Gcc vs Intel C ++ Compiler: build FineReader Engine for Linux
The prerequisite for writing this article was a completely natural desire to improve the performance of the FineReader Engine.
It is believed that the compiler from Intel produces a much faster code than gcc. And it would be nice to increase the recognition speedwithout doing anything just by assembling the FR Engine with another compiler.
At the moment, the FineReader Engine is not built by the most recent compiler - gcc 4.2.4. It's time to move on to something more modern. We considered two alternatives - this is the new version of gcc - 4.4.4, and the compiler from Intel is the Intel C ++ Compiler (icc).
')
Porting a large project to a new compiler may not be the easiest thing to do, so for a start we decided to test the compilers on the benchmark .
Here are the brief results on the Intel Core2 Duo processor:
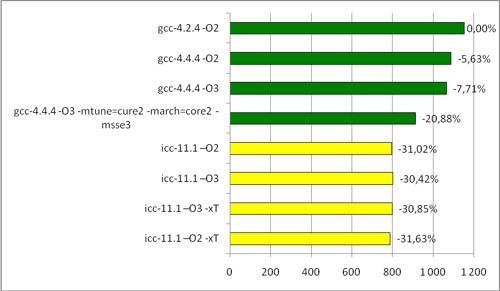
Time of povray test on an Intel processor (sec)
AMD was also interesting to see:
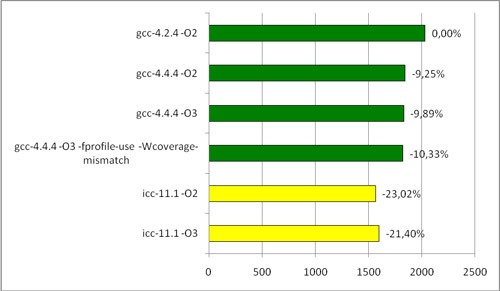
Time povray- test on AMD processor (sec)
Briefly about the flags:
-O1, -O2 and -O3 - various levels of optimization.
For gcc, the best option is –O3, and it is used almost everywhere when building the FineReader Engine.
For icc, the optimal option is -O2, and -O3 includes some additional optimization of the cycles, which, however, may not work.
-mtune = core2 -march = core2 -msse3 - optimization for a specific processor, in this case for Core2 Duo.
-xT is a similar flag for the compiler from Intel.
-fprofile-use - PGO
Tests with optimizations for a specific processor are given just for fun. A binary compiled with one processor optimized may not run on another. FineReader Engine should not be tied to a specific processor, therefore, such optimizations cannot be used.
So, apparently, a performance boost is possible: icc speeds up on an Intel processor very significantly. On AMD, it behaves more modestly , but it still gives a good gain compared to gcc.
It's time to move on to what we all have started, the assembly of the FineReader Engine. We compiled FineReader Engine with different compilers, started recognition on a package of images. Here are the results:
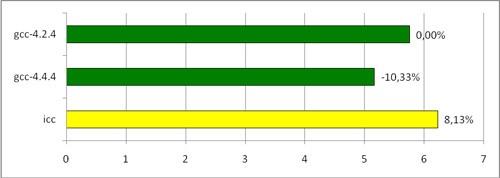
Hours of FREngine compiled by various compilers (seconds per page)
Unexpected result. The ratio of gcc-4.4.4 / gcc-4.2.4 is quite consistent with the measurements on the benchmark, and even slightly exceeds expectations. But what about icc? He loses not only the new gcc, but gcc two years ago!
We went to oprofile for the truth, and this is what we found out: in some (quite rare) cases, icc has problems with loop optimization. Here is the code that I managed to write based on the results of the profiling:
By running the function on different input data, we got something like this:
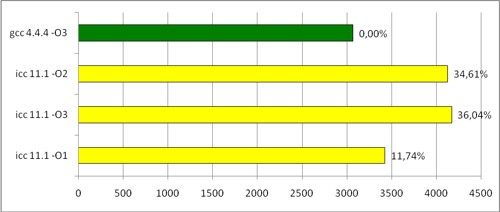
Cycle time (ms)
Adding other optimization flags didn’t give tangible results, so I’ve just listed the main ones.
Unfortunately, Intel does not explicitly indicate what -O1, -O2, and -O3 include, so it was not possible to figure out exactly which optimization caused the code to slow down. In fact, in most cases, icc optimizes cycles better, but in some special cases (like the one above) there are difficulties.
With the help of profiling, we managed to find another, more serious problem. In the profiler report for the version of FineReader Engine, compiled by icc, at a fairly high position was a similar line:
while in the gcc version there was no such function at all.
A :: GetValue () returns a simple structure containing several fields. Most often, this method is called for a global constant object in the construction of the form
which is of type int. All the above Get .. () methods are trivial - they simply return some field of the object (by value or by reference). Thus, GetValue () returns an object with several fields, after which GetField () pulls out one of these fields. In this case, instead of permanently copying the entire structure in order to pull out just one field, it is quite possible to turn the chain into one call that returns the desired number. In addition, all the fields of the GlobalConstObject object are known (can be calculated) at the compilation stage, so the chain of these methods can be replaced with a constant.
gcc does just that (at least it avoids unnecessary construction), however icc with the included -O2 or -O3 optimizations leaves everything as it is. And given the number of such calls, this place becomes critical, although no useful work is being done here.
Now about the methods of treatment:
1) Automatic. Icc has a wonderful -ipo flag that asks the compiler to perform interprocedural optimization , besides between files. Here is what is written about this in Intel's optimization manuals:
It seems that this is what you need. Everything would be fine, but FineReader Engine contains a huge amount of code. Attempting to launch it with the -ipo flag meant that the linker (namely, it performs ipo) took up all the memory, the entire swap, and only the page recognition module (the largest one, however) collected for several hours. Hopelessly.
2) Manual. If you manually replace the call chain with a constant everywhere in the code, the Intel compiler produces a good performance increase with respect to the old results.
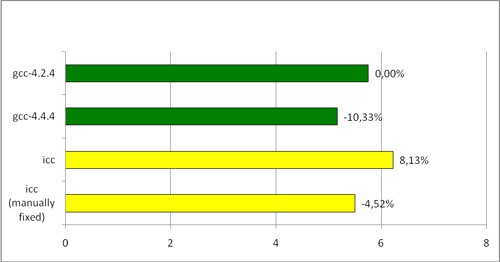
The last line is the version compiled by icc, where in the most critical places the call chain has been replaced with a constant. As you can see, this allowed icc to run faster than gcc-4.2.4, but still slower than gcc-4.4.4.
You can try to catch all such critical places and manually correct the code. The drawback is obvious - it will take a huge amount of time and effort.
3) Combined. You can build with the -ipo flag not the whole module, but only some of its parts. This will give an acceptable compile time. However, which files should be compiled with this flag will have to be determined manually, which again potentially leads to high labor costs.
So, we summarize. Intel C ++ Compiler is potentially good. But due to the features described above and a large amount of code, we decided that it does not give a significant gain in speed - significant enough to justify the labor costs of porting and “sharpening” the code for this compiler.
It is believed that the compiler from Intel produces a much faster code than gcc. And it would be nice to increase the recognition speed
At the moment, the FineReader Engine is not built by the most recent compiler - gcc 4.2.4. It's time to move on to something more modern. We considered two alternatives - this is the new version of gcc - 4.4.4, and the compiler from Intel is the Intel C ++ Compiler (icc).
')
Porting a large project to a new compiler may not be the easiest thing to do, so for a start we decided to test the compilers on the benchmark .
Here are the brief results on the Intel Core2 Duo processor:
Time of povray test on an Intel processor (sec)
AMD was also interesting to see:
Time povray- test on AMD processor (sec)
Briefly about the flags:
-O1, -O2 and -O3 - various levels of optimization.
For gcc, the best option is –O3, and it is used almost everywhere when building the FineReader Engine.
For icc, the optimal option is -O2, and -O3 includes some additional optimization of the cycles, which, however, may not work.
-mtune = core2 -march = core2 -msse3 - optimization for a specific processor, in this case for Core2 Duo.
-xT is a similar flag for the compiler from Intel.
-fprofile-use - PGO
Tests with optimizations for a specific processor are given just for fun. A binary compiled with one processor optimized may not run on another. FineReader Engine should not be tied to a specific processor, therefore, such optimizations cannot be used.
So, apparently, a performance boost is possible: icc speeds up on an Intel processor very significantly. On AMD, it behaves more modestly , but it still gives a good gain compared to gcc.
It's time to move on to what we all have started, the assembly of the FineReader Engine. We compiled FineReader Engine with different compilers, started recognition on a package of images. Here are the results:
Hours of FREngine compiled by various compilers (seconds per page)
Unexpected result. The ratio of gcc-4.4.4 / gcc-4.2.4 is quite consistent with the measurements on the benchmark, and even slightly exceeds expectations. But what about icc? He loses not only the new gcc, but gcc two years ago!
We went to oprofile for the truth, and this is what we found out: in some (quite rare) cases, icc has problems with loop optimization. Here is the code that I managed to write based on the results of the profiling:
static const int aim = ..;
static const int range = ..;
int process( int * line, int size )
{
int result = 0;
for ( int i = 0; i < size; i++ ) {
if ( line[i] == aim ) {
result += 2;
} else {
if ( line[i] < aim - range || line[i] > aim + range ) {
result--;
} else {
result++;
}
}
}
return result;
}
* This source code was highlighted with Source Code Highlighter .By running the function on different input data, we got something like this:
Cycle time (ms)
Adding other optimization flags didn’t give tangible results, so I’ve just listed the main ones.
Unfortunately, Intel does not explicitly indicate what -O1, -O2, and -O3 include, so it was not possible to figure out exactly which optimization caused the code to slow down. In fact, in most cases, icc optimizes cycles better, but in some special cases (like the one above) there are difficulties.
With the help of profiling, we managed to find another, more serious problem. In the profiler report for the version of FineReader Engine, compiled by icc, at a fairly high position was a similar line:
Namespace::A::GetValue() const ( )while in the gcc version there was no such function at all.
A :: GetValue () returns a simple structure containing several fields. Most often, this method is called for a global constant object in the construction of the form
GlobalConstObject.GetValue().GetField()which is of type int. All the above Get .. () methods are trivial - they simply return some field of the object (by value or by reference). Thus, GetValue () returns an object with several fields, after which GetField () pulls out one of these fields. In this case, instead of permanently copying the entire structure in order to pull out just one field, it is quite possible to turn the chain into one call that returns the desired number. In addition, all the fields of the GlobalConstObject object are known (can be calculated) at the compilation stage, so the chain of these methods can be replaced with a constant.
gcc does just that (at least it avoids unnecessary construction), however icc with the included -O2 or -O3 optimizations leaves everything as it is. And given the number of such calls, this place becomes critical, although no useful work is being done here.
Now about the methods of treatment:
1) Automatic. Icc has a wonderful -ipo flag that asks the compiler to perform interprocedural optimization , besides between files. Here is what is written about this in Intel's optimization manuals:
The IPO allows you to make a list of optimizations:
• Inline function expansion of calls, jumps, branches and loops.
• Interprocedural constant propagation for global variables and return values.
• Monitoring module-level invariant code.
• Dead code elimination to reduce code size.
• Propagation of function characteristics
• Identification of loop-invariant code for invariant code.
It seems that this is what you need. Everything would be fine, but FineReader Engine contains a huge amount of code. Attempting to launch it with the -ipo flag meant that the linker (namely, it performs ipo) took up all the memory, the entire swap, and only the page recognition module (the largest one, however) collected for several hours. Hopelessly.
2) Manual. If you manually replace the call chain with a constant everywhere in the code, the Intel compiler produces a good performance increase with respect to the old results.
The last line is the version compiled by icc, where in the most critical places the call chain has been replaced with a constant. As you can see, this allowed icc to run faster than gcc-4.2.4, but still slower than gcc-4.4.4.
You can try to catch all such critical places and manually correct the code. The drawback is obvious - it will take a huge amount of time and effort.
3) Combined. You can build with the -ipo flag not the whole module, but only some of its parts. This will give an acceptable compile time. However, which files should be compiled with this flag will have to be determined manually, which again potentially leads to high labor costs.
So, we summarize. Intel C ++ Compiler is potentially good. But due to the features described above and a large amount of code, we decided that it does not give a significant gain in speed - significant enough to justify the labor costs of porting and “sharpening” the code for this compiler.
Source: https://habr.com/ru/post/103447/
All Articles