Parsing the source code of programming languages and markup languages
..it is true that you need to write an operating system ..
The latest versions of the Nemerle language include a library for parsing languages whose grammar belongs to the PEG class.
What is PEG?
Unlike other tools for creating parsers, PEG does not describe the grammar, but a strategy for parsing it, but in fact the description of the strategy of ruin is a description of the grammar. For the parser described using PEG, there is an algorithm ( packrat ) that parses any text that satisfies the grammar from this class, for a linear time from the length of the text.
The class of languages that can be parsed using parsers described in a similar way is wide enough to cover popular programming languages (for example, C #) and markup languages. Obviously, it covers all the functionality of regular expressions.
')
Why do you need something when there RegExp?
Regular expression libraries are included in the set of standard libraries of almost any programming language. Because of this walking distance, they are used where it is appropriate (parsing regular grammars), and where there is none (parsing html and other recursive structures).
Quote from stackoverflow :
..it is true that you need to write an operating system ..
At the other extreme are parser generators, for example, yacc and antlr. They cope with the task of generating parsers according to the provided grammar, but in practice it happens that it is “easier” for the programmer to write the parser itself than to use them. The reason for this is most likely the complexity of working with these tools, as well as the fact that, unlike regular expressions that are eDSL, working with them requires code generation, and code generation is inconvenient.
A macro is responsible for generating the parser by the PEG grammar in Nemerle. Thus, code generation disappears and work with irregular grammars turns into work with eDSL: the accessibility of regular expressions is added to the power of parser generation. Consider the example of working with PEG in Nemerle
Analysis of the mathematical markup of the language TeX
Consider the PEG grammar using the example of the TeX mathematical markup grammar. We will analyze the source of this picture
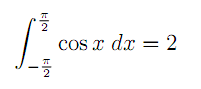
Here he is
\int_{-\frac{\pi}{2}}^{\frac{\pi}{2}} \cos x \; dx = 2 It can be seen that it consists of the commands (\ int, \ pi, \ cos), the escape sequence (\;), the nested bracket structure ({.. {..} ..}) and everything else.
First of all, we define the structure in which this text will be dealt with:
public variant WordTexAst { | Command { name : string } // | Escape { symbol : string } // escape | Group { data : WordTexAst.Sequence } // | Data { data : string } // | Sequence { words : list[WordTexAst]} } I used variations, in other programming languages, they are also known as algebraic data types or labeled joins.
In order to create a language parser, you need to declare a class, describe the strategy for parsing the language in the attribute of this class, and associate each function with a function that builds a tree from the parsed information. Let's start with the attribute
[PegGrammar(ast, grammar { commandName = ['a'..'z','A'..'Z']+; escapeLetter = ';' / ','; letter = ['a'..'z','A'..'Z','0'..'9'] / '^' / '_' / '=' / ' ' / '-' / '+' / '/' / '(' / ')' / '[' / ']'; command : WordTexAst = '\\' commandName; escape : WordTexAst = '\\' escapeLetter; group : WordTexAst = '{' ast '}'; data : WordTexAst = letter+; word : WordTexAst = command / escape / group / data; ast : WordTexAst.Sequence = word+; })] The first parameter of the macro is the rule with which to start parsing. Then - a description of the grammar (strategy), which is very similar to the Backus-Naur form. In the left column is the rule to be defined, followed by the type of structure that is parsed by this rule. In the first three cases, it is omitted, since these rules serve as constants for the remaining rules. After the equal sign, the structure of the parsed text is described; it can be specified using constants and other rules, separated by a space. To describe the structure, you can use special characters, for example, '+' - apply the rule one or more times, 'a / b' means apply the parsing rule 'a', if it doesn’t fit, then the parsing rule 'b'. It is important that this operator is not commutative, if the first parsing rule is applied successfully, then the alternative is not considered.
In addition to the attribute, you need to add several methods to the parser class - one for each parsing rule. The number of arguments and their type must comply with the rules that are used by this rule on the right side (after the equal sign).
Full parser code example:
[PegGrammar(ast, grammar { commandName = ['a'..'z','A'..'Z']+; escapeLetter = ';' / ','; letter = ['a'..'z','A'..'Z','0'..'9'] / '^' / '_' / '=' / ' ' / '-' / '+' / '/' / '(' / ')' / '[' / ']'; command : WordTexAst = '\\' commandName; escape : WordTexAst = '\\' escapeLetter; group : WordTexAst = '{' ast '}'; data : WordTexAst = letter+; word : WordTexAst = command / escape / group / data; ast : WordTexAst.Sequence = word+; })] public class TexParser { private escape(_ : NToken, symbol : NToken) : WordTexAst { WordTexAst.Escape(GetText(symbol)) } private command(_ : NToken, commandName : NToken) : WordTexAst { WordTexAst.Command(GetText(commandName)) } private group(_ : NToken, ast : WordTexAst.Sequence, _ : NToken) : WordTexAst { WordTexAst.Group(ast) } private data(arg : NToken) : WordTexAst { WordTexAst.Data(GetText(arg)) } private word(arg : WordTexAst) : WordTexAst { arg } private ast(data : List[WordTexAst]) : WordTexAst.Sequence { WordTexAst.Sequence(data.ToList()) } } The type NToken has not been described yet. This is the class that matches the substring in the parsed text that satisfies the “constant” rule. You can translate an object of this class into a string using the GetText method.
It remains to demonstrate the use of the parser:
def parser = TexParser(); def text = @"\int_{-\frac{\pi}{2}}^{\frac{\pi}{2}} \cos x \; dx = 2"; def (pos,ast) = parser.TryParse(text); when (pos == text.Length) Console.WriteLine("success"); The TryParse method parses the text, pos contains the number of characters parsed, if the string is fully parsed, then pos is equal to the length of the string, if only the prefix is parsed, then pos contains the prefix length.
Conclusion
The article describes eDSL for building PEG grammars. In addition to building recursive language parsers, it can be used to parse regular grammars, in the case when a regular expression is too complicated to work with.
This eDSL is implemented as a macro, which at the compilation stage is disclosed in an efficient parsing algorithm. The resulting dll can be used in any .net language. Thus, the use of this library is not limited to one language.
Links
Current version of Nemerle
Forum on rsdn.ru (Russian)
Google group (English)
Source: https://habr.com/ru/post/104968/
All Articles