Building SIFT descriptors and image matching task

Small introduction
Let's begin with those cases when the problem of image matching is solved at all. I can list the following: creating panoramas, creating a stereo pair and reconstructing a three-dimensional model of an object from its two-dimensional projections in principle, recognizing objects and searching on a sample from some base, tracking the movement of an object through several images, reconstructing affine transformations of images. Perhaps I missed some use in this list or this application has not yet been invented, but, probably, it is already possible to get an idea of what range of tasks the use of descriptors is intended to solve. It should be noted that the area of knowledge that considers such tasks (computer vision) is quite young, with all the ensuing consequences. There is no specific universal method that solves all the problems listed above in full, i.e. for all input images. However, not everything is so bad, you just need to know that there are methods for solving various kinds of narrower tasks, and understand that a lot in choosing the method of solving a problem depends directly on the type of the problem itself, the type of objects and the nature of the scene where they are depicted personal preference.
Also, before reading, it will not be superfluous to look at the article on the SURF method diagonally.
General thoughts
A person can compare images and allocate objects to them visually, on an intuitive level. However, for a machine, an image is just a dummy data set. In general terms, two approaches can be described in order to somehow “endow” a machine with this human skill.
')
There are certain methods for comparing images based on a comparison of knowledge about images in general. In the general case, it looks like this: for each image point, the value of a certain function is calculated, on the basis of these values a certain characteristic can be attributed to the image, then the task of comparing images is reduced to the problem of comparing such characteristics. By and large, these methods are as bad as they are simple, and work reasonably, practically, only in ideal situations. There are plenty of reasons for this: the appearance of new objects in an image, the overlapping of some objects by others, noise, changes in scale, position of an object in an image, camera position in three-dimensional space, lighting, affine transformations, etc. Actually, the poor qualities of these methods are due to their main idea, i.e. so that each point of the image contributes to the characteristic, no matter how bad this contribution is.
The last phrase immediately suggests the idea of avoiding such problems: it is necessary or somehow to choose points that contribute to the characteristic, or, even better, to single out some special (key) points and compare them. This is where we come to the idea of matching images at key points. We can say that we replace the image with some model - a set of its key points. Immediately, we note that a particular point of the depicted object will be called, which with a high degree of probability will be found on another image of the same object. The detector will be called the method of extracting key points from the image. The detector should ensure the invariance of finding the same singular points with respect to image transformations.
The only thing that remains unclear is how to determine which key point of one image corresponds to the key point of another image. Indeed, after applying the detector, it is possible to determine only the coordinates of the singular points, and they are different on each image. This is where the descriptors come in. Descriptor - identifier of the key point, distinguishing it from the rest of the mass of singular points. In turn, descriptors should ensure the invariance of finding a correspondence between specific points with respect to image transformations.
The result is the following scheme for solving the image matching problem:
1. On the images are highlighted key points and their descriptors.
2. By coincidence of descriptors, key points corresponding to each other are highlighted.
3. Based on a set of matched key points, an image transformation model is built, with which you can get another from one image.
At each stage there are problems and different methods of solving them, which introduces a certain arbitrariness in the solution of the original problem. Next, we will consider the first part of the solution, namely the selection of singular points and their descriptors using the SIFT (Scale Invariant Feature Transform) method. The algorithm of the SIFT method will be mainly described, and not why this algorithm works, and it looks like that.
Lastly, we list some transformations for which we would like to obtain invariance:
1) offset
2) turn
3) scale (the same object can be of different sizes on different images)
4) changes in brightness
5) camera position changes
Invariance with respect to the last three transformations cannot be fully achieved, but at least partially it would not be bad to do it.
Finding special points
The main point in the detection of singular points is the construction of a pyramid of Gaussians (Gaussian) and differences of Gaussians (Difference of Gaussian, DoG). A Gaussian (or an image blurred by a Gaussian filter) is an image.

Here L is the value of the Gaussian at the point (x, y), and sigma is the blur radius. G is a Gaussian core, I is the value of the original image, * is a convolution operation.
The difference between gaussians is an image obtained by pixel-by-pixel subtraction of a single gaussin of the original image from a gaussian with a different radius.
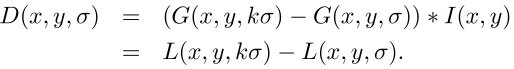
In a nutshell, let's talk about scalable spaces. Scalable image space is a set of various versions of the original image, smoothed by some filter. It is proved that the Gaussian scalable space is linear, invariant with respect to shifts, rotations, scale, not displacing local extremes, and has the property of semigroups. For us it is important that a different degree of image blur by a Gaussian filter can be taken as the original image, taken at a certain scale.
In general, scale invariance is achieved by finding the key points for the original image, taken at different scales. For this, a Gaussian pyramid is built: the entire scalable space is divided into several sections — octaves, with a part of the scalable space occupied by the next octave being twice as large as the part occupied by the previous one. In addition, when moving from one octave to another, the image is resampled, its dimensions are halved. Naturally, each octave covers an infinite number of Gaussian images, so only a certain number of them N are built, with a certain step along the blur radius. With the same step, two additional Gaussians are completed (a total of N + 2 is obtained), extending beyond the limits of the octave. Next, you will see why it is needed. The scale of the first image of the next octave is equal to the scale of the image from the previous octave number N.
In parallel with the construction of the pyramid of Gaussians, a pyramid of differences of Gaussians is constructed, consisting of the differences of neighboring images in the pyramid of Gaussians. Accordingly, the number of images in this pyramid will be N + 1.
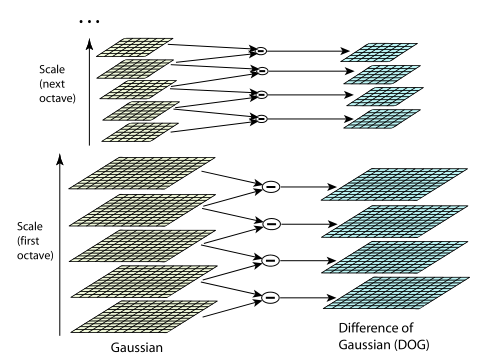
The figure on the left shows the pyramid of Gaussians, and on the right - their differences. It is schematically shown that each difference is obtained from two neighboring Gaussians, the number of differences is one less than the number of Gaussians; when going to the next octave, the size of the images is halved
After building the pyramids, the matter remains small. We consider a point to be special if it is a local extremum of the difference of Gaussians. To search for extremums we will use the method shown schematically in the figure.
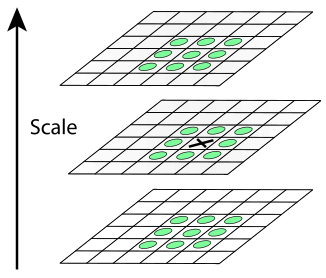
If the difference between the Gaussians at the point marked with a cross is more (less) than all the values at the points marked with circles, then this point is considered an extremum point.
In each image from the DoG pyramid, local extremum points are searched. Each point of the current DoG image is compared with its eight neighbors and with nine neighbors in the DoG that are one level higher and lower in the pyramid. If this point is more (less) than all the neighbors, then it is taken as a point of local extremum.
I think now it should be clear why we needed “extra” images in an octave. In order to check for the presence of points of the extremum N'e image in the DoG pyramid, you need to have N + 1'e. And in order to get N + 1'e in the DoG pyramid, you must have N + 1'e and N + 2'e images in the pyramid of Gaussians. Following the same logic, we can say that we need to build a 0'e image (to check the 1st'go) in the DoG pyramid and two more in the Gauss pyramid. But remembering that the 1'e image in the current octave has the same scale as the N'e in the previous one (which should already be checked), we can relax a bit and read more :)
Specification of singular points
Oddly enough, in the previous paragraph, the search for key points is not over. The next step will be a couple of tests of the suitability of the extremum point for the key role.
The first step is to determine the coordinates of the singular point with sub-pixel accuracy. This is achieved by approximating the DoG function by a second-order Taylor polynomial taken at the point of the calculated extremum.

Here D is the DoG function, X = (x, y, sigma) is the displacement vector with respect to the decomposition point, the first derivative of DoG is the gradient, the second derivative of DoG is the Hessian matrix.
The extremum of the Taylor polynomial is found by calculating the derivative and equating it to zero. As a result, we obtain the offset of the point of the calculated extremum, relative to the exact
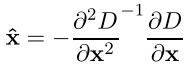
All derivatives are calculated using finite difference formulas. As a result, we obtain a SLAE of dimension 3x3, relative to the components of the vector X ^.
If one of the components of the vector X ^ is greater than 0.5 * grid_path_in_this_direction, then this means that in fact the extremum point was not calculated correctly and you need to move to the neighboring point in the direction of the indicated components. For the neighboring point, everything repeats. If in this way we went beyond the octave, then this point should be excluded from consideration.
When the position of the extremum point is calculated, the very DoG value at this point is checked by the formula

If this test fails, then the point is excluded, as a point with low contrast.
Finally, the last check. If a particular point lies on the border of an object or is poorly lit, then this point can be excluded from consideration. These points have a large bend (one of the components of the second derivative) along the boundary and small in the perpendicular direction. This large bend is determined by the Hessian matrix H. For verification, H size 2x2 is suitable.
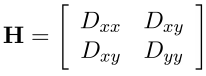
Let Tr (H) be the trace of a matrix, and Det (H) its determinant.
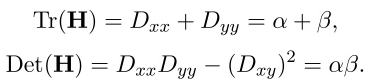
Let r be the ratio of a larger bend to a smaller one,

then
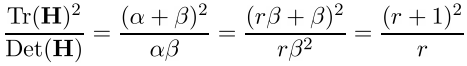
and the point is considered further if

Finding the orientation of the key point
After we have verified that a point is key, we need to calculate its orientation. As will be seen later, a point may have several directions.
The direction of the key point is calculated from the directions of the gradients of the points adjacent to the singular. All gradient calculations are performed on the image in the pyramid of Gaussians, with a scale closest to the scale of the key point. For reference: the magnitude and direction of the gradient at the point (x, y) are calculated by the formulas
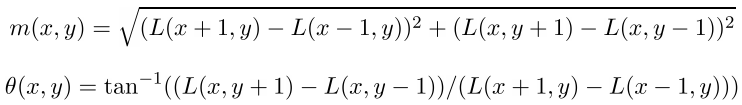
m is the magnitude of the gradient, theta is its direction
First, we define the window (neighborhood) of the key point, in which gradients will be considered. In essence, this will be the window required for convolution with a Gaussian core, and it will be round and the blur radius for this kernel (sigma) is 1.5 * key-point scale. For the Gaussian core, the so-called "three sigma" rule applies. It consists in the fact that the value of the Gaussian core is very close to zero at a distance greater than 3 * sigma. Thus, the radius of the window is defined as [3 * sigma].
The direction of the key point is found from the histogram of the O directions. The histogram consists of 36 components that evenly cover a gap of 360 degrees, and it is formed as follows: each point of the window (x, y) contributes equal to m * G (x, y, sigma ), into that component of the histogram that covers the gap containing the direction of the gradient theta (x, y).
The direction of the key point lies in the gap covered by the maximum component of the histogram. The values of the maximum component (max) and its two adjacent ones are interpolated by a parabola, and the maximum point of this parabola is taken as the direction of the key point. If there are more components in the histogram with values not less than 0.8 * max, then they are similarly interpolated and additional directions are assigned to a key point.
Building descriptors
We now turn directly to the descriptors. This earlier definition says what the descriptor should do, but not what it is. In principle, any object can act as a descriptor (as long as it copes with its functions), but usually the descriptor is some information about the neighborhood of the key point. This choice was made for several reasons: small areas are less affected by distortion effects, some changes (changing the position of an object in the picture, changing the scene, overlapping one object with another, turning) may not affect the descriptor at all.
In the SIFT method, the descriptor is a vector. Like the direction of the key point, the descriptor is computed on a Gaussian closest in scale to the key point, and based on the gradients in a certain key point window. Before calculating the descriptor, this window is rotated by the angle of the direction of the key point, which is how invariance with respect to rotation is achieved. To start, look at the picture.
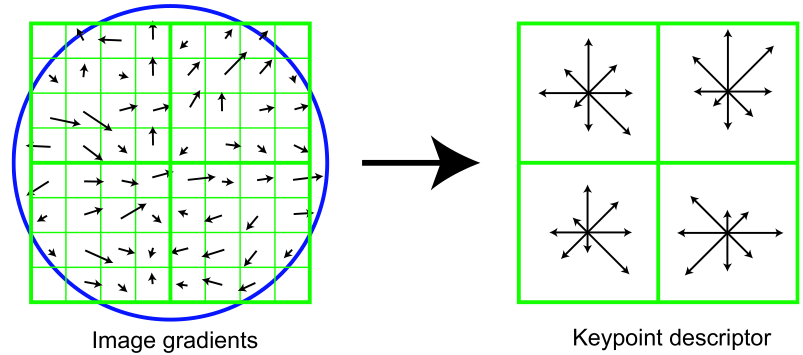
Here is a schematic representation of a part of the image (left) and (right) a handle derived from it. For a start, look left. Here you can see the pixels indicated by small squares. These pixels are taken from the square window of the descriptor, which in turn is divided into four equal parts (we will further call them regions). A small arrow in the center of each pixel indicates the gradient of that pixel. Interestingly, the center of this window is between the pixels. It should be chosen as close as possible to the exact coordinates of the key point. The last detail that can be seen is a circle denoting a convolution window with a Gaussian core (similar to the window for calculating the direction of the key point). For this kernel, a sigma is determined equal to half the width of the descriptor window. In the future, the value of each point in the descriptor window will be multiplied by the value of the Gaussian core at this point, as by a weighting factor.
Now we look to the right. Here we can see a schematically depicted descriptor of a singular point, dimension 2x2x8. The first two digits in the dimension value are the number of regions horizontally and vertically. Those squares that covered a certain region of pixels on the left of the images, on the right cover histograms built on the pixels of these regions. Accordingly, the third digit in the dimension of the descriptor means the number of components of the histogram of these regions. Regional histograms are calculated in the same way as a direction histogram with three small but:
1. Each histogram also covers a 360-degree section, but divides it into 8 parts.
2. The weight of the Gaussian nucleus is taken as the weighting factor, which is common to the entire descriptor (this has already been said)
3. For one more weight coefficients, the coefficients of trilinear interpolation are taken.
Three real coordinates (x, y, n) can be assigned to each gradient in the descriptor window, where x is the horizontal distance to the gradient, y is the vertical distance, n is the distance to the gradient direction in the histogram (meaning the corresponding histogram of the descriptor in which this gradient contributes). The bottom left corner of the descriptor window and the initial value of the histogram are taken as a point of reference. For single segments, the sizes of the regions are taken horizontally and vertically for x and y, respectively, and the number of degrees in the histogram component for n. The coefficient of trilinear interpolation is determined for each coordinate (x, y, n) of the gradient as 1-d, where d is equal to the distance from the coordinate of the gradient to the middle of the unit interval in which this coordinate falls. Each occurrence of a gradient in the histogram is multiplied by all three weights of the trilinear interpolation.
The key point descriptor consists of all the histograms obtained. As already mentioned, the dimension of the descriptor in Figure 32 is components (2x2x8), but in practice descriptors of dimension 128 are used (4x4x8).
The resulting descriptor is normalized, after which all its components, whose value is greater than 0.2, are truncated to a value of 0.2, and then the descriptor is normalized again. In this form, the descriptors are ready to use.
The last word and literature
SIFT descriptors are not without flaws. Not all points obtained and their descriptors will meet the requirements. Naturally, this will affect the further solution of the image matching problem. In some cases, a solution may not be found, even if it exists. For example, when searching for affine transformations (or a fundamental matrix) using two images of a brick wall, a solution may not be found due to the fact that the wall consists of repetitive objects (bricks) that make descriptors of different key points similar to each other. Despite this fact, these descriptors work well in many practically important cases.
Plus, this method is patented.
The article describes an approximate scheme of the SIFT algorithm. If you are interested in why this algorithm is what it is and why it works, as well as justifying the choice of the values of some parameters taken in the “from the ceiling” article (for example, the number 0.2 in the descriptor normalization), then you should refer to the original source
David G. Lowe "Distinctive image features from scale-invariant keypoints"
Another article, repeating the main content of the previous one. It highlights some of the details.
Yu Meng "Implementing the Scale Invariant Feature Transform (SIFT) Method"
Source: https://habr.com/ru/post/106302/
All Articles