The system of disjoint sets and its application
Good afternoon, Habrahabr. This is another post within my program to enrich the database of the largest IT resource with information on algorithms and data structures. As practice shows, many people lack this information, and the need is found in the most diverse spheres of programmer life.
I continue to mainly choose those algorithms / structures that are easily understood and which do not require a lot of code - but it is difficult to underestimate the practical significance. Last time it was a Cartesian tree . This time - a system of disjoint sets . It is also known as disjoint set union (DSU) or Union-Find .
We set ourselves the following task. Let us operate with elements of N types (for simplicity, hereinafter - numbers from 0 to N-1). Some groups of numbers are combined into sets. We can also add a new element to the structure; it thus forms a set of size 1 from itself. Finally, from time to time we will need to merge some two sets into one.
We formalize the task: create a fast structure that supports the following operations:
')
MakeSet (X) - add a new element X to the structure, create for it a set of size 1 from itself.
Find (X) - return the identifier of the set to which the element X belongs. As the identifier we will choose one element from this set - the representative of the set. It is guaranteed that for the same set the representative will be returned the same, otherwise it will be impossible to work with the structure: even checking the belonging of two elements to one set
Unite (X, Y) - combine two sets in which the elements X and Y lie in one new.
In the figure I will demonstrate the work of such a hypothetical structure.
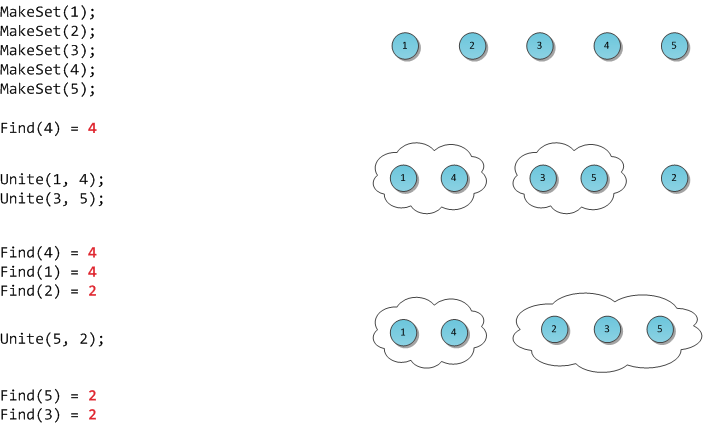
The classic DSU implementation was proposed by Bernard Galler and Michael Fischer in 1964, but was investigated (including a temporary assessment of complexity) by Robert Tarjan already in 1975. Taryan also owns some results, improvements and applications, which we will talk about later today.
We will store the data structure in the form of a forest, that is, turn the DSU into a system of non-intersecting trees. All elements of one set lie in one corresponding tree, the representative of a tree is its root, the merging of sets is simply the union of two trees into one. As we will see, such an idea, along with two small heuristics, leads to a surprisingly high speed of the resulting structure.
To begin with, we need an array p that stores for each vertex of the tree its immediate ancestor (and for the root of the tree X, it itself). Using this array alone, you can effectively implement the first two DSU operations:
To create a new tree from the X element, it is enough to indicate that it is the root of its own tree, and does not have an ancestor.
Representative of the tree will be its root. Then, to find this representative, it is enough to go up the parental links until we stumble upon the root.
But that's not all: such a naive implementation in the case of a degenerate (stretched in line) tree can work for O (N), which is unacceptable. One could try to speed up the search. For example, to store not only the immediate ancestor, but large log-lifting tables, but it requires a lot of memory. Or, instead of storing the reference to the ancestor, store the reference to the root itself — however, when merging trees (Unite), these references will have to be changed to all elements of one of the trees, and this, again, is an O (N) cost.
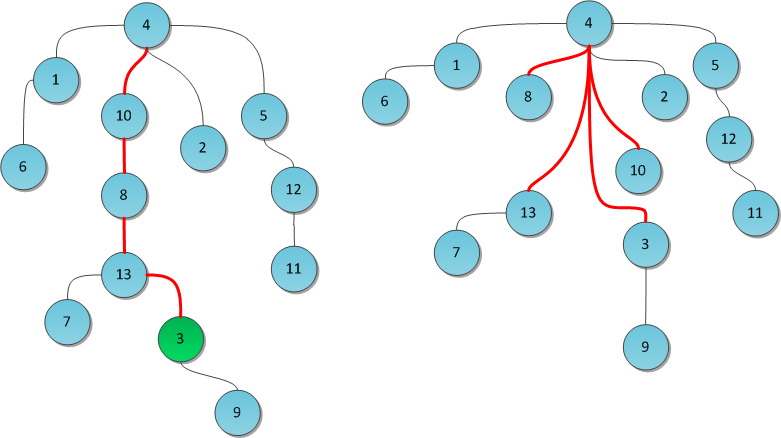
We will go the other way: instead of speeding up the implementation, we will simply try not to allow excessively long branches in the tree. This is the first DSU heuristic; it is called path compression. The essence of heuristics: after a representative is found, we will change the ancestor to this representative for each vertex on the way from X to the root. That is, in fact, we will re-hang all these vertices instead of a long branch directly to the root. Thus, the implementation of the Find operation becomes two-pass.
The figure shows the tree before and after the Find (3) operation. Red ribs - those that we walked along the path to the root. Now they are redirected. Notice how after this the height of the tree has drastically decreased.
The source code in a recursive form is quite simple to write:
With the merger of two trees will have to tinker a bit. Find the roots of both merging trees to begin with using the already-written Find function. Now, remembering that our implementation stores only references to immediate parents, to merge trees it would be enough just to suspend one of the roots (and with it the whole tree) by the son to another. Thus, all the elements of this tree will automatically belong to another - and the procedure for finding a representative will return the root of the new tree.
The question is: which tree to which to hang? To always choose one, say, tree X, is no good: it is easy to pick an example on which, after N associations, we get a degenerate tree — one branch of N elements. And here comes the second DSU heuristics, aimed at reducing the height of the trees.
In addition to the ancestors, we will store another Rank array. In it for each tree will be stored the upper limit of its height - that is, the longest branch in it. Notice, not the height itself - in the process of Finding, the longest branch can self-destruct, but it is too expensive to spend another iteration on finding the new longest branch. Therefore, for each root, a number will be written in the Rank array, guaranteed to be greater than or equal to the height of its tree.
Now it is easy to make a decision to merge: in order to prevent too long branches in the DSU, we will hang the lower tree to a higher one. If their heights are equal, it does not matter who is hung up to whom. But in the latter case, the newly-made root must not forget to increase its Rank.
This is how a typical Unite is produced (for example, with parameters 8 and 19):

However, in practice it turns out that it is possible and not to spend additional O (N) memory on frauds with ranks. It is enough to choose a root for overweighing at random - surprisingly, but such a solution gives in practice a speed quite comparable with the original rank realization. The author of this article all his life uses a randomized DSU, and there has not yet been a case when he would let him down.
C # implementation:
Due to the use of two heuristics, the speed of each operation depends strongly on the tree structure, and the tree structure depends on the list of operations performed before. The only exception is MakeSet - its running time is obviously O (1) :-) For the other two, the speed is very subtle.
Robert Taryan proved a remarkable fact in 1975: the operating time for both Find and Unite in a forest of size N is O (α (N)).
Under α (N) in mathematics, we denote the inverse Akkerman function, that is, the inverse function forf (N) = A (N, N) . Ackermann's A (N, M) function is known for having a tremendous growth rate. For example, A (4, 4) = 2 2 2 65536 -3 , this number is truly huge. In general, for all conceivable practical values of N, the inverse Ackermann function will not exceed 5. Therefore, it can be taken as a constant and taken as O (α (N)) ≅ O (1) .
So, we have:
MakeSet (X) - O (1).
Find (X) - O (1) is depreciated.
Unite (X, Y) - O (1) depreciated.
Memory consumption - O (N).
Not bad at all :-)
There are a large number of different uses for DSUs. Most of them are connected with solving some problem in offline mode - that is, when the list of requests regarding the structure that is received by the program is known in advance. I will give here several such problems along with brief ideas for solutions.
An undirected connected graph with weighted edges is given. Throw out some ribs from it so that in the end you get a tree, and the total weight of the edges of this tree should be the smallest.
One of the well-known places where this problem arises (although it is solved differently) is blocking redundant links in the Ethernet network to avoid possible packet cycles. The protocols created for this purpose are widely known, with half of the major modifications made by Cisco. See the Spanning Tree Protocol for more details.
The figure shows a weighted graph with a selected minimum skeleton.

Kraskal's algorithm for solving this problem: we will sort all the edges by increasing weight and will maintain the current forest of minimum weight using DSU. Initially, a DSU consists of N trees, one vertex each. We go along the edges in order of increasing; if the current edge combines different components, we merge them into one and remember the edge as an element of the core. As soon as the number of components reaches one, we built the desired tree.
Given a tree and a set of queries of the form: for given vertices u and v, return their least common ancestor (LCA) to their nearest common ancestor. The entire set of requests is known in advance, i.e. The task is formulated offline.
Let's start to start the search in depth on the tree. Consider some query <u, v>. Let depth search come to such a state that one of the vertices of the query (say, u) has already been visited by the search earlier, and now the current top of the search is v, the entire subtree v has just been examined. Obviously, the answer to the query will be either the vertex v itself, or one of its ancestors. Moreover, each of the ancestors of v, on the way to the root, generates some class of vertices u for which it is the answer: this class is exactly equal to the already viewed branch of the tree “to the left” of such ancestor.
In the picture you can see a tree with a partition of the vertices into classes, while the white vertices are still unvisited.
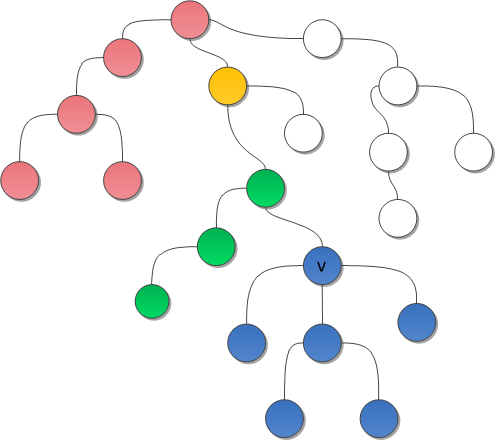
Classes of such vertices do not intersect with each other, which means that they can be supported in DSU. As soon as the depth-first search returns from the subtree, merge the class of this subtree with the class of the current vertex. And to search for an answer, support the Ancestor array — for each vertex, the ancestor itself, which gave rise to the class of this vertex. The value of the cell of this array for the representative must not forget to rewrite when merging the trees. But now in the depth search process for each fully processed vertex v, we can find all <u, v> in the request list, where u is already processed, and output the answer:
A multigraph (a graph in which a pair of vertices can be connected by more than one immediate edge) is given, to which queries of the form “delete some edge” and “how many are now in the graph of connectivity components come in?”
The decision is trite. First, we will execute all removal requests, calculate the number of components in the final graph, and remember it. We turn out the resulting graph in DSU. Now we’ll go through the deletion requests in the reverse order: each edge removal from the old graph means a possible merging of two components in our “flashback graph” stored in the DSU; In this case, the current number of connected components is reduced by one.
Consider some image - a rectangular array of pixels. It can be represented as a grid graph: each vertex-pixel is directly connected by edges with its four nearest neighbors. The task is to select the same semantic zones in the image, for example, of a similar color, and to be able to quickly determine for two pixels whether they are in the same zone. So, for example, old black-and-white films are painted: for a start, you need to select areas with approximately the same shades of gray.
There are two approaches to solving this problem, both end up using a DSU. In the first version, we draw an edge not between each pair of neighboring pixels, but only between those that are quite close in color. After that, the usual rectangular traversal of the graph will fill in the DSU, and we will get a set of connected components - they are also monochromatic areas of the image.
The second option is more flexible. We will not completely remove the edges, but assign each of them a weight calculated on the basis of the difference in colors and some additional factors - our own for each specific segmentation task. In the resulting graph, it suffices to find some forest of minimum weight, for example, using the same Krasalkal algorithm. In practice, not every current connecting edge is recorded in the DSU, but only those for which at the moment the two components do not differ much by the measures of the other special weight function.
Task: generate a maze with one entrance and one exit.
Algorithm of the decision:
Let's start with the state when all the walls are installed, except for the entrance and exit.
At each step of the algorithm, choose a random wall. If the cells between which it stands are still not connected at all (they lie in different components of the DSU), then we destroy it (we merge the components).
We continue the process to a state of convergence: for example, when the input and output are connected; or when there is only one component left.
There are implementation options for Find (X), which require one pass to the root, not two, but retain the same or almost the same degree of speed. They implement other strategies for reducing the height of the tree, unlike path compression.
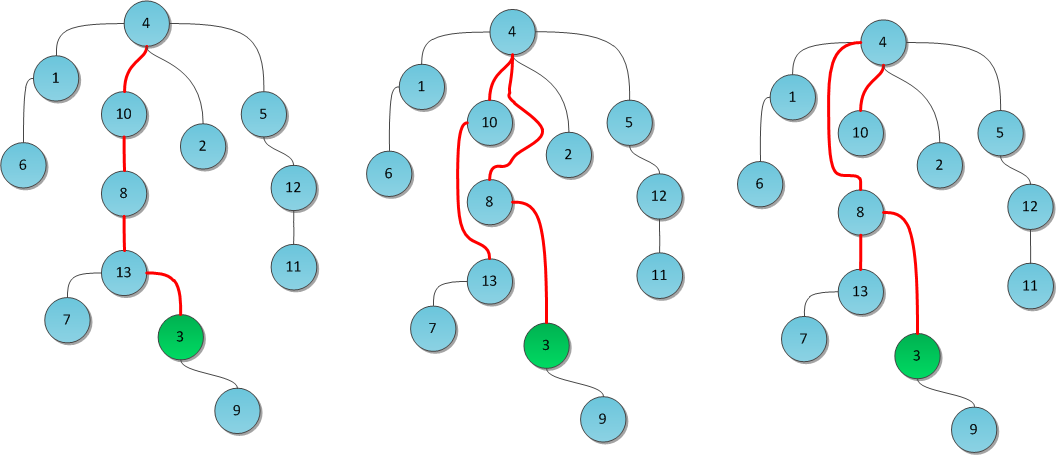
Option number 1: path splitting . On the way from the top X to the root, redirect the parent connection of each peak from its ancestor to the ancestor of the ancestor (grandfather).
Option number 2: path halving . Take the idea of path splitting, but redirect the links of not all the vertices along the way, but only those on which we redirect - that is, "grandfathers".
In the figure, the same tree is taken, the Find (3) query is executed in it. The center shows the result with the use of path splitting, on the right - path halving.
The system of disjoint sets has one major drawback: it does not support the operation of Undo in any form, because it is implemented through the imperative style. It would be much more convenient to implement a DSU in a functional style, when each operation does not change the structure in place, but returns a slightly modified new structure in which the required changes are made (most of the memory of the old and new structures is common). Such data structures in English terminology are called persistent , they are widely used in pure functional programming, where the idea of data immutability dominates.
By virtue of the purely imperative idea of DSU algorithms, its functional implementation while maintaining performance for a long time seemed unthinkable. However, in 2007, Sylvain Conchon and Jean-Christophe Filliâtre presented in their work the desired functional version in which the Unite operation returns a modified structure. To be honest, it is not quite functional, it uses imperative assignments, but they are safely hidden inside the implementation, and the persistent DSU interface is purely functional.
The main idea of the implementation is the use of data structures that implement “persistent arrays”: they support the same operations as arrays, but they still do not modify the memory, but return a modified structure. Such an array can be easily implemented with the help of some tree, however, in this case, operations with it will take O (log 2 N) time, and for DSU such an estimate is already excessively large.
For further technical details refer readers to the original article .
Systems of non-intersecting sets in the scope of this article are discussed in the famous book - Kormen, Leyzerson, Rivest, Stein “Algorithms: construction and analysis”. There you can find evidence that the execution of operations takes about α (N) time.
On Maxim Ivanov's site you can find the full DSU implementation in C ++.
The Wait-free Parallel Algorithms for the Union-Find Problem article discusses the parallel version of the DSU implementation. It does not block threads.
Thank you all for your attention :-)
I continue to mainly choose those algorithms / structures that are easily understood and which do not require a lot of code - but it is difficult to underestimate the practical significance. Last time it was a Cartesian tree . This time - a system of disjoint sets . It is also known as disjoint set union (DSU) or Union-Find .
Condition
We set ourselves the following task. Let us operate with elements of N types (for simplicity, hereinafter - numbers from 0 to N-1). Some groups of numbers are combined into sets. We can also add a new element to the structure; it thus forms a set of size 1 from itself. Finally, from time to time we will need to merge some two sets into one.
We formalize the task: create a fast structure that supports the following operations:
')
MakeSet (X) - add a new element X to the structure, create for it a set of size 1 from itself.
Find (X) - return the identifier of the set to which the element X belongs. As the identifier we will choose one element from this set - the representative of the set. It is guaranteed that for the same set the representative will be returned the same, otherwise it will be impossible to work with the structure: even checking the belonging of two elements to one set
if (Find(X) == Find(Y)) will not be correct.Unite (X, Y) - combine two sets in which the elements X and Y lie in one new.
In the figure I will demonstrate the work of such a hypothetical structure.
Implementation
The classic DSU implementation was proposed by Bernard Galler and Michael Fischer in 1964, but was investigated (including a temporary assessment of complexity) by Robert Tarjan already in 1975. Taryan also owns some results, improvements and applications, which we will talk about later today.
We will store the data structure in the form of a forest, that is, turn the DSU into a system of non-intersecting trees. All elements of one set lie in one corresponding tree, the representative of a tree is its root, the merging of sets is simply the union of two trees into one. As we will see, such an idea, along with two small heuristics, leads to a surprisingly high speed of the resulting structure.
To begin with, we need an array p that stores for each vertex of the tree its immediate ancestor (and for the root of the tree X, it itself). Using this array alone, you can effectively implement the first two DSU operations:
MakeSet (X)
To create a new tree from the X element, it is enough to indicate that it is the root of its own tree, and does not have an ancestor.
public void MakeSet(int x) { p[x] = x; } Find (X)
Representative of the tree will be its root. Then, to find this representative, it is enough to go up the parental links until we stumble upon the root.
But that's not all: such a naive implementation in the case of a degenerate (stretched in line) tree can work for O (N), which is unacceptable. One could try to speed up the search. For example, to store not only the immediate ancestor, but large log-lifting tables, but it requires a lot of memory. Or, instead of storing the reference to the ancestor, store the reference to the root itself — however, when merging trees (Unite), these references will have to be changed to all elements of one of the trees, and this, again, is an O (N) cost.
We will go the other way: instead of speeding up the implementation, we will simply try not to allow excessively long branches in the tree. This is the first DSU heuristic; it is called path compression. The essence of heuristics: after a representative is found, we will change the ancestor to this representative for each vertex on the way from X to the root. That is, in fact, we will re-hang all these vertices instead of a long branch directly to the root. Thus, the implementation of the Find operation becomes two-pass.
The figure shows the tree before and after the Find (3) operation. Red ribs - those that we walked along the path to the root. Now they are redirected. Notice how after this the height of the tree has drastically decreased.
The source code in a recursive form is quite simple to write:
public int Find(int x) { if (p[x] == x) return x; return p[x] = Find(p[x]); } Unite (X, Y)
With the merger of two trees will have to tinker a bit. Find the roots of both merging trees to begin with using the already-written Find function. Now, remembering that our implementation stores only references to immediate parents, to merge trees it would be enough just to suspend one of the roots (and with it the whole tree) by the son to another. Thus, all the elements of this tree will automatically belong to another - and the procedure for finding a representative will return the root of the new tree.
The question is: which tree to which to hang? To always choose one, say, tree X, is no good: it is easy to pick an example on which, after N associations, we get a degenerate tree — one branch of N elements. And here comes the second DSU heuristics, aimed at reducing the height of the trees.
In addition to the ancestors, we will store another Rank array. In it for each tree will be stored the upper limit of its height - that is, the longest branch in it. Notice, not the height itself - in the process of Finding, the longest branch can self-destruct, but it is too expensive to spend another iteration on finding the new longest branch. Therefore, for each root, a number will be written in the Rank array, guaranteed to be greater than or equal to the height of its tree.
Now it is easy to make a decision to merge: in order to prevent too long branches in the DSU, we will hang the lower tree to a higher one. If their heights are equal, it does not matter who is hung up to whom. But in the latter case, the newly-made root must not forget to increase its Rank.
This is how a typical Unite is produced (for example, with parameters 8 and 19):
public void Unite(int x, int y) { x = Find(x); y = Find(y); if (rank[x] < rank[y]) p[x] = y; else { p[y] = x; if (rank[x] == rank[y]) ++rank[x]; } } However, in practice it turns out that it is possible and not to spend additional O (N) memory on frauds with ranks. It is enough to choose a root for overweighing at random - surprisingly, but such a solution gives in practice a speed quite comparable with the original rank realization. The author of this article all his life uses a randomized DSU, and there has not yet been a case when he would let him down.
C # implementation:
public void Unite(int x, int y) { x = Find(x); y = Find(y); if (rand.Next() % 2 == 0) Swap(ref x, ref y); p[x] = y; } Speed performance
Due to the use of two heuristics, the speed of each operation depends strongly on the tree structure, and the tree structure depends on the list of operations performed before. The only exception is MakeSet - its running time is obviously O (1) :-) For the other two, the speed is very subtle.
Robert Taryan proved a remarkable fact in 1975: the operating time for both Find and Unite in a forest of size N is O (α (N)).
Under α (N) in mathematics, we denote the inverse Akkerman function, that is, the inverse function for
So, we have:
MakeSet (X) - O (1).
Find (X) - O (1) is depreciated.
Unite (X, Y) - O (1) depreciated.
Memory consumption - O (N).
Not bad at all :-)
Practical applications
There are a large number of different uses for DSUs. Most of them are connected with solving some problem in offline mode - that is, when the list of requests regarding the structure that is received by the program is known in advance. I will give here several such problems along with brief ideas for solutions.
Skeleton minimum weight
An undirected connected graph with weighted edges is given. Throw out some ribs from it so that in the end you get a tree, and the total weight of the edges of this tree should be the smallest.
One of the well-known places where this problem arises (although it is solved differently) is blocking redundant links in the Ethernet network to avoid possible packet cycles. The protocols created for this purpose are widely known, with half of the major modifications made by Cisco. See the Spanning Tree Protocol for more details.
The figure shows a weighted graph with a selected minimum skeleton.
Kraskal's algorithm for solving this problem: we will sort all the edges by increasing weight and will maintain the current forest of minimum weight using DSU. Initially, a DSU consists of N trees, one vertex each. We go along the edges in order of increasing; if the current edge combines different components, we merge them into one and remember the edge as an element of the core. As soon as the number of components reaches one, we built the desired tree.
Tarjan's algorithm for searching LCA offline
Given a tree and a set of queries of the form: for given vertices u and v, return their least common ancestor (LCA) to their nearest common ancestor. The entire set of requests is known in advance, i.e. The task is formulated offline.
Let's start to start the search in depth on the tree. Consider some query <u, v>. Let depth search come to such a state that one of the vertices of the query (say, u) has already been visited by the search earlier, and now the current top of the search is v, the entire subtree v has just been examined. Obviously, the answer to the query will be either the vertex v itself, or one of its ancestors. Moreover, each of the ancestors of v, on the way to the root, generates some class of vertices u for which it is the answer: this class is exactly equal to the already viewed branch of the tree “to the left” of such ancestor.
In the picture you can see a tree with a partition of the vertices into classes, while the white vertices are still unvisited.
Classes of such vertices do not intersect with each other, which means that they can be supported in DSU. As soon as the depth-first search returns from the subtree, merge the class of this subtree with the class of the current vertex. And to search for an answer, support the Ancestor array — for each vertex, the ancestor itself, which gave rise to the class of this vertex. The value of the cell of this array for the representative must not forget to rewrite when merging the trees. But now in the depth search process for each fully processed vertex v, we can find all <u, v> in the request list, where u is already processed, and output the answer:
Ancestor[Find(u)] .Multigraph connectivity components
A multigraph (a graph in which a pair of vertices can be connected by more than one immediate edge) is given, to which queries of the form “delete some edge” and “how many are now in the graph of connectivity components come in?”
The decision is trite. First, we will execute all removal requests, calculate the number of components in the final graph, and remember it. We turn out the resulting graph in DSU. Now we’ll go through the deletion requests in the reverse order: each edge removal from the old graph means a possible merging of two components in our “flashback graph” stored in the DSU; In this case, the current number of connected components is reduced by one.
Image segmentation
Consider some image - a rectangular array of pixels. It can be represented as a grid graph: each vertex-pixel is directly connected by edges with its four nearest neighbors. The task is to select the same semantic zones in the image, for example, of a similar color, and to be able to quickly determine for two pixels whether they are in the same zone. So, for example, old black-and-white films are painted: for a start, you need to select areas with approximately the same shades of gray.
There are two approaches to solving this problem, both end up using a DSU. In the first version, we draw an edge not between each pair of neighboring pixels, but only between those that are quite close in color. After that, the usual rectangular traversal of the graph will fill in the DSU, and we will get a set of connected components - they are also monochromatic areas of the image.
The second option is more flexible. We will not completely remove the edges, but assign each of them a weight calculated on the basis of the difference in colors and some additional factors - our own for each specific segmentation task. In the resulting graph, it suffices to find some forest of minimum weight, for example, using the same Krasalkal algorithm. In practice, not every current connecting edge is recorded in the DSU, but only those for which at the moment the two components do not differ much by the measures of the other special weight function.
Maze Generation
Task: generate a maze with one entrance and one exit.
Algorithm of the decision:
Let's start with the state when all the walls are installed, except for the entrance and exit.
At each step of the algorithm, choose a random wall. If the cells between which it stands are still not connected at all (they lie in different components of the DSU), then we destroy it (we merge the components).
We continue the process to a state of convergence: for example, when the input and output are connected; or when there is only one component left.
Single Pass Algorithms
There are implementation options for Find (X), which require one pass to the root, not two, but retain the same or almost the same degree of speed. They implement other strategies for reducing the height of the tree, unlike path compression.
Option number 1: path splitting . On the way from the top X to the root, redirect the parent connection of each peak from its ancestor to the ancestor of the ancestor (grandfather).
Option number 2: path halving . Take the idea of path splitting, but redirect the links of not all the vertices along the way, but only those on which we redirect - that is, "grandfathers".
In the figure, the same tree is taken, the Find (3) query is executed in it. The center shows the result with the use of path splitting, on the right - path halving.
Functional implementation
The system of disjoint sets has one major drawback: it does not support the operation of Undo in any form, because it is implemented through the imperative style. It would be much more convenient to implement a DSU in a functional style, when each operation does not change the structure in place, but returns a slightly modified new structure in which the required changes are made (most of the memory of the old and new structures is common). Such data structures in English terminology are called persistent , they are widely used in pure functional programming, where the idea of data immutability dominates.
By virtue of the purely imperative idea of DSU algorithms, its functional implementation while maintaining performance for a long time seemed unthinkable. However, in 2007, Sylvain Conchon and Jean-Christophe Filliâtre presented in their work the desired functional version in which the Unite operation returns a modified structure. To be honest, it is not quite functional, it uses imperative assignments, but they are safely hidden inside the implementation, and the persistent DSU interface is purely functional.
The main idea of the implementation is the use of data structures that implement “persistent arrays”: they support the same operations as arrays, but they still do not modify the memory, but return a modified structure. Such an array can be easily implemented with the help of some tree, however, in this case, operations with it will take O (log 2 N) time, and for DSU such an estimate is already excessively large.
For further technical details refer readers to the original article .
Literature
Systems of non-intersecting sets in the scope of this article are discussed in the famous book - Kormen, Leyzerson, Rivest, Stein “Algorithms: construction and analysis”. There you can find evidence that the execution of operations takes about α (N) time.
On Maxim Ivanov's site you can find the full DSU implementation in C ++.
The Wait-free Parallel Algorithms for the Union-Find Problem article discusses the parallel version of the DSU implementation. It does not block threads.
Thank you all for your attention :-)
Source: https://habr.com/ru/post/104772/
All Articles