Getting the main content of web pages programmatically
The task of clearing web pages of information noise is one of the urgent tasks of information retrieval. Its essence is to clear the information noise and get only the main content.
Consider an example:
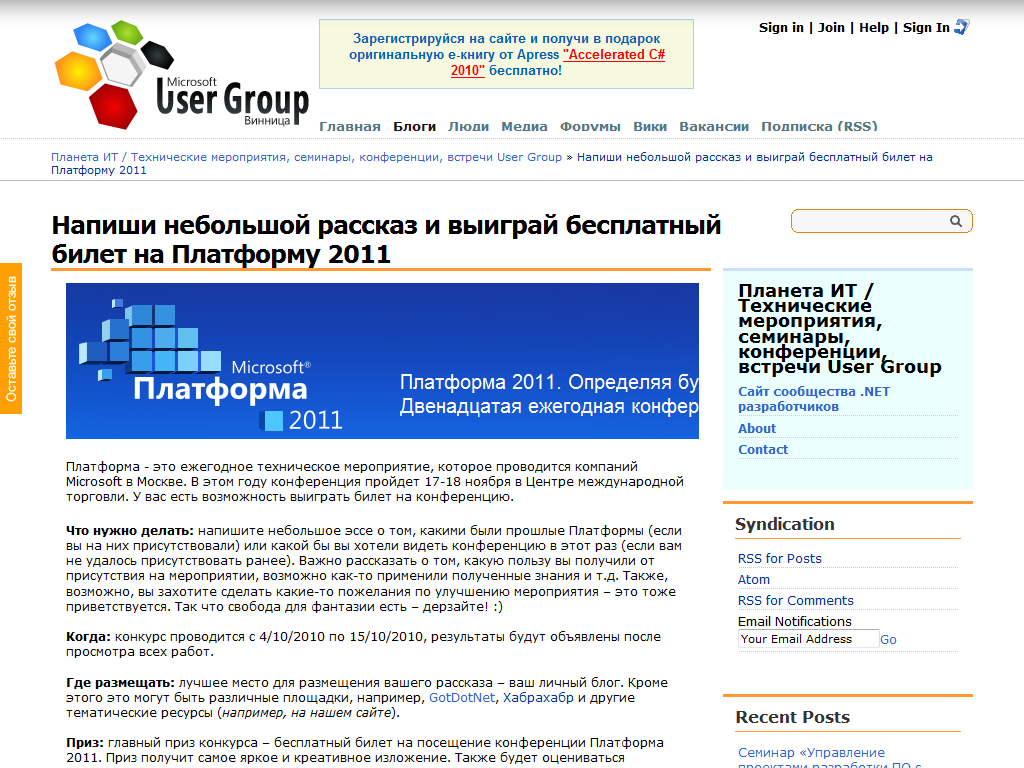
The main content can be considered this part of the page:
')

Where it can be applied:
Before proceeding to the description of the solution, I will briefly discuss the existing solutions. With the advent of HTML5, the problem of finding the main content should disappear, since the specification implies new semantic elements. Consider them in more detail.
Currently, the following semantic elements are assumed:

The use of this method currently faces the following problems:
Website: http://lab.arc90.com/experiments/readability/
Readability is an Arc90 Lab development that allows you to install a small bookmark that will help bring web pages into a readable form. Readability uses its metrics to analyze the DOM model and identify “useful” content.
Readability example:

At the moment there are plug-ins for various browsers, and in Safari this feature is known as Safari Reader. For those who work on the Internet, this should be enough, but what about those who want to use this tool to write their own scripts? Actually, about it further.
A number of my previous articles were devoted to the study of this problem, in particular, I propose to get acquainted with such publications:
The new version of SmartBrowser will be available soon on the site. The percentage of correctly recognized web pages has increased, while models and algorithms have become simpler as a result of experiments and research.
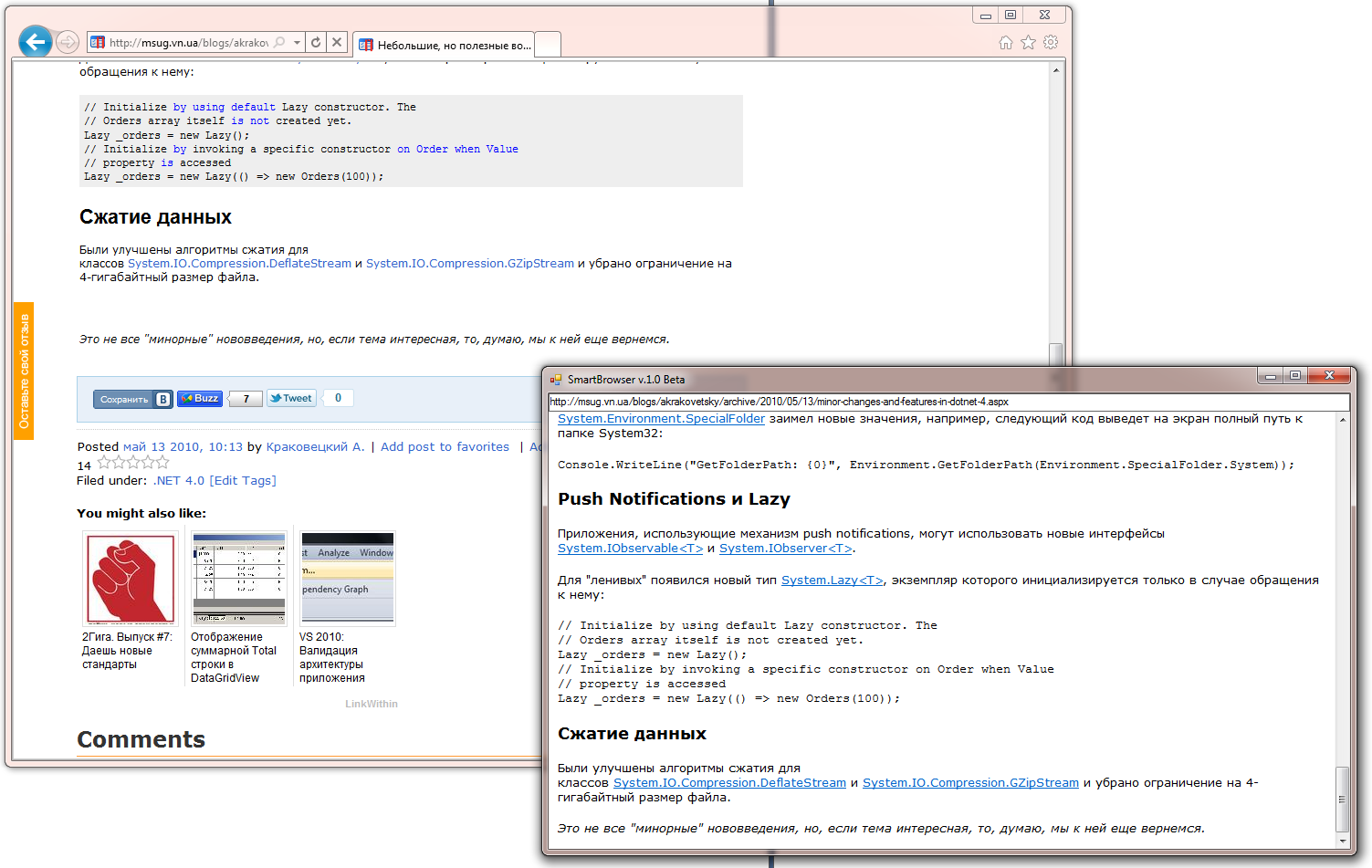
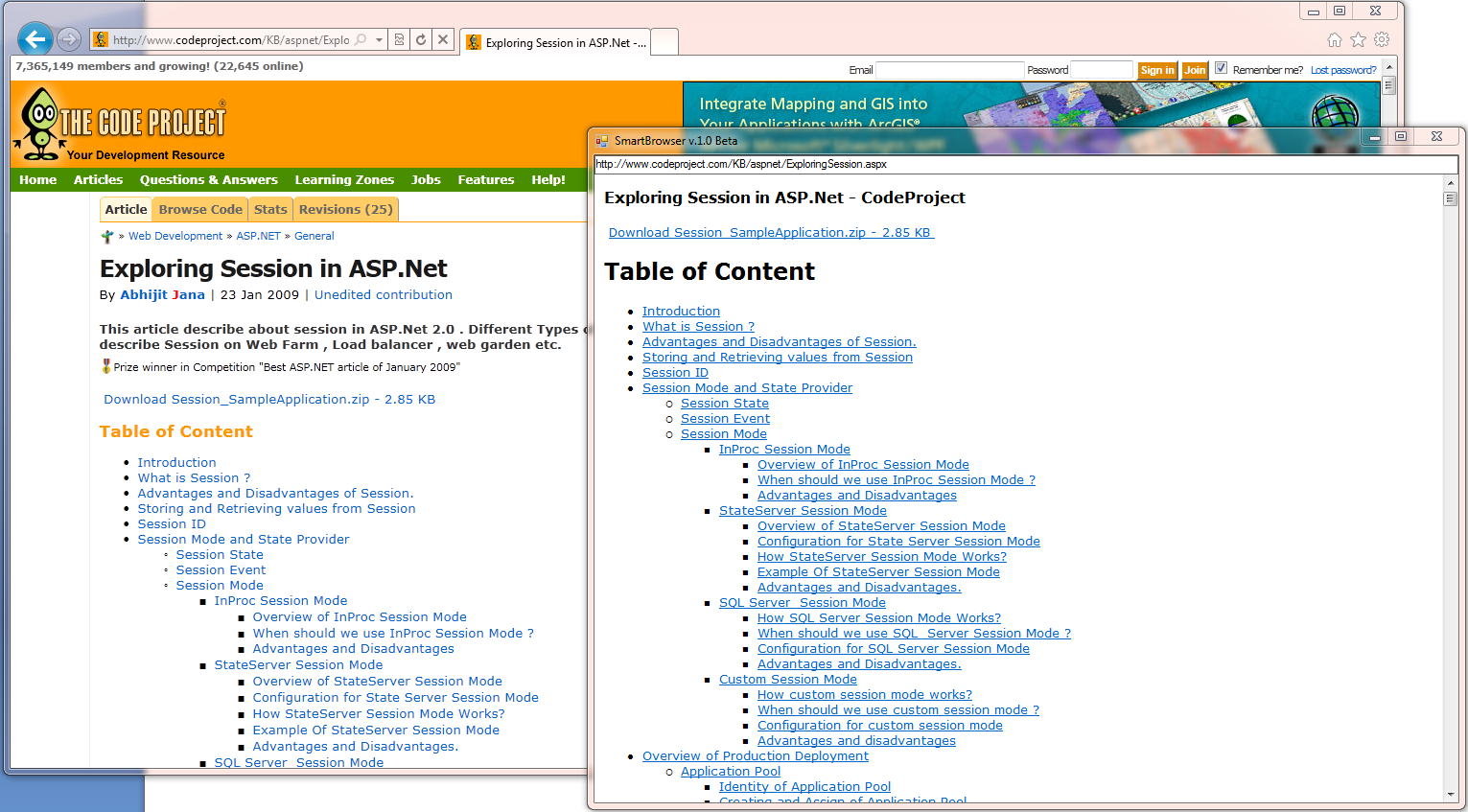
Currently, SmartBrowser looks like this:
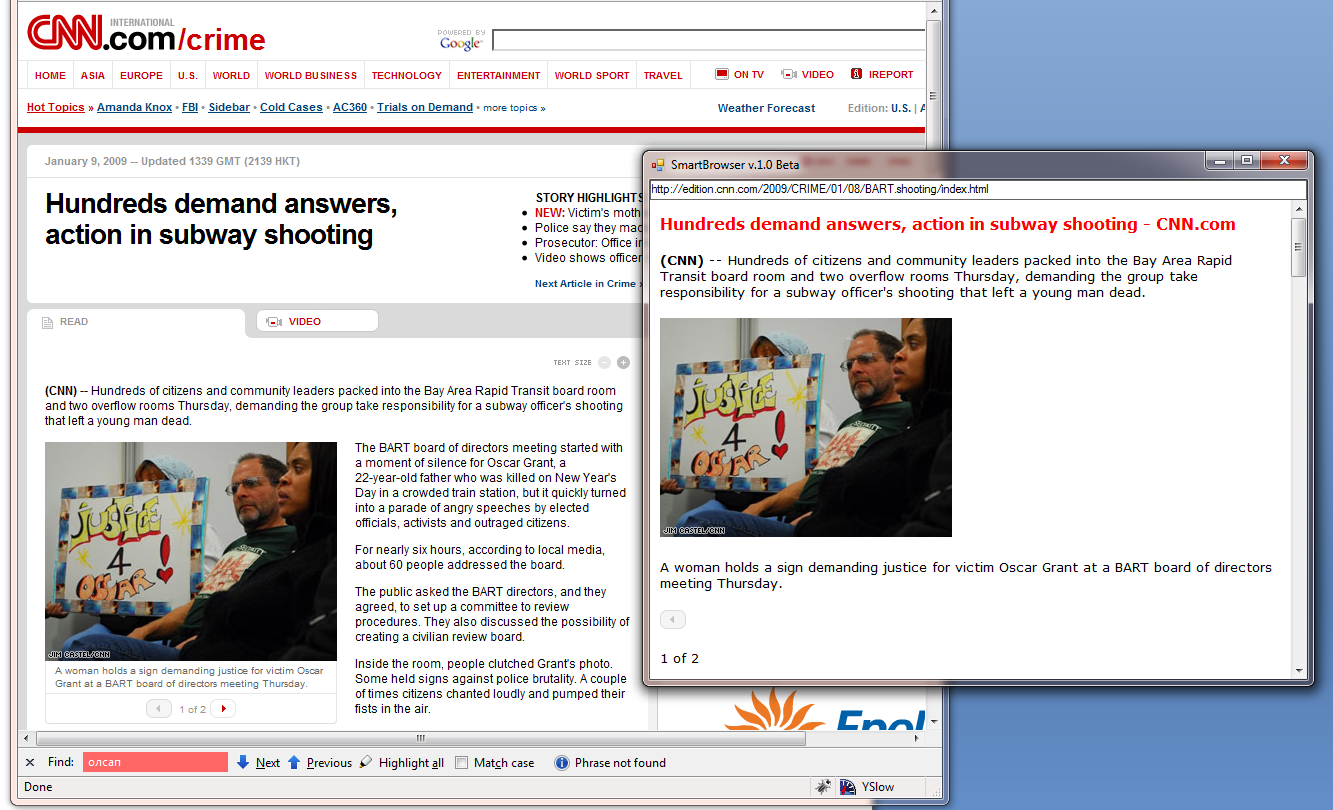
Consider the work of SmartBrowser in action. Processing a web page looks like this:
All the logic is encapsulated in the MainContentExtractor class from the developed Data Extracting SDK library (at the moment this functionality is not on the site yet), which I have already written about several times.
As a result, I obtained the following results for a number of well-known sites:
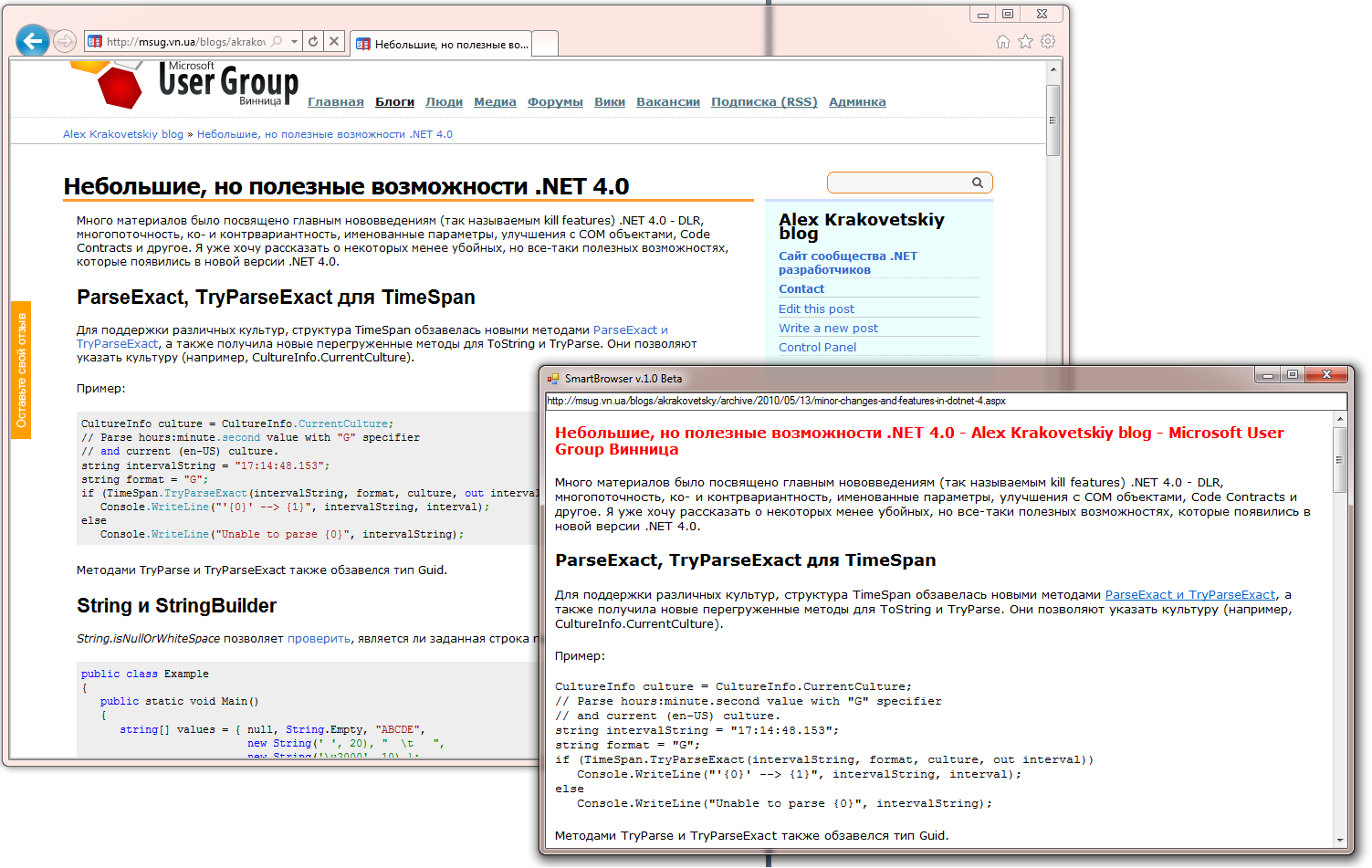


At the moment there are problems with some sites, for example, with Habr. Therefore, at the moment, research and development continues, but I hope that in the near future we will be able to talk about some kind of stable build.
Thanks for attention.
Consider an example:
The main content can be considered this part of the page:
')
Where it can be applied:
- content delivery services, when other methods for some reason are not suitable (for example, the RSS feed is missing or gives only an introduction);
- systems for collecting some information from various sources
- in mobile applications where it is important to minimize traffic
- data mining systems, BI
Before proceeding to the description of the solution, I will briefly discuss the existing solutions. With the advent of HTML5, the problem of finding the main content should disappear, since the specification implies new semantic elements. Consider them in more detail.
HTML5 semantic elements
Currently, the following semantic elements are assumed:
- section - the element groups thematic blocks. Section elements can be nested
- header - contains the header of any section, table, etc.
- footer - the footer of a web page, usually in this block place information about the site, contacts, copyrights
- nav - navigation block, list of links related topics
- article - the main content
- aside - not the main block, usually located on the sides of the page
The use of this method currently faces the following problems:
- HTML5 specification is in draft status
- IE does not currently support these tags.
- it is necessary that all developers adhere to uniform rules for marking web pages
- nobody canceled dishonest SEO optimizers
Readability
Website: http://lab.arc90.com/experiments/readability/
Readability is an Arc90 Lab development that allows you to install a small bookmark that will help bring web pages into a readable form. Readability uses its metrics to analyze the DOM model and identify “useful” content.
Readability example:
At the moment there are plug-ins for various browsers, and in Safari this feature is known as Safari Reader. For those who work on the Internet, this should be enough, but what about those who want to use this tool to write their own scripts? Actually, about it further.
Studies on the importance of information blocks
A number of my previous articles were devoted to the study of this problem, in particular, I propose to get acquainted with such publications:
- Clearing web pages of information noise
- Web pages content analysis with SmartBrowser
- SeoRank criterion for determining the main content of web pages
- About information search, finding the best ways to view search results and much more
The new version of SmartBrowser will be available soon on the site. The percentage of correctly recognized web pages has increased, while models and algorithms have become simpler as a result of experiments and research.
Currently, SmartBrowser looks like this:
Consider the work of SmartBrowser in action. Processing a web page looks like this:
MainContentExtractor r = new MainContentExtractor(new Uri(tbUrl.Text.Trim()));
var html = r.GetContent();
webBrowser1.DocumentText = r.getTitle().InnerText + html;
All the logic is encapsulated in the MainContentExtractor class from the developed Data Extracting SDK library (at the moment this functionality is not on the site yet), which I have already written about several times.
As a result, I obtained the following results for a number of well-known sites:
At the moment there are problems with some sites, for example, with Habr. Therefore, at the moment, research and development continues, but I hope that in the near future we will be able to talk about some kind of stable build.
Thanks for attention.
Source: https://habr.com/ru/post/105582/
All Articles