Building a plug-in modular system
About three years ago I had ideas about how to create such a system core that would allow us to quickly and effectively expand its functionality with the help of plug-ins, extensions. At the same time, it was necessary to minimize the problems that arise with plug-in writers during product development, compatibility problems of many plug-ins.
On the one hand, the task is not a problem, it is enough to give developers a rich API for working with the system. But on the other hand, if the study of the system will require too much effort, it will never gain popularity. Careful documentation in fast-developing projects often does not work, it means that you need to use the simplest mechanisms that will allow you to understand as soon as possible to a novice plug-in how everything works.
This article is designed for novice programmers who are looking for ideas of a similar architecture for the implementation of their projects.
')
The core of a system that has a modular structure usually looks like this
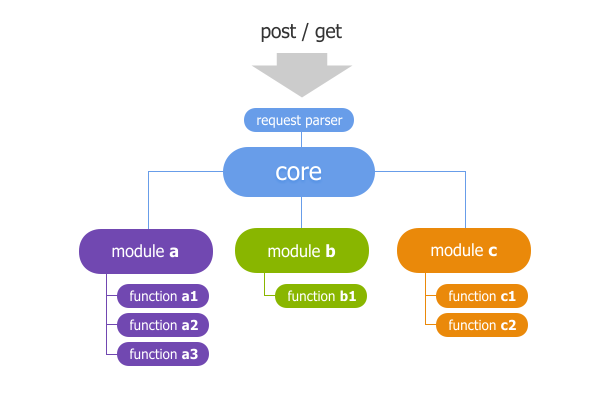
The core is a set of basic functions that help implement information flows within the system. The kernel coordinates the entire system as a whole.
The system receives a request that is processed by a special method or kernel object (request manager), whose task is to determine what the system needs to do at the request of the user.
Modules are connected to the kernel. A module is a set of functions / methods, some of which are public, i.e. available to the user for execution. Not to be confused with public methods of objects. Module functions may be public methods, but this is not a prerequisite for the functioning of the system. For example, a news module can have several functions: show a list of news, show a specific news, create a news, edit a news, delete a news, publish a news, etc.
Modules must interact with each other only through the core, otherwise building a multimodular system will be not so difficult, but practically impossible.
If we design the system only on the basis of the first scheme, we cannot achieve the desired effect. The implementation of the new module will require design and implementation from scratch. And if we want to refine the existing one, then we have to go along the path of the patches of existing modules, or along the path of a complete copy of the module and subsequent modifications. But the system does not stand still, and with the development of the module compatibility will seriously suffer. Patches can simply stop working. You will have to constantly monitor updates or, on the contrary, freeze the update process, which is not very good, because in new versions of the product they can fix serious vulnerabilities or critical bugs.
Here handlers will come to the rescue. A handler is a certain function to which control can be transferred during code execution.
And now let's typify our every public function to the next look.
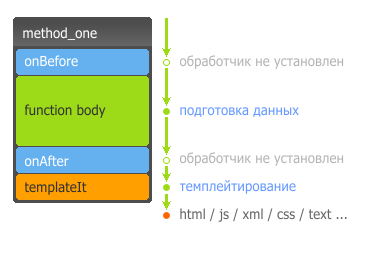
This is an abstract scheme, not the code of the function itself.
Consider a typical execution process when handlers are not installed. Let our abstract function have an onBefore handler that is called before the process of executing the working body of the function. The onAfter handler will be executed after the body of our function performs some useful work.
Here I added a special block called templateIt . This is a call to the data templating process, as a result of which we will get html-code, or any other text document. This is not a mandatory unit, it may not be.
For example, we call the function of displaying a specific news. The function body will select the required data and send it to the template system.
In reality, it will be a little more difficult.
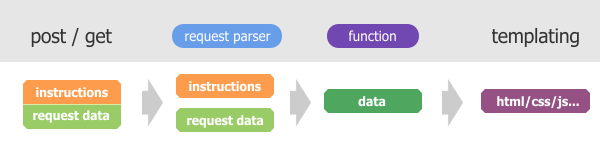
The system receives a get or post request, which is a set of instructions and data. Instructions will be the instruction to execute the news module, and the data will be the news identifier. The request manager has to separate the data and instructions, and then the kernel will request the necessary function of the module and transfer the initial data to it. The function will process the request and send the working data to the template system, which will make for us a beautiful html-code.
I will give a simple example. The system can display a list of users. You have created a module that has a different list of users who are VIP visitors to your system. You wanted not only to display a list of users, but also to show which of them is also a VIP-visitor.
So you have to add an onAfter- handler to the function that forms the list of users. Your function will receive a dataset as a list of users. It will only be necessary to arrange a VIP sign for persons from this list. The template will have to copy from the original function with a list of users, and make the necessary changes there.
Now, when calling the list of users, your new template will flaunt.
On paper it looks beautiful, but not always beautifully realizable. With dynamic code execution, your new module must be launched before the kernel transfers control to the module that generates the list of users. And who knows what to do? Initialize all modules at once? Not a very effective solution.
And let's change the procedure a bit.
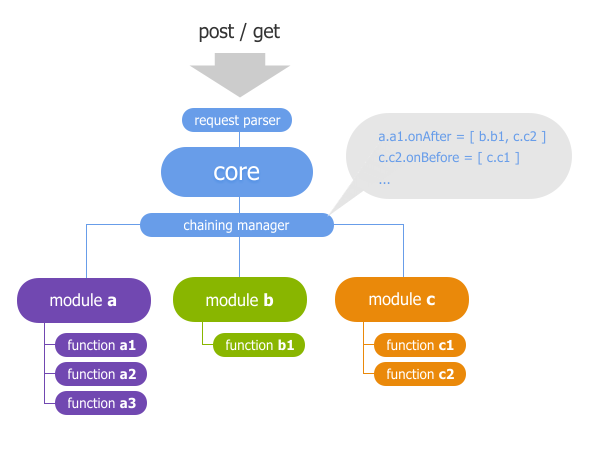
In the entire execution procedure, we add a certain chaining manager (relations manager :)), the main task of which is as follows. If the module's function is going to act as a processor, it is initially declared in the link manager. For the execution of public function handlers and data transfer to the template system, the relationship manager becomes responsible. The public function degenerates simply into the function body, i.e. there is no other code inside it except for working with data.
But we lack something. It is necessary to standardize all data transmission in the system so that the modules can speak the same language among themselves.
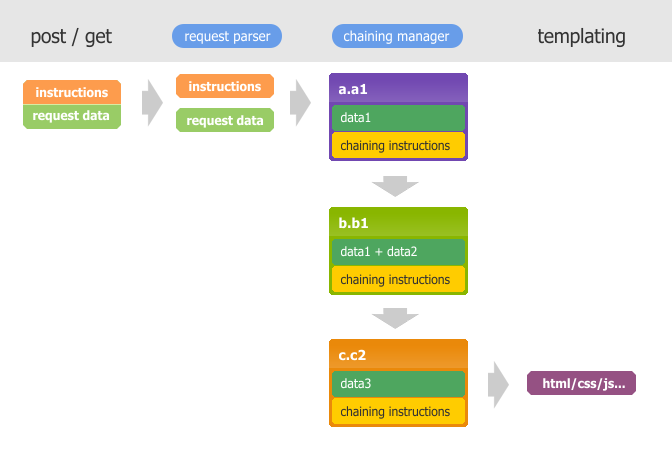
If we concatenate several functions, then we need to know what to do next. For example, after executing a.a1 , we will have a data set of data1 and a set of instructions chaining instructions , which will indicate that this function is ready to turn the data into a template. But, this function has an onAfter handler, which means that b.b1 needs to be executed , which will add data2 to data1 , but this function may not change the template.
In turn, this function may also have its own onAfter processor, which will create its data based on the data of the previous functions, and say that it is necessary to carry out the procedure for warming data. And so on, ad infinitum.
This is much better and more flexible. I hope my thoughts will help someone in the implementation of their brilliant ideas.
Have a nice programming!
UPD. Work on the bugs.
On the one hand, the task is not a problem, it is enough to give developers a rich API for working with the system. But on the other hand, if the study of the system will require too much effort, it will never gain popularity. Careful documentation in fast-developing projects often does not work, it means that you need to use the simplest mechanisms that will allow you to understand as soon as possible to a novice plug-in how everything works.
This article is designed for novice programmers who are looking for ideas of a similar architecture for the implementation of their projects.
')
Core system
The core of a system that has a modular structure usually looks like this
The core is a set of basic functions that help implement information flows within the system. The kernel coordinates the entire system as a whole.
The system receives a request that is processed by a special method or kernel object (request manager), whose task is to determine what the system needs to do at the request of the user.
Modules are connected to the kernel. A module is a set of functions / methods, some of which are public, i.e. available to the user for execution. Not to be confused with public methods of objects. Module functions may be public methods, but this is not a prerequisite for the functioning of the system. For example, a news module can have several functions: show a list of news, show a specific news, create a news, edit a news, delete a news, publish a news, etc.
Modules must interact with each other only through the core, otherwise building a multimodular system will be not so difficult, but practically impossible.
Handlers
If we design the system only on the basis of the first scheme, we cannot achieve the desired effect. The implementation of the new module will require design and implementation from scratch. And if we want to refine the existing one, then we have to go along the path of the patches of existing modules, or along the path of a complete copy of the module and subsequent modifications. But the system does not stand still, and with the development of the module compatibility will seriously suffer. Patches can simply stop working. You will have to constantly monitor updates or, on the contrary, freeze the update process, which is not very good, because in new versions of the product they can fix serious vulnerabilities or critical bugs.
Here handlers will come to the rescue. A handler is a certain function to which control can be transferred during code execution.
And now let's typify our every public function to the next look.
This is an abstract scheme, not the code of the function itself.
Consider a typical execution process when handlers are not installed. Let our abstract function have an onBefore handler that is called before the process of executing the working body of the function. The onAfter handler will be executed after the body of our function performs some useful work.
Here I added a special block called templateIt . This is a call to the data templating process, as a result of which we will get html-code, or any other text document. This is not a mandatory unit, it may not be.
For example, we call the function of displaying a specific news. The function body will select the required data and send it to the template system.
In reality, it will be a little more difficult.
The system receives a get or post request, which is a set of instructions and data. Instructions will be the instruction to execute the news module, and the data will be the news identifier. The request manager has to separate the data and instructions, and then the kernel will request the necessary function of the module and transfer the initial data to it. The function will process the request and send the working data to the template system, which will make for us a beautiful html-code.
What do handlers give us?
I will give a simple example. The system can display a list of users. You have created a module that has a different list of users who are VIP visitors to your system. You wanted not only to display a list of users, but also to show which of them is also a VIP-visitor.
So you have to add an onAfter- handler to the function that forms the list of users. Your function will receive a dataset as a list of users. It will only be necessary to arrange a VIP sign for persons from this list. The template will have to copy from the original function with a list of users, and make the necessary changes there.
Now, when calling the list of users, your new template will flaunt.
On paper it looks beautiful, but not always beautifully realizable. With dynamic code execution, your new module must be launched before the kernel transfers control to the module that generates the list of users. And who knows what to do? Initialize all modules at once? Not a very effective solution.
And let's change the procedure a bit.
In the entire execution procedure, we add a certain chaining manager (relations manager :)), the main task of which is as follows. If the module's function is going to act as a processor, it is initially declared in the link manager. For the execution of public function handlers and data transfer to the template system, the relationship manager becomes responsible. The public function degenerates simply into the function body, i.e. there is no other code inside it except for working with data.
But we lack something. It is necessary to standardize all data transmission in the system so that the modules can speak the same language among themselves.
If we concatenate several functions, then we need to know what to do next. For example, after executing a.a1 , we will have a data set of data1 and a set of instructions chaining instructions , which will indicate that this function is ready to turn the data into a template. But, this function has an onAfter handler, which means that b.b1 needs to be executed , which will add data2 to data1 , but this function may not change the template.
In turn, this function may also have its own onAfter processor, which will create its data based on the data of the previous functions, and say that it is necessary to carry out the procedure for warming data. And so on, ad infinitum.
This is much better and more flexible. I hope my thoughts will help someone in the implementation of their brilliant ideas.
Have a nice programming!
UPD. Work on the bugs.
Source: https://habr.com/ru/post/105545/
All Articles