Overclocked engine - ABBYY FineReader Engine 10 for Windows runs much faster
Last week we released the next version of the OCR SDK - a product for embedding text recognition technologies in various applications. For many years, we have been supplementing the release of custom boxed FineReader with the circulation of mugs and T-shirts with the release of appropriate technologies in the form of SDK - FineReader Engine (for short, we call it FRE).
Under the cut, I will talk about the improvements of the new FRE compared to previous versions.
When developing a new version, we set ourselves almost Olympic goals - more precisely, faster, more functional. Over the accuracy and functionality, we actively worked in the ninth version of the FineReader Engine and in this regard have achieved significant improvements.
')
In the tenth version, speed came to the fore. By release, we were able to accelerate the Fast Mode (special speed recognition mode) 1.5–2 times for most European languages. At the same time, the increase in speed was not at the expense of quality, the recognition accuracy in Fast Mode remained on average at the same level. For the Russian language, the speed increased by an average of 44%. These figures are obtained as a result of internal testing on packages containing the main types of office documents.
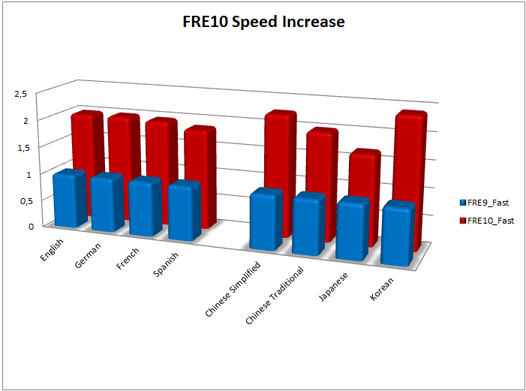
The relative increase in speed for each language compared with the results of FRE 9.0 (release October 21, 2008)
For the main Asian languages - Chinese, Japanese and Korean - the main goal was still accuracy. The number of errors in the recognition of documents in these languages has decreased by an average of 30-40%. In addition, the graph shows a significant increase in speed.
Many less obvious improvements have been made.
New binarization - the conversion of color and halftone images into black and white. This is a necessary stage of preparation of documents for recognition, it depends on it whether it will be possible to recognize a faint text on the scan of a crumpled sheet with fingerprints. Binarization has become much better; this is one of the reasons why the quality did not suffer as the speed increased.
Camera OCR TM - a set of special transformations to improve the quality of text recognition on photographed documents. Among them:
- correction of trapezoidal distortion that appear when shooting at an angle,
- elimination of blurring in photos - a characteristic defect when shooting without a tripod,
- smoothing ISO-noise - a variety of multi-colored dots in the photo, appearing at high sensitivity of the camera in low light conditions.
There are new ADRT TM features - document structure (document map) and table of contents (table of contents - TOC) restoration by titles, automatic creation of styles, recognition of image captions, setting a special style for captions and combining images and captions into a single object.
A very important improvement is improving the clarity, accessibility of the product and facilitating work with it. OCR SDK is a multifunctional tool with a huge API that allows you to configure a large number of parameters.
Users solve a variety of tasks. Someone develops systems for scanning books from the library into PDF with the ability to contextual search, someone implements automatic registration of documents in the EDS based on barcode recognition, and someone develops its own technology to extract data using the function of recognition and text verification.
Obviously, for different tasks there are different requirements for the functionality of the SDK and the quality of technology. In one case, the first place is the quality and size of the received PDF files, in the other, the accuracy of recognition of text orbar codes . Consequently, different settings are required for different tasks.
To simplify product customization, we have created a series of profiles containing optimal parameter values for solving specific problems. This idea is reflected in the main “visual” of the product:

Simply select the appropriate profile - and you can work.
In addition, the product certificate was significantly improved, it became more structured and complete.
We hope that all this will help to integrate the FineReader Engine into applications faster and easier, and to get even better recognition results.
We are planning to release the FRE10 version for Linux in about a year.
Semyon Sergunin
Department of Technology Products
Under the cut, I will talk about the improvements of the new FRE compared to previous versions.
When developing a new version, we set ourselves almost Olympic goals - more precisely, faster, more functional. Over the accuracy and functionality, we actively worked in the ninth version of the FineReader Engine and in this regard have achieved significant improvements.
')
In the tenth version, speed came to the fore. By release, we were able to accelerate the Fast Mode (special speed recognition mode) 1.5–2 times for most European languages. At the same time, the increase in speed was not at the expense of quality, the recognition accuracy in Fast Mode remained on average at the same level. For the Russian language, the speed increased by an average of 44%. These figures are obtained as a result of internal testing on packages containing the main types of office documents.
The relative increase in speed for each language compared with the results of FRE 9.0 (release October 21, 2008)
For the main Asian languages - Chinese, Japanese and Korean - the main goal was still accuracy. The number of errors in the recognition of documents in these languages has decreased by an average of 30-40%. In addition, the graph shows a significant increase in speed.
Many less obvious improvements have been made.
New binarization - the conversion of color and halftone images into black and white. This is a necessary stage of preparation of documents for recognition, it depends on it whether it will be possible to recognize a faint text on the scan of a crumpled sheet with fingerprints. Binarization has become much better; this is one of the reasons why the quality did not suffer as the speed increased.
Camera OCR TM - a set of special transformations to improve the quality of text recognition on photographed documents. Among them:
- correction of trapezoidal distortion that appear when shooting at an angle,
- elimination of blurring in photos - a characteristic defect when shooting without a tripod,
- smoothing ISO-noise - a variety of multi-colored dots in the photo, appearing at high sensitivity of the camera in low light conditions.
There are new ADRT TM features - document structure (document map) and table of contents (table of contents - TOC) restoration by titles, automatic creation of styles, recognition of image captions, setting a special style for captions and combining images and captions into a single object.
A very important improvement is improving the clarity, accessibility of the product and facilitating work with it. OCR SDK is a multifunctional tool with a huge API that allows you to configure a large number of parameters.
Users solve a variety of tasks. Someone develops systems for scanning books from the library into PDF with the ability to contextual search, someone implements automatic registration of documents in the EDS based on barcode recognition, and someone develops its own technology to extract data using the function of recognition and text verification.
Obviously, for different tasks there are different requirements for the functionality of the SDK and the quality of technology. In one case, the first place is the quality and size of the received PDF files, in the other, the accuracy of recognition of text or
To simplify product customization, we have created a series of profiles containing optimal parameter values for solving specific problems. This idea is reflected in the main “visual” of the product:
Simply select the appropriate profile - and you can work.
In addition, the product certificate was significantly improved, it became more structured and complete.
We hope that all this will help to integrate the FineReader Engine into applications faster and easier, and to get even better recognition results.
We are planning to release the FRE10 version for Linux in about a year.
Semyon Sergunin
Department of Technology Products
Source: https://habr.com/ru/post/104378/
All Articles