no-ff is the default behavior for merges. But this method must be implemented.
Release branches
May originate from: develop
Must join: develop and master
Naming convention: release- *
Release branches (release branches) are used to prepare for the release of new versions of the product. They allow you to place the final points on i before the release of a new version. In addition, they can add minor fixes, as well as prepare the metadata for the next release (version number, build date, etc.). When all of this work is placed in the release branch, the main development branch (develop) is cleared to add further features (which will be included in the next big release).
A new release branch should be spawned at the moment when the state of the development branch fully or almost fully meets the requirements of the new release. At least, all the necessary functionality intended for this release is already injected into the develop branch. The functionality intended for the following releases may not be infused. It is even better if the branches for these functionalities wait until the current release branch spans off from the develop branch.
The next release gets its version number only at the moment when a new branch is created for it, but by no means earlier. Up to this point, the development branch contains changes for the “new release”, but until the release branch is separated, it is not known whether this release will have version 0.3, or 1.0, or some other. The decision is made when creating a new release branch and depends on the rules adopted in the draft for numbering versions of the project.
Creating a release branch
The release branch is created from the develop branch. Let, for example, the current released release has version 1.1.5, and on the way a new big release, full of changes. The development branch (develop) is ready for the “next release”, and we decide that this release will be version 1.2 (and not 1.1.6 or 2.0). In this case, we create a new branch and give it a name corresponding to the new version of the project:
$ git checkout -b release-1.2 develop
Switched to a new branch "release-1.2"
$ ./bump-version.sh 1.2
Files modified successfully, version bumped to 1.2.
$ git commit -a -m "Bumped version number to 1.2"
[release-1.2 74d9424] Bumped version number to 1.2
1 files changed, 1 insertions(+), 1 deletions(-)We created a new branch, switched to it, and then set the version number (bump version number). In our example, bump-version.sh is a fictional script that modifies some of the files in the working copy by writing a new version to them. (Of course, these changes can be made manually; I just draw your attention to the fact that some files are changed.) Then we make a commit with the indication of the new version of the project.
This new branch may exist for some time, until the new release is finally ready for release. During this time, corrections of found bugs can be added to this branch (and not to develop). But adding major new changes to this branch is strictly prohibited. They should always join the development branch (develop) and wait for the next big release.
Release branch closure
When we decide that the release branch is finally ready for release, we need to do a few things. First of all, the release branch merges into the main branch (I remind you, every commit to master is, by definition, a new release). Further, this commit in master should be tagged so that you can easily access any existing version of the product in the future. Finally, changes made to the release branch must be added back to the development (the develop branch) so that future releases also contain bug fixes.
The first two steps in git:
$ git checkout master
Switched to branch 'master'
$ git merge --no-ff release-1.2
Merge made by recursive.
( )
$ git tag -a 1.2Now the release is published and tagged.
Note : if you wish, you can also use the -s or -u <key> flags to sign the tag cryptographically.
To save changes in subsequent releases, we need to put these changes back into development. We do it like this:
$ git checkout develop
Switched to branch 'develop'
$ git merge --no-ff release-1.2
Merge made by recursive.
( )This step, in principle, can lead to a merge conflict (it often happens that the cause of a conflict is a change in the version number of the project). If this happens, correct them and make a commit.
Now we have finally finished with the release branch. You can delete it because we no longer need it:
$ git branch -d release-1.2
Deleted branch release-1.2 (was ff452fe).Hotfix Branches
May be generated by: master
Must join: develop and master
Naming convention: hotfix- *
Hotfix branches are very similar to release branches, as they are also used to prepare new product releases, unless they are unplanned. They are caused by the need to immediately correct unwanted behavior of the production version of the product. When there is a bug in the production version that requires immediate correction, a new branch is generated from the corresponding master tag tag (master) to work on the fix.
The meaning of its existence is that the team’s work on the develop branch can continue quietly, while one prepares a quick fix for the production version.
Create hotfix branch
Hotfix branches are created from the master branch. Let, for example, the current production release has version 1.2, and in it (suddenly!) A serious bug is detected. A change in the development branch (develop) is still not stable enough to publish them in a new release. But we can create a new branch of fixes and start working on solving the problem:
$ git checkout -b hotfix-1.2.1 master
Switched to a new branch "hotfix-1.2.1"
$ ./bump-version.sh 1.2.1
Files modified successfully, version bumped to 1.2.1.
$ git commit -a -m "Bumped version number to 1.2.1"
[hotfix-1.2.1 41e61bb] Bumped version number to 1.2.1
1 files changed, 1 insertions(+), 1 deletions(-)Do not forget to update the version number after creating a branch!
Now you can fix the bug, and publish the changes with at least one commit or at least a few.
$ git commit -m "Fixed severe production problem"
[hotfix-1.2.1 abbe5d6] Fixed severe production problem
5 files changed, 32 insertions(+), 17 deletions(-)Close the patch branch
When the bug is fixed, the changes need to be poured back into the main branch (master), as well as into the development branch (develop), to ensure that this fix will be in the next release. This is very similar to how a release branch closes.
First of all, you need to update the main branch (master) and mark the new version with a tag.
$ git checkout master
Switched to branch 'master'
$ git merge --no-ff hotfix-1.2.1
Merge made by recursive.
( )
$ git tag -a 1.2.1Note : if you wish, you can also use the -s or -u <key> flags to cryptographically sign the tag.
The next step is to transfer the fix to the develop branch.
$ git checkout develop
Switched to branch 'develop'
$ git merge --no-ff hotfix-1.2.1
Merge made by recursive.
( )There is one exception to this rule: if there is a release branch at the moment, the hotfix branch should be merged into it, not the develop branch . In this case, the fixes will be included in the development branch along with the entire release branch when it is closed. (Although, if work in develop requires an immediate correction of the bug and cannot wait until the current release is completed, you can still pour fixes (bugfix) into the develop branch, and it will be completely safe).
Finally, delete the temporary branch:
$ git branch -d hotfix-1.2.1
Deleted branch hotfix-1.2.1 (was abbe5d6).Conclusion
Although there is absolutely nothing fundamentally new in this branching model, the “big picture” that this article begins with has proven itself in our projects from the very best side. It forms an elegant mental model that is easy to fully cover with one glance, and which allows the team to form a joint understanding of the branching and merging processes that are involved in the project.
A high-quality PDF version of this picture is free for download here . Print it out and hang it on your wall so that you can access it at any time.
Note translator: the article is not new, the link to the original has already appeared on the site . This translation is for those to whom English is still not so easy (as well as for my colleagues, among whom I do propaganda, hehe). To automate the procedures described in this article, the author has created a gitflow project, which can be found on github .
Source: https://habr.com/ru/post/106912/
All Articles