MySQL in tmpfs
I would like to share my experience in using MySQL with data storage in memory, and not on disk. This allowed us to reduce the load average of the server, which, due to disk operations, began to grow strongly.
')
In one project, we use MySQL with the MyISAM engine for Debian Lenny. General data is loaded into the daemon's operating system in C ++, and user data is loaded once at login and periodically stored while the user is working. Also saved at logout (or by timeout). In view of the described scheme, selects are much smaller than update (select: 24%, delete: 4%, update: 61%, insert: 11%).
In principle, this problem is not an admin one, but is caused by a not entirely successful choice of tool. Most likely, we would have been approached by InnoDB, which uses row-level locking (blocking by records), rather than table-level locking (blocking the entire table while writing) like MyISAM. Although this would hardly reduce the amount of data written to disk. On the other hand, we don’t really need SQL, and we are inclined to porting the project to NoSQL (we’ve got a close look at some of the representatives (assandra), and some (tokyo tyrant, Berkeley DB) we actively use to log user actions). But to allocate time to transfer the data warehouse to another engine / database was not, for this decided to use the admin. resource.
With the increase in the number of users and the introduction of new content, we are faced with the problem of growth of load average on the database server (2-3 la on an 8 core server was observed with only 400 requests per second). And the memory was underloaded, as was the processor. The problem was the large amount of data written to disk (an increase in iowait). At some moments, the system began to stutter and some primitive requests took 2 seconds, or even more. In normal mode, such queries are executed in milliseconds.
We slightly optimized MySQL configs (using both automatic scripts like mysqltuner and manual configuration), but this gave only a slight decrease in load (by 10-15 percent). For the most part, the parameters responsible for caching data are not suitable for us, since our main load is data updating, not reading. The base is on the SAS disk, but the speed is still not enough. Binary logs are on another disk (used for backup of the database from the slave).
Accelerating the work of the disk system having bought a full-fledged RAID does not suit us because of its high price. But the server itself is almost idle, if you do not take into account the disks. There is no possibility of data compression in memory before writing to disk in MyISAM, but there is no possibility to switch to another engine yet (Falcon should have been able to, but Oracle abandoned it after buying MySQL)
The base takes about 2-2.5 Gb (in tar.gz 700mb) and we have long tried to use MySQL in tmpfs (using the mylvmbackup method), which made it possible not to load the disk and simplify the creation of backup. Fortunately, we recently cleaned up the base by adding a crown that removes old users who almost did not use the project and never paid. In addition, we cleared the old data, which was collected for statistics and set them a lifetime of about two months.
As a quick solution to this problem, the idea arose of transferring the main base to tmpfs. What we did:
And so we had 3 servers:
1. server A (the combat base where the demons are knocking (we have 8G of RAM on it))
2. Server B (any server on the same site with free operational (we have 8G, 5G of them are free))
3. Server B (on another site it is sharpened for backups of all projects with maximum RAM (we have 16G))
And so on Server A we raise tmpfs for database files
mount -t tmpfs -o size = 5G tmpfs / var / lib / mysql (with a margin of 2 times the base weight)
Just do not forget to write in the database configs so that the bin logs are written to a single free disk (the master does not work without them), and under load the base can write to these logs up to 1M per second. We store these files for no more than 7 days (more is not necessary because to restore the base if there are slides)
We start the base accordingly as a master. The server under the hard load itself does not go out of 1LA and the memory does not exceed 6G. The average request execution rate has grown tenfold, if earlier it was 0.1-0.3 seconds, it became 0.1-3 ms
Further, on server B, we also raise the first slave in tmpfs as well. Don't forget about the settings of the relay-log, because if there is an error in the slide, and the master will be available in these logs, he will write requests that were on the master ... As a result, this can be measured in dozens of gigabytes per night, before you fix the slide, we have about 8-10 gigabytes per hour. We backup this base with snapshots at night 1-2 times a day when the load on the demons is minimal. Such a slave eats a maximum of 0.2-0.3 LA and a little more than the base weighs.
Also on server B, we have several slides on tmpfs for our projects at once, but they live together without much load, and the server is snapshot once every 10 minutes (if that time is decomposed, then snapshot is done for about 3 seconds (the base weight is 2.5 gigabytes ) well, zhzhati in the archive about 6-7 minutes) and even at the same time on the server LA does not exceed 2, even when backups peresikat time. Apparently the number of backup slaves on one server is determined by the size of the bases and the number of RAM. We store backups for 10 minutes - the last 24 hours, every 6 hours - we keep 30 days, every 30 days - forever.
Then, if Slide B or C suddenly drops, raising it with any of the backups from the other without touching the master without any problems, even if both of them fall to lift without touching the master for 10 minutes - the speed of rewriting backups.
If the master falls, that is, there are two slaves with a lag of 1-2 updates from the master (I have never seen Slave Delay (lag from the master) exceed 0 sec.), While an urgent solution to the problem is to do it within 5 minutes from slave B master ... and rebuild the demons, with the tests they live quietly on the same server and not interfering with each other.
As a result, in order to simultaneously drop 3 cars on 2 different platforms, it is very unlikely that it will take no more than 10 minutes to raise the base for any server or landing.
Be sure to set up sounders (munin, nagios, zabix - someone that is more to your liking) at 2 sites with the measurement of slider lag, by SMS or soap, we have Nagio watching this and at the same time the munin insures it and at the same time draws graphs everything is very clear how and who and how.
Load average on servers decreases autumn strongly, now the processor and memory takes over the main load, not the disk. Here are the graphs that we shot with another server translation today:
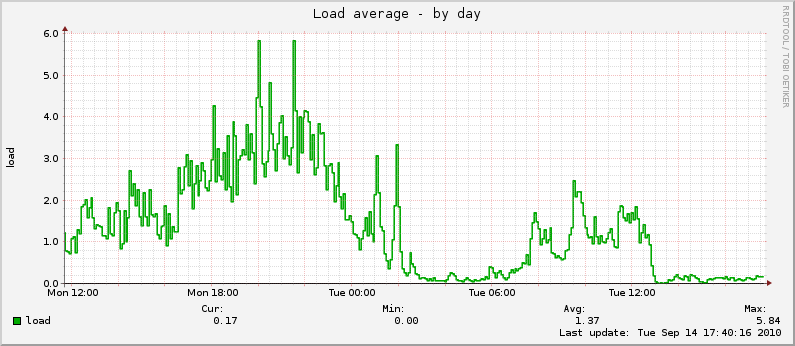
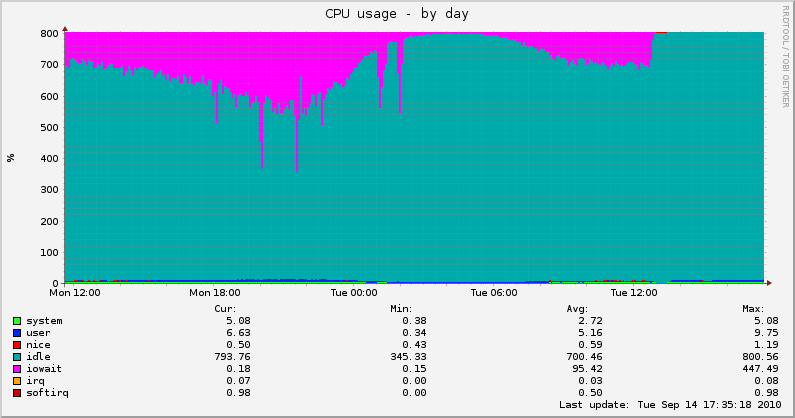
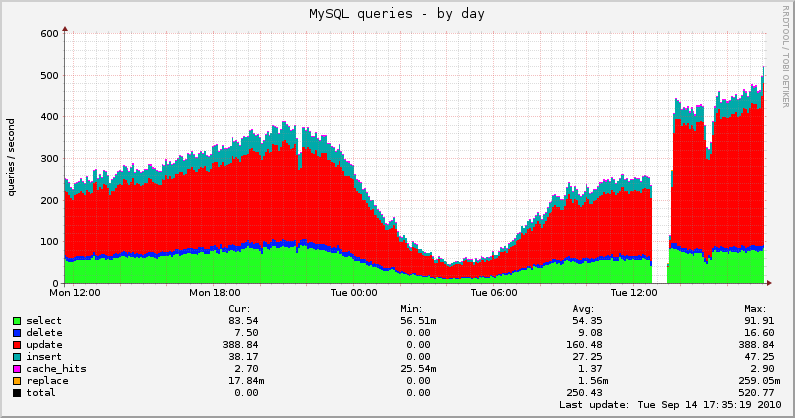
It is worth noting that after transferring the database, the intervals for saving user data in C ++ were also reduced, so the number of updates increased.
In general, the only potential problem is the growth of the base. But now the memory in servers is cheap enough and it won't be a problem to increase it (on the part of the machines we have 16Gb, on the part 8Gb, but as far as I know, you can put 128Gb in the ceiling). In any case, nobody canceled the clustering of the database and we will be able to distribute the database to several servers with a similar configuration.
There is a suspicion that this is not entirely correct, or something. But it was much easier to transfer the base into memory than to implement other databases / engines. If there are any comments I will be glad to read them in the comments.
In any case, perhaps this experience will be useful to someone.
InnoDB - dev.mysql.com/doc/refman/5.1/en/innodb.html
MyISAM - dev.mysql.com/doc/refman/5.1/en/myisam-storage-engine.html
assandra - cassandra.apache.org
tokyo tyrant - fallabs.com/tokyotyrant
Berkeley DB - www.oracle.com/technetwork/database/berkeleydb/overview/index-085366.html
mysqltuner - mysqltuner.com/mysqltuner.pl
Falcon - en.wikipedia.org/wiki/Falcon_ (storage_engine)
tmpfs - en.wikipedia.org/wiki/Tmpfs
mylvmbackup - www.lenzg.net/mylvmbackup
')
In one project, we use MySQL with the MyISAM engine for Debian Lenny. General data is loaded into the daemon's operating system in C ++, and user data is loaded once at login and periodically stored while the user is working. Also saved at logout (or by timeout). In view of the described scheme, selects are much smaller than update (select: 24%, delete: 4%, update: 61%, insert: 11%).
In principle, this problem is not an admin one, but is caused by a not entirely successful choice of tool. Most likely, we would have been approached by InnoDB, which uses row-level locking (blocking by records), rather than table-level locking (blocking the entire table while writing) like MyISAM. Although this would hardly reduce the amount of data written to disk. On the other hand, we don’t really need SQL, and we are inclined to porting the project to NoSQL (we’ve got a close look at some of the representatives (assandra), and some (tokyo tyrant, Berkeley DB) we actively use to log user actions). But to allocate time to transfer the data warehouse to another engine / database was not, for this decided to use the admin. resource.
With the increase in the number of users and the introduction of new content, we are faced with the problem of growth of load average on the database server (2-3 la on an 8 core server was observed with only 400 requests per second). And the memory was underloaded, as was the processor. The problem was the large amount of data written to disk (an increase in iowait). At some moments, the system began to stutter and some primitive requests took 2 seconds, or even more. In normal mode, such queries are executed in milliseconds.
We slightly optimized MySQL configs (using both automatic scripts like mysqltuner and manual configuration), but this gave only a slight decrease in load (by 10-15 percent). For the most part, the parameters responsible for caching data are not suitable for us, since our main load is data updating, not reading. The base is on the SAS disk, but the speed is still not enough. Binary logs are on another disk (used for backup of the database from the slave).
Accelerating the work of the disk system having bought a full-fledged RAID does not suit us because of its high price. But the server itself is almost idle, if you do not take into account the disks. There is no possibility of data compression in memory before writing to disk in MyISAM, but there is no possibility to switch to another engine yet (Falcon should have been able to, but Oracle abandoned it after buying MySQL)
The base takes about 2-2.5 Gb (in tar.gz 700mb) and we have long tried to use MySQL in tmpfs (using the mylvmbackup method), which made it possible not to load the disk and simplify the creation of backup. Fortunately, we recently cleaned up the base by adding a crown that removes old users who almost did not use the project and never paid. In addition, we cleared the old data, which was collected for statistics and set them a lifetime of about two months.
As a quick solution to this problem, the idea arose of transferring the main base to tmpfs. What we did:
And so we had 3 servers:
1. server A (the combat base where the demons are knocking (we have 8G of RAM on it))
2. Server B (any server on the same site with free operational (we have 8G, 5G of them are free))
3. Server B (on another site it is sharpened for backups of all projects with maximum RAM (we have 16G))
And so on Server A we raise tmpfs for database files
mount -t tmpfs -o size = 5G tmpfs / var / lib / mysql (with a margin of 2 times the base weight)
Just do not forget to write in the database configs so that the bin logs are written to a single free disk (the master does not work without them), and under load the base can write to these logs up to 1M per second. We store these files for no more than 7 days (more is not necessary because to restore the base if there are slides)
We start the base accordingly as a master. The server under the hard load itself does not go out of 1LA and the memory does not exceed 6G. The average request execution rate has grown tenfold, if earlier it was 0.1-0.3 seconds, it became 0.1-3 ms
Further, on server B, we also raise the first slave in tmpfs as well. Don't forget about the settings of the relay-log, because if there is an error in the slide, and the master will be available in these logs, he will write requests that were on the master ... As a result, this can be measured in dozens of gigabytes per night, before you fix the slide, we have about 8-10 gigabytes per hour. We backup this base with snapshots at night 1-2 times a day when the load on the demons is minimal. Such a slave eats a maximum of 0.2-0.3 LA and a little more than the base weighs.
Also on server B, we have several slides on tmpfs for our projects at once, but they live together without much load, and the server is snapshot once every 10 minutes (if that time is decomposed, then snapshot is done for about 3 seconds (the base weight is 2.5 gigabytes ) well, zhzhati in the archive about 6-7 minutes) and even at the same time on the server LA does not exceed 2, even when backups peresikat time. Apparently the number of backup slaves on one server is determined by the size of the bases and the number of RAM. We store backups for 10 minutes - the last 24 hours, every 6 hours - we keep 30 days, every 30 days - forever.
Then, if Slide B or C suddenly drops, raising it with any of the backups from the other without touching the master without any problems, even if both of them fall to lift without touching the master for 10 minutes - the speed of rewriting backups.
If the master falls, that is, there are two slaves with a lag of 1-2 updates from the master (I have never seen Slave Delay (lag from the master) exceed 0 sec.), While an urgent solution to the problem is to do it within 5 minutes from slave B master ... and rebuild the demons, with the tests they live quietly on the same server and not interfering with each other.
As a result, in order to simultaneously drop 3 cars on 2 different platforms, it is very unlikely that it will take no more than 10 minutes to raise the base for any server or landing.
Be sure to set up sounders (munin, nagios, zabix - someone that is more to your liking) at 2 sites with the measurement of slider lag, by SMS or soap, we have Nagio watching this and at the same time the munin insures it and at the same time draws graphs everything is very clear how and who and how.
Load average on servers decreases autumn strongly, now the processor and memory takes over the main load, not the disk. Here are the graphs that we shot with another server translation today:
It is worth noting that after transferring the database, the intervals for saving user data in C ++ were also reduced, so the number of updates increased.
In general, the only potential problem is the growth of the base. But now the memory in servers is cheap enough and it won't be a problem to increase it (on the part of the machines we have 16Gb, on the part 8Gb, but as far as I know, you can put 128Gb in the ceiling). In any case, nobody canceled the clustering of the database and we will be able to distribute the database to several servers with a similar configuration.
There is a suspicion that this is not entirely correct, or something. But it was much easier to transfer the base into memory than to implement other databases / engines. If there are any comments I will be glad to read them in the comments.
In any case, perhaps this experience will be useful to someone.
InnoDB - dev.mysql.com/doc/refman/5.1/en/innodb.html
MyISAM - dev.mysql.com/doc/refman/5.1/en/myisam-storage-engine.html
assandra - cassandra.apache.org
tokyo tyrant - fallabs.com/tokyotyrant
Berkeley DB - www.oracle.com/technetwork/database/berkeleydb/overview/index-085366.html
mysqltuner - mysqltuner.com/mysqltuner.pl
Falcon - en.wikipedia.org/wiki/Falcon_ (storage_engine)
tmpfs - en.wikipedia.org/wiki/Tmpfs
mylvmbackup - www.lenzg.net/mylvmbackup
Source: https://habr.com/ru/post/104217/
All Articles