What SVN can't
When SVN 1.5 was released, I remember that my colleagues and I were very happy about the long-awaited support for recording the transfer history of changes (merge), which until then we had written in the comments to the edits, and this, of course, strained us very much. To celebrate, various ideas began to come to our minds about how to use this new feature, and once we decided to implement with its help modularity at the source code level.
The idea was not to make separate libraries connected at runtime, as is usually done, but to allocate functionality reused in different projects into separate branches and transfer them to a new project if necessary.
We took the main branch of the platform, ransacked 5 pieces of modular branches from it, each of which added the functionality of one separate module and maintained their relevance by transferring changes from the trunk to them.
')
Everything went well. When we needed to build a distribution that included several specific modules, we forked a new project from the trunk and consistently transferred changes from the branches of the required modules to it.
But in the process of developing specific projects, we are faced with the need for improvements and corrections in their code, and both the main trunk code and the code of our pseudo-modules. Naturally, these useful changes needed to be transferred back to the trunk and branches of the modules so that they fell into future projects, which we did.
And here we are faced with an unexpected effect for us. SVN stores the history of changes pushed to a branch in the plain text property of the root folder. The property text is a list of branches from which changes were ever transferred to this one, indicating which revisions were transferred.
So, the main feature of the implementation of the mixing mechanism in SVN in our case is that with any transfer of any changes, even one small edit from one branch to another, ALL merge-story is also completely transferred with this edit.
And that's what happened with us. When transferring changes to the trunk from projects containing modules, records about the integration of these modules also fell on the trunk. And all the following projects branched off from the trunk have already refused to accept the code of the modules, considering that they have already received these changes earlier.
And we realized that SVN has one important limitation in our case, the meaning of which can be described as follows: it is impossible for closed paths to form in the paths of transfer of changes .
We tried to optimize these paths, inventing different rules, we divided the changes into classes and set separate rules for each of them, but finally realized that all this was too complicated and inconvenient, and we abandoned the idea of modularity that we liked at the source level, replacing its usual run-time modularity.
Recently, I have increasingly heard enthusiastic reviews from my acquaintances about distributed version control systems, in particular Mercurial and Git. And I had a question, is it possible to organize such a complex scheme for transferring changes on these systems?
I ask the people using the mentioned or other systems to tell whether it is possible to transfer changes along closed contours to them without the occurrence of the described problem? For example, in the following diagram, is it possible to make a merge-edit 8? And will the system block the attempt to re-transfer 9?
SVN, for example, will block both.
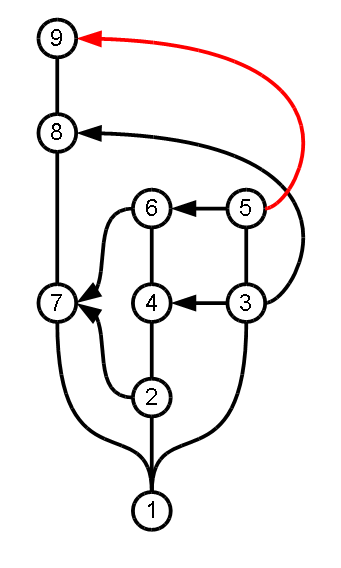
UP: tzlom says that Git will make both edits, and, naturally, in the 9th it will create a collision. In general, in SVN, you can also ignore blocking, and then the effect will be the same.
UP: PQR prompted Mercurial to edit the changes atomically using the Transplant extension and to Git using the cherry-pick command, but apparently both edits will be allowed in both cases (8 and 9).
The idea was not to make separate libraries connected at runtime, as is usually done, but to allocate functionality reused in different projects into separate branches and transfer them to a new project if necessary.
We took the main branch of the platform, ransacked 5 pieces of modular branches from it, each of which added the functionality of one separate module and maintained their relevance by transferring changes from the trunk to them.
')
Everything went well. When we needed to build a distribution that included several specific modules, we forked a new project from the trunk and consistently transferred changes from the branches of the required modules to it.
But in the process of developing specific projects, we are faced with the need for improvements and corrections in their code, and both the main trunk code and the code of our pseudo-modules. Naturally, these useful changes needed to be transferred back to the trunk and branches of the modules so that they fell into future projects, which we did.
And here we are faced with an unexpected effect for us. SVN stores the history of changes pushed to a branch in the plain text property of the root folder. The property text is a list of branches from which changes were ever transferred to this one, indicating which revisions were transferred.
So, the main feature of the implementation of the mixing mechanism in SVN in our case is that with any transfer of any changes, even one small edit from one branch to another, ALL merge-story is also completely transferred with this edit.
And that's what happened with us. When transferring changes to the trunk from projects containing modules, records about the integration of these modules also fell on the trunk. And all the following projects branched off from the trunk have already refused to accept the code of the modules, considering that they have already received these changes earlier.
And we realized that SVN has one important limitation in our case, the meaning of which can be described as follows: it is impossible for closed paths to form in the paths of transfer of changes .
We tried to optimize these paths, inventing different rules, we divided the changes into classes and set separate rules for each of them, but finally realized that all this was too complicated and inconvenient, and we abandoned the idea of modularity that we liked at the source level, replacing its usual run-time modularity.
Recently, I have increasingly heard enthusiastic reviews from my acquaintances about distributed version control systems, in particular Mercurial and Git. And I had a question, is it possible to organize such a complex scheme for transferring changes on these systems?
I ask the people using the mentioned or other systems to tell whether it is possible to transfer changes along closed contours to them without the occurrence of the described problem? For example, in the following diagram, is it possible to make a merge-edit 8? And will the system block the attempt to re-transfer 9?
SVN, for example, will block both.
UP: tzlom says that Git will make both edits, and, naturally, in the 9th it will create a collision. In general, in SVN, you can also ignore blocking, and then the effect will be the same.
UP: PQR prompted Mercurial to edit the changes atomically using the Transplant extension and to Git using the cherry-pick command, but apparently both edits will be allowed in both cases (8 and 9).
Source: https://habr.com/ru/post/105870/
All Articles