Future OpenSIPS Design
Foreword
OpenSIPS is a signaling SIP switch. If you really want to handle a lot of SIP-calls, then, most likely, you will not pass by OpenSIPS.
The system is really "mature", tested in battle and, over time, overgrown with many useful (and not very) modules.
At the same time, it is obvious that the architecture, laid back in 2001, does not meet modern requirements.
Therefore, the developers of OpenSIPS said that version 2.0 will be maintained "from scratch".
The following is a translation of the OpenSIPS 2.0 Design document. I wonder what the habrasoobschestvo thinks about this.
')
Comments on the merits, I will try to convey to the developers.
Why do we need a new architecture
The current OpenSIPS architecture (prior to version 2.0) is based on concepts that are over 7 years old. At that time, the requirements were simple (a simple stateless SIP proxy, only UDP) and decisions were made in accordance with these requirements. But with all the additions, both in SIP and functionality (such as TCP / TLS, script manipulation, dialog support, integration with external systems, etc.), the existing architecture can no longer meet the requirements and actual usage scenarios.
Attention! Inside a large and structured text with pictures.
The problems that the new architecture is designed to solve:
- I / O locks (transport, DB, applications)
- Scaling with hardware resources (I / O and synchronization of parallel processes are a bottleneck in the current architecture)
- When designing a configuration, one has to deal with low-level functions (TM, dialogs, NAT) instead of focusing on the logic of service provision.
- Horizontal scaling (both kernel and routing logic)
- The routing mechanism (in the form of a specialized programming language) has a very limited set of non-SIP capabilities (integration with other applications, complex logic of the routing script, working with arrays and lists, support for complex operations and data types) and requires additional skills from the administrator.
- The routing mechanism is too closely tied to the SIP stack, which makes it impossible to change it on the fly without restarting OpenSIPS.
- Unable to do distributed routing between multiple systems (to improve scalability).
Overview of the new architecture
The new architecture was developed taking into account the problems and successful solutions in the current architecture, and also takes into account the development directions of SIP and OpenSIPS.
At the top level, OpenSIPS will consist of two completely independent parts:
- SIP core (SIP-core) - provides support for low-level operations with SIP
- Routing Engine (Routing Engine) - is responsible for high-level routing logic
It is assumed that several routing servers will be able to connect to the same core in order to implement different functionalities, or simply to increase the capacity of the system as a whole.
SIP core
The kernel is a low-level component that provides the functionality associated with SIP. They can run automatically and do not require complex configuration. Core will be responsible for the transport layer, packet analysis, transactions and dialogs, automatic support for passing through NAT, SIP registrations and online statuses (presences), functions that are clearly defined in the RFC and do not require any intervention from the high-level Subsystem routing.
The kernel is divided into several horizontal levels, each of which performs certain functions:
- L 0 - Transport layer. Implements support for UDP, TCP, TLS, SCTP and hides all the specific features for transport
- L 1 - SIP parser layer (SIP parser layer). Responsible for parsing SIP messages
- L 2 - Transaction Level - implements support for SIP transactions. Each incoming SIP message is associated with a SIP transaction.
- L 3 - Dialog Level - implements support for SIP dialogs. SIP message can be associated with SIP dialogue
- L 4 - Pass through NAT level - automatic handler for passing through NAT (support at the level of SIP signaling and transport)
- L 5 - Level of support of online statuses (presence) - implements the SIP Presence Agent. Automatic processing of messages related to online statuses.
- L 6 and up ... as needed, other levels can be added (such as user location).
- L p - the last level is the level that provides interaction with the Routing Engine (via API or socket)
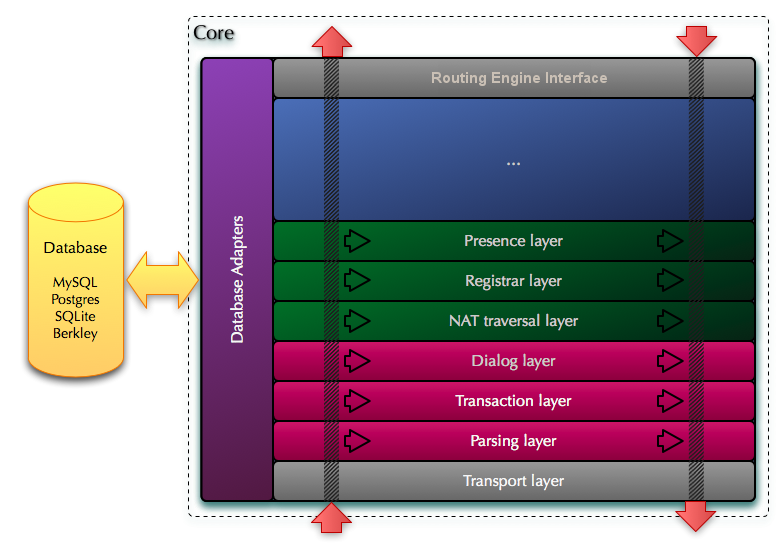
Core structure
SIP message arrives at the lower level L 0 . Each level processes the message and either passes it to the next level or returns it to the level below. If a return occurs, it means that the message processing is finished at this level (for example, this is how automatic responses to KeepAlive messages or resending packets work). When a message reaches the layer that provides interaction with the routing server, the message is transmitted (with all the changes that were made at each level) to the routing server, which continues further processing of the message. Then the message is returned back along the path that goes from top to bottom from level to level until it reaches the transport level (L 0 ) and is not sent to the network.
The kernel has two message flows:
- Incoming flow (from bottom to top) - the incoming message is sent up, being subjected to changes at each level, until it reaches a place where a decision can be made about what to do with the message (this can be either in one of the Kernel levels or in the Routing Subsystem ).
- Outgoing flow (from top to bottom) - when the decision about what to do with the message is made, the message goes back through all the layers that it passed until it is sent to the network.
In both flows, each level can perform different actions (for example, the SIP analyzer level parses messages from the incoming stream and collects them back, putting them into the outgoing stream).
SIP messages are read from the network to the network by the L 0 level (transport layer), and then they are transmitted to higher levels. Each layer performs the appropriate actions: for example, the SIP analyzer level will add parsed data to the message, the transaction level will add the transaction identifier, the dialog level will add the dialogue identifier, etc. After completing its task, a level can: (a) send a message to a higher level for processing (if the current level cannot complete processing) or (b) decide what to do with the message and transfer the message to the outgoing stream for sending (in this case , all higher levels will be skipped).
This algorithm provides the most efficient processing of messages at each level. It is not necessary to pass all messages through all levels up to the Routing Subsystem if the message can be processed automatically using lower levels. For example, responses to keepalive messages can be automatically processed by the Kernel at the L4 level (passing through NAT). Another example is when the Routing Subsystem is only interested in receiving and processing initial requests. In this case, subsequent requests will be automatically processed and routed using the level of the dialogs without the need to pass them further along the chain.
In addition to the tiers, the Kernel also implements several database backends. They are used to save between restarts of internal data that each of the levels of the Kernel stores in memory (dialogs, online statuses, registrations, information for passing through NAT).
Inside the Core, levels can be divided by importance:
- Base core - includes mandatory levels (L 0 -L 3 and L n ). They provide the features that are always required.
- Additional levels (L 4 - L n-1 ), which provide optional functions. They can be connected or disconnected during operation.
The kernel has its own configuration file, which contains parameters for the main levels and backends of the databases: what network interfaces to listen on, transaction parameters, dialog parameters, etc.
The kernel is implemented as an asynchronous reactor that supports non-blocking I / O. For efficient use of resources on machines with multi-core processors, the Kernel uses several threads (by the number of CPU cores).
Routing Engine
The routing subsystem performs routing, for which the configuration script is responsible for the current version of OpenSIPS, and provides the functionality of most of the currently existing modules.
The routing subsystem runs on top of the kernel as a separate component. As mentioned earlier, several Routing Subsystems can be connected to a single Core, either for implementing various services or to increase system capacity by distributing the load across several physical machines.
The new design allows you to use two approaches to connect the kernel with the routing subsystem:
- The routing logic is in the form of a library, which is closely related to the Core, and implements several additional levels and modules on top of the Core. They are interconnected within a single executable file.
- Routing logic in the form of an external application that communicates with the kernel using a socket. This application can be written in a high level language such as Python or Java.
Why use two approaches? These two options do not exclude, but complement each other - the internal Routing Server is more efficient in terms of performance and manageability (due to tight integration with the Core directly at the C level), while the external Routing Subsystem will be much more universal and easier to implement ( application in high level language), which is much easier to control.
Internal Routing Module
The routing module is a set of additional levels represented as a library that will be connected to the Core, forming a single application. The routing module includes:
- Script interpreter - for logic implementation
- Additional modules - to support ready-made functionality in the script
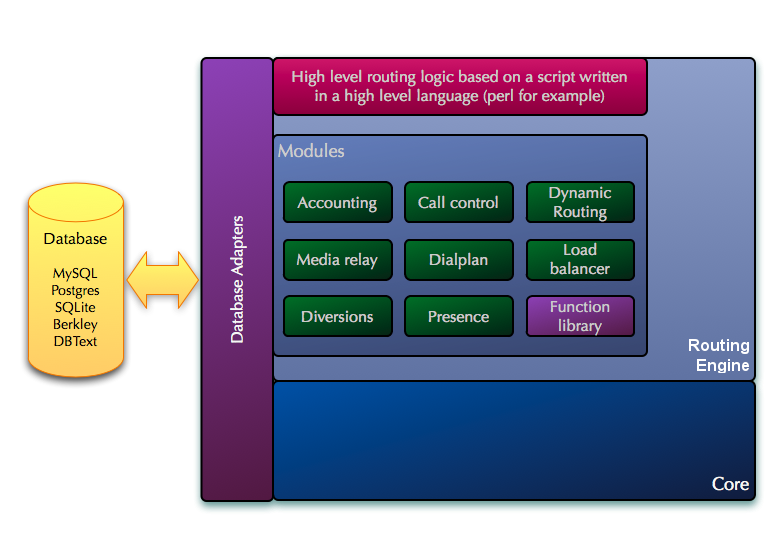
Internal routing subsystem
The script interpreter is based on an existing specialized language with the ability to directly insert blocks in a high-level language (for example, embedded Perl). Depending on the degree of impact on performance, you can completely replace a specialized script with a high-level language (for example, all the logic of the Routing Module should be written in Perl from which the functions of the Kernel or modules in C are called).
In the new architecture, it remains possible to use the existing native script, because its interpreter is very fast, and it is perfect for configurations with simple logic and copes well with high loads.
Embedding scripts in high-level languages also looks useful, as this solution greatly simplifies the implementation of scripts that require complex routing logic required, which can be implemented using high-level language features. In addition to reducing the complexity of writing complex scripts, this opportunity eliminates the need to learn a specialized built-in scripting language. However, in this case, there will be some performance degradation, since the interpreters of high-level languages are heavier and slower. On the other hand, the use of high-level languages will allow for horizontal scaling. Imagine an OpenSIPS cluster (on several servers), where all the Routing Subsystems (using the features of the high-level language and data storage technology) are connected to the network and behave as a single entity - like a global Routing Server that uses several OpenSIPS cores.
Routing subsystem modules that provide predefined functions (dialplan, LCR, QoS, B2BUA, etc.) can be used from a script, regardless of its format.
It is possible to reload the script during operation.
External routing subsystem
As well as the built-in, external Routing Subsystem (or application) is implemented as a set of levels through which messages pass in two directions (bottom to top and top to bottom). These layers are completed with a layer that implements the routing logic for a particular SIP service. The last layer is equivalent to the script used in the old architecture.
Some of the levels are active - this means that they change the messages during the transfer and may decide to stop relaying the messages to the top, complete processing and return the message to the bottom. This is done either by analyzing the content of the message, or based on instructions from the previous level of routing. Some other levels are passive. This means that they only provide classes and functions that implement certain capabilities (for example, LCR or call control), but they are not used for end-to-end transmission of messages between levels upward. They are called explicitly from the routing logic and change the message.
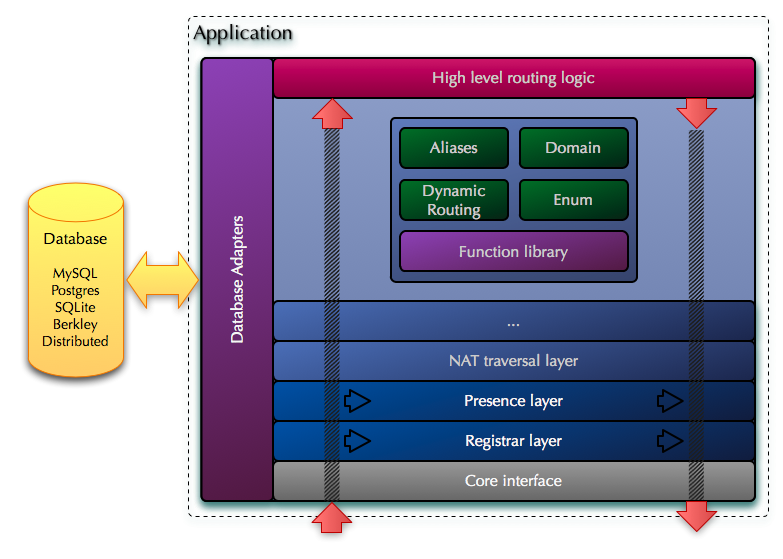
Routing subsystem as an application
An application registers with a specific Kernel (or on several Kernels, if necessary) and reports its capabilities to the Kernel. Features include messages that the Routing Subsystem and Restrictions are interested in. This allows the Kernel to filter which messages and how many to pass to this application. In addition, an application can request the kernel to dynamically enable / disable some of the optional levels of the kernel when the kernel decides that a message should be sent to this application. This allows you to create flexible configurations in which a particular application can, for example, tell the Kernel that for all messages that are sent to a particular application, disable the level of NAT passing. As a result, when the Kernel sends a message to this application, it will pass the level of access through NAT. This means that the application wants to deal with passing through NAT on its own. This also means that the application will receive keepalive messages. Other applications, if they have not disabled this level, will not see keepalive messages and will not solve the problem of passing through NAT, because the level of passing through NAT will be used. This allows you to get a very flexible configuration, where some of the optional Kernel levels can be turned on or off during runtime without having to change the Core configuration or reboot the Core.
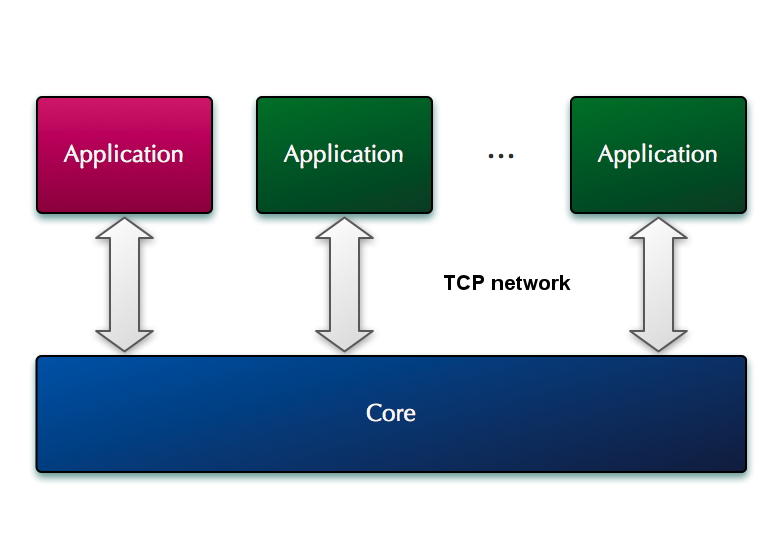
Multiple applications with one core
The entire application can be written in a high level language such as Python. The implementation in OpenSIPS will provide all the necessary functions that will allow the user to write high-level routing logic. This corresponds to the last level in the application diagram. This will resemble the existing script, only it will be written in the same language (Python in this case) as the rest of the application. Of course, the application can be implemented in other languages, such as Java, Ruby or Perl.
Each of us can help the OpenSIPS project.
Thanks for attention.
Source: https://habr.com/ru/post/106719/
All Articles