Guessing on the noise of information
There is a fairly well-founded opinion that in the future, humanity runs the risk of sinking into an avalanche of information, which itself produces at an accelerated pace. And that for our further development, the ability to control this avalanche will play an increasingly important role. And here we are talking not only about dividing the flow of information into the necessary and unnecessary, but also about ways to make even the “white noise” bring benefits.
Scientists from the HP Social Computing Laboratory in Palo Alto, California are also taking steps in this direction. For example, the other day its employees Sitaram Azur (Sitaram Asur) and Bernardo Huberman (Bernardo A. Huberman) published an interesting work . Within its framework, they undertook to use the well-known Twitter for ... predicting the future. True, not far away.
And if you still abandon the hazy catchy phrases in the style of the yellow press, then the work refers to the prediction of box office films before their release. The accuracy of the forecast, based on the analysis of the discussion of the film on Twitter, is higher than that of the Hollywood Stock Exchange rating adopted as the “gold standard” in the film industry. Which, in turn, is a by-product of an online game, where participants can buy and sell virtual “shares” of actors, directors, films, etc. for play money. At the time, this rating also became a real breakthrough.
Sitaram and Bernardo used the Twitter Search API to collect all tweets for 3 months, mentioning 24 new films they chose. As a result, they became the owners of a database of 2.89 million records, each of which contained the exact time of publication, the name of the author and the full text of the tweet. Scanning was performed 1 time per hour. As a search query, all the words contained in the title of the film were used, and only pictures that were released in wide release on Fridays (a traditional day for premieres in the USA) were taken into account. But, for obvious reasons, the scientists did not consider, for example, the film “2012”.
')
The primary analysis showed that the most references to each film are found in the first weekend after its premiere. Within two weeks after this main peak, splashes of attention are no longer tied to a specific day of the week.
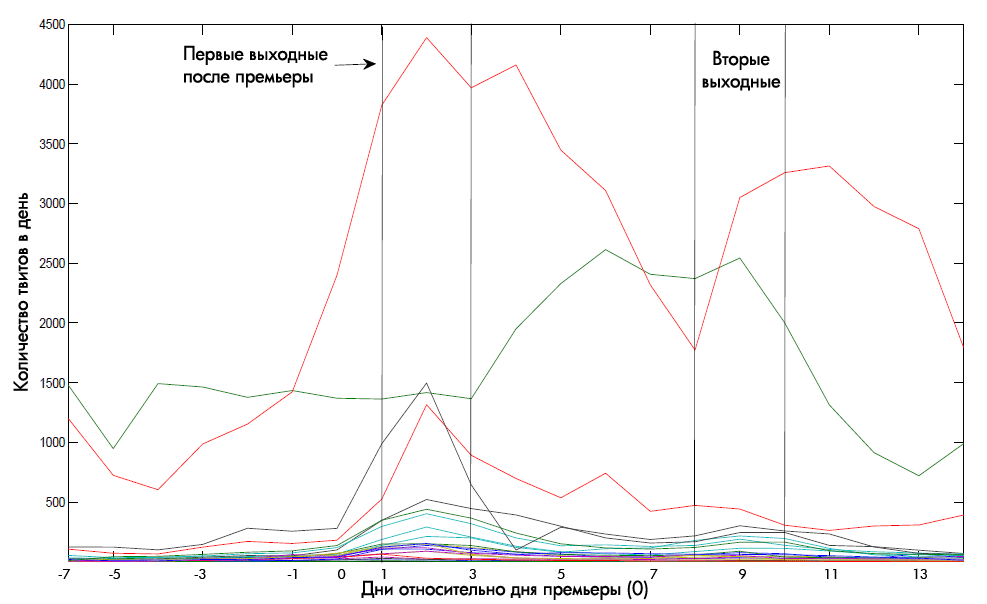
Fig. 1. The dependence of the number of tweets about the film from time to time. Premiere Day is accepted as zero
Another expected conclusion shows that during the week prior to the start of the film, when the advertising machine is gaining momentum, an average of 40% of all movie tweets contain links to external sources: posters, trailers, promotional sites, etc. It is interesting, however, that a comparison of the number of tweets with links with the real success of films at the box office showed that such “frontal” advertising campaigns had little effect on the final box office (with a coefficient of determination of 0.39). From this we can conclude that there is no point in using Twitter only to bluntly redirect users to other resources.
As a measured value of twitter activity around the film, scientists introduced a tweet coefficient expressing the number of tweets about a movie per hour:
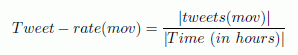
The average correlation coefficient between the tweet coefficient and the sum of box office was 0.90, which shows a strong linear relationship between these values. Building on this, Sitaram and Bernardo conducted a regression analysis of dependency, taking as variables 7 average tweet coefficients for each of the days of the week preceding the premiere of the film.
Already such a model allowed to achieve in the prediction coefficient of determination 0.93, which means a very high predictability of the dependent value. And the introduction as an additional variable number of cinemas, in which the film is planned to be shown, raised the coefficient to 0.973.
At this stage, scientists have found that they have exceeded the accuracy of the forecasts of the Hollywood Stock Exchange (HSX). The diagram below shows the forecast for the tweet coefficient (Tweet-rate) and the HSX forecast in comparison with the absolutely accurate forecast (red line).
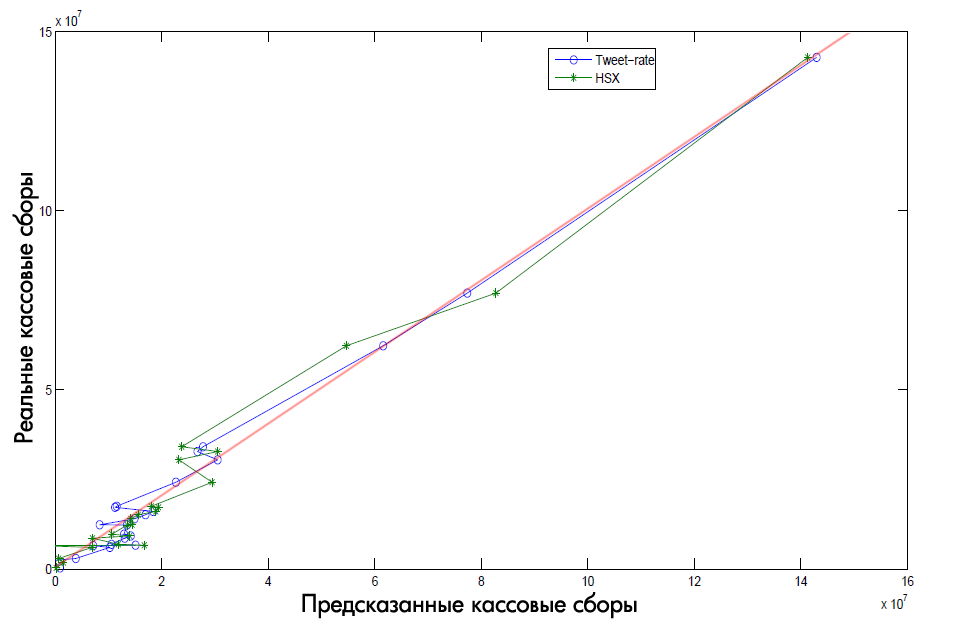
Fig. 2. Comparison of the quality of forecasts
You can see that the less box-office film we take for research, the lower the accuracy of the forecasts.
From the big picture, according to which the proceeds from the film gradually fall over time, there are exceptions. For example, the film “The Unseen Side ” did not start very well ($ 34 million at the box office), but fired the second weekend ($ 40 million). On the other hand, part of the “Twilight” trilogy “ New Moon ”, thanks to advertising, scored $ 142 million on the first weekend, already in the second significantly lost interest of the audience - only $ 42 million on tickets.
The reason - reviews watched the movie audience. If they are positive, it will attract new people to the halls. If negative - scare away those who waited for the movie before the premiere.
To predict such turns, our researchers have taken as a basis the tools of linguistic text analysis available to all: the LingPipe software package and the Amazon Mechanical Turk service , which provides live volunteers for various jobs.
Having taught the package to automatically recognize the mood of each movie tweet (positive, neutral, negative) with an accuracy of 98%, Sitaram and Bernardo introduced the ratio of positive tweets to negative ones as another numerical measure of the potential success of the movie. The higher it is, the more likely it is that people will go to the film.
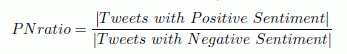
For the “Invisible Side,” as it turned out, this attitude after the premiere almost doubled (from 5.02 to 9.65). For New Moon, it fell from 6.29 to 5. Using this data in addition to the tweet coefficients already received after the premiere, it is possible to predict charges with high accuracy for a very long time after the “day zero”.
Of course, the joy of scientists would be incomplete (and their work would be incomplete) if, apart from this particular example, they did not try to consider a general model of predictions.
As a result, they derived a formula for predicting the commercial success of any openly advertised product:
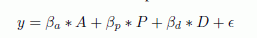 ,
,
where y denotes the income received from the product; And - the amount of attention among the audience (similar to the tweet coefficient, measured in various ways, depending on the case); P - mood reviews; D - the parameter of the availability of the product on the market (analogous to the number of cinemas in which the film goes in the considered case). The values of β reflect the regression coefficients , and ε - an error.
Expanding the applicability of this model to other areas of life is the work of the next work. A good goal, for example, will be the prediction of election results. Unless, of course, y is known here in advance.
Scientists from the HP Social Computing Laboratory in Palo Alto, California are also taking steps in this direction. For example, the other day its employees Sitaram Azur (Sitaram Asur) and Bernardo Huberman (Bernardo A. Huberman) published an interesting work . Within its framework, they undertook to use the well-known Twitter for ... predicting the future. True, not far away.
And if you still abandon the hazy catchy phrases in the style of the yellow press, then the work refers to the prediction of box office films before their release. The accuracy of the forecast, based on the analysis of the discussion of the film on Twitter, is higher than that of the Hollywood Stock Exchange rating adopted as the “gold standard” in the film industry. Which, in turn, is a by-product of an online game, where participants can buy and sell virtual “shares” of actors, directors, films, etc. for play money. At the time, this rating also became a real breakthrough.
Sitaram and Bernardo used the Twitter Search API to collect all tweets for 3 months, mentioning 24 new films they chose. As a result, they became the owners of a database of 2.89 million records, each of which contained the exact time of publication, the name of the author and the full text of the tweet. Scanning was performed 1 time per hour. As a search query, all the words contained in the title of the film were used, and only pictures that were released in wide release on Fridays (a traditional day for premieres in the USA) were taken into account. But, for obvious reasons, the scientists did not consider, for example, the film “2012”.
')
Advertised, advertised ...
The primary analysis showed that the most references to each film are found in the first weekend after its premiere. Within two weeks after this main peak, splashes of attention are no longer tied to a specific day of the week.
Fig. 1. The dependence of the number of tweets about the film from time to time. Premiere Day is accepted as zero
Another expected conclusion shows that during the week prior to the start of the film, when the advertising machine is gaining momentum, an average of 40% of all movie tweets contain links to external sources: posters, trailers, promotional sites, etc. It is interesting, however, that a comparison of the number of tweets with links with the real success of films at the box office showed that such “frontal” advertising campaigns had little effect on the final box office (with a coefficient of determination of 0.39). From this we can conclude that there is no point in using Twitter only to bluntly redirect users to other resources.
Prediction fees
As a measured value of twitter activity around the film, scientists introduced a tweet coefficient expressing the number of tweets about a movie per hour:
The average correlation coefficient between the tweet coefficient and the sum of box office was 0.90, which shows a strong linear relationship between these values. Building on this, Sitaram and Bernardo conducted a regression analysis of dependency, taking as variables 7 average tweet coefficients for each of the days of the week preceding the premiere of the film.
Already such a model allowed to achieve in the prediction coefficient of determination 0.93, which means a very high predictability of the dependent value. And the introduction as an additional variable number of cinemas, in which the film is planned to be shown, raised the coefficient to 0.973.
At this stage, scientists have found that they have exceeded the accuracy of the forecasts of the Hollywood Stock Exchange (HSX). The diagram below shows the forecast for the tweet coefficient (Tweet-rate) and the HSX forecast in comparison with the absolutely accurate forecast (red line).
Fig. 2. Comparison of the quality of forecasts
You can see that the less box-office film we take for research, the lower the accuracy of the forecasts.
Lightening dark horses and deceived expectations
From the big picture, according to which the proceeds from the film gradually fall over time, there are exceptions. For example, the film “The Unseen Side ” did not start very well ($ 34 million at the box office), but fired the second weekend ($ 40 million). On the other hand, part of the “Twilight” trilogy “ New Moon ”, thanks to advertising, scored $ 142 million on the first weekend, already in the second significantly lost interest of the audience - only $ 42 million on tickets.
The reason - reviews watched the movie audience. If they are positive, it will attract new people to the halls. If negative - scare away those who waited for the movie before the premiere.
To predict such turns, our researchers have taken as a basis the tools of linguistic text analysis available to all: the LingPipe software package and the Amazon Mechanical Turk service , which provides live volunteers for various jobs.
Having taught the package to automatically recognize the mood of each movie tweet (positive, neutral, negative) with an accuracy of 98%, Sitaram and Bernardo introduced the ratio of positive tweets to negative ones as another numerical measure of the potential success of the movie. The higher it is, the more likely it is that people will go to the film.
For the “Invisible Side,” as it turned out, this attitude after the premiere almost doubled (from 5.02 to 9.65). For New Moon, it fell from 6.29 to 5. Using this data in addition to the tweet coefficients already received after the premiere, it is possible to predict charges with high accuracy for a very long time after the “day zero”.
Prediction of the future in general
Of course, the joy of scientists would be incomplete (and their work would be incomplete) if, apart from this particular example, they did not try to consider a general model of predictions.
As a result, they derived a formula for predicting the commercial success of any openly advertised product:
,where y denotes the income received from the product; And - the amount of attention among the audience (similar to the tweet coefficient, measured in various ways, depending on the case); P - mood reviews; D - the parameter of the availability of the product on the market (analogous to the number of cinemas in which the film goes in the considered case). The values of β reflect the regression coefficients , and ε - an error.
Expanding the applicability of this model to other areas of life is the work of the next work. A good goal, for example, will be the prediction of election results. Unless, of course, y is known here in advance.
Source: https://habr.com/ru/post/104218/
All Articles