Are relational databases doomed?
Translator's note: although the article is quite old (published 2 years ago) and has a loud title, it still gives a good idea of the differences between relational databases and NoSQL databases, their advantages and disadvantages, and also provides a brief overview of non-relational repositories.
Recently, many non-relational databases have appeared. This suggests that if you need almost unlimited scalability on demand, you need a non-relational database.
If this is true, does this mean that powerful relational databases have become vulnerable? Does this mean that the days of relational databases pass and soon will pass? In this article we will look at the popular course of non-relational databases in relation to various situations and see if this will affect the future of relational databases.
Relational databases have been around for about 30 years. During this time, several revolutions broke out that were supposed to put an end to relational repositories. Of course, none of these revolutions took place, and one of them did not shake the position of relational databases one iota.
Let's start with the basics
A relational database is a set of tables (entities). Tables consist of columns and rows (tuples). Restrictions can be defined inside the tables, relations exist between the tables. Using SQL, you can execute queries that return data sets derived from one or more tables. Within a single query, data is obtained from several tables by joining them (JOIN), most often the same columns are used for joining, which define the relationships between the tables. Normalization is the process of structuring the data model, ensuring connectivity and lack of redundancy in the data.
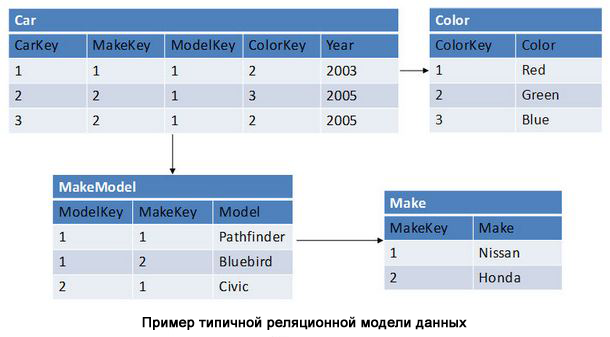
Access to relational databases is provided through relational database management systems (RDBMS). Almost all the database systems we use are relational, such as Oracle, SQL Server, MySQL, Sybase, DB2, TeraData, and so on.
')
The reasons for this dominance are not obvious. Throughout the existence of relational databases, they have consistently offered the best mix of simplicity, robustness, flexibility, performance, scalability, and compatibility in data management.
However, to provide all these features, relational storage is incredibly complex inside. For example, a simple SELECT query can have hundreds of potential execution paths that the optimizer will evaluate directly during query execution. All this is hidden from users, but inside the RDBMS it creates an execution plan based on things like cost estimation algorithms and best responding to the request.
Relational Database Problems
Although relational storage and provide the best mix of simplicity, stability, flexibility, performance, scalability and compatibility, their performance on each of these items is not necessarily higher than that of similar systems, focused on any one feature. This was not a big problem, since the overall dominance of relational DBMS outweighed any shortcomings. However, if ordinary RBD did not meet the needs, alternatives always existed.
Today the situation is a bit different. A variety of applications is growing, and with it growing and the importance of these features. And with the increasing number of databases, one feature begins to overshadow all others. This is scalability. Since more and more applications are working under high load conditions, such as web services, for example, their scalability requirements can change very quickly and grow dramatically. The first problem can be very difficult to resolve if you have a relational database located on your own server. Suppose the server load overnight has tripled. How fast can you upgrade your hardware? The solution of the second problem also causes difficulties in the case of using relational databases.
Relational databases scale well only if they are located on a single server. When resources of this server run out, you will need to add more machines and distribute the load between them. And here the complexity of relational databases starts to play against scalability. If you try to increase the number of servers not to a few pieces, but to a hundred or thousands, the complexity will increase by an order of magnitude, and the characteristics that make relational databases so attractive quickly reduce to zero the chances of using them as a platform for large distributed systems.
To remain competitive, cloud service vendors have to somehow deal with this limitation, because what kind of cloud platform is there without a scalable data warehouse. Therefore, vendors are left with only one option if they want to provide users with a scalable place to store data. It is necessary to use other types of databases that have a higher ability to scale, albeit at the price of other features available in relational databases.
These advantages, as well as the existing demand for them, led to a wave of new database management systems.
New wave
This type of database is usually called a key-value store. In fact, there is no official name, so you can meet it in the context of document-oriented, attribute-oriented, distributed databases (although they can also be relational), shard sorted arrays, distributed hash tables and storages. type key value And although each of these names indicates specific features of the system, all of them are variations on a topic that we will call a key-value type repository.
However, no matter how you call it, this “new” type of database is not so new and has always been used mainly for applications for which the use of relational databases would be unsuitable. However, without the need of the web and the "cloud" in scalability, these systems were not much in demand. Now the task is to determine which type of storage is more suitable for a particular system.
Relational databases and key-value storages differ radically and are designed to solve different tasks. Comparison of characteristics will allow only to understand the difference between them, but let's start with this:
Storage Characteristics
| Relational database | Key-value store |
|---|---|
| The database consists of tables, the tables contain columns and rows, and the rows consist of column values. All rows of one table have a single structure. | For domains it is possible to draw an analogy with tables, but unlike tables for domains, the data structure is not defined. Domain - this is a box in which you can put anything. Entries within one domain can have different structure. |
| Data model 1 is predefined. It is strongly typed, contains constraints and relationships to ensure data integrity. | Records are identified by key, with each record having a dynamic set of attributes associated with it. |
| The data model is based on the natural representation of the data contained, and not on the functionality of the application. | In some implementations, attributes can only be string. In other implementations, attributes have simple data types that reflect the types used in programming: integers, an array of strings, and lists. |
| The data model undergoes normalization to avoid data duplication. Normalization generates relationships between tables. Relationships link data from different tables. | Between the domains, as well as within the same domain, the relationship is not clearly defined. |
No join'ov
Key-value storages are oriented to work with records. This means that all information relating to this record is stored with it. A domain (which you can think of as a table) can contain countless different entries. For example, a domain may contain information about customers and orders. This means that data is usually duplicated between different domains. This is an acceptable approach because disk space is cheap. The main thing is that it allows you to store all related data in one place, which improves scalability, since there is no need to join data from different tables. When using a relational database, you would need to use connections to group the information you need into one place.
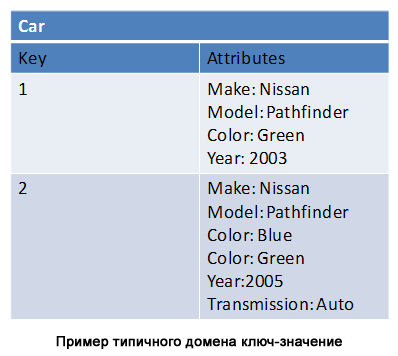
Although the need for relationships drops sharply to store key-value pairs, relationships are still needed. Such relationships usually exist between core entities. For example, an ordering system would have records that contain data about customers, products, and orders. It does not matter if the data is in the same domain or in several. The bottom line is that when a buyer places an order, you most likely will not want to store information about the buyer and the order in one record.
Instead, the order record must contain keys that indicate the corresponding customer and item records. Since any information can be stored in records, and relations are not defined in the data model itself, the database management system will not be able to control the integrity of the relations. This means that you can delete buyers and products that they ordered. Ensuring data integrity rests entirely on the application.
Data access
| Relational database | Key-value store |
|---|---|
| Data is created, updated, deleted, and queried using the Structured Query Language (SQL). | Data is created, updated, deleted, and queried using API call methods. |
| SQL queries can retrieve data from a single table or from several tables, using joins. | Some implementations provide SQL-like syntax for specifying filter conditions. |
| SQL queries can include aggregations and complex filters. | Often, you can only use the basic comparison operators (=,! =, <,>, <= And =>). |
| A relational database usually contains embedded logic, such as triggers, stored procedures, and functions. | All business logic and logic to maintain data integrity is contained in the application code. |
Interaction with applications
| Relational database | Key-value store |
|---|---|
| The most commonly used proprietary APIs, or generic ones, such as OLE DB or ODBC. | The most commonly used are SOAP and / or REST API, which is used to access data. |
| Data is stored in a format that displays their natural structure, therefore, mapping of application structures and relational database structures is necessary. | Data can be more effectively displayed in the structure of the application, you need only the code to write data to objects. |
Key-Value Storages: Benefits
There are two clear advantages of such systems over relational repositories.
Suitable for cloud services
The first advantage of key-value storages is that they are simpler, and therefore have greater scalability than relational databases. If you place your own system together, and plan to place a dozen or a hundred servers that need to cope with the increasing load, behind your data storage, then your choice is key-value storage.
Due to the fact that such storage is easily and dynamically expanded, they will also be useful to vendors who provide a multi-user web storage platform. Such a database is a relatively cheap data storage facility with great potential for scalability. Users usually pay only for what they use, but their needs may increase. The vendor will be able to dynamically and practically without restrictions increase the size of the platform, based on the load.
More natural integration with code
The relational data model and code object model are usually built differently, which leads to some incompatibility. Developers solve this problem by writing code that maps the relational model to the object model. This process has no clear and fast achievable value and can take quite a long time, which could be spent on developing the application itself. Meanwhile, many key-value storages store data in a structure that maps to objects more naturally. This can significantly reduce development time.
Other arguments in favor of using key-value storages, like “Relational bases can become clumsy” (by the way, I have no idea what this means) are less convincing. But before you become a supporter of such repositories, read the following section.
Key-value storages: disadvantages
Constraints in relational databases guarantee data integrity at the lowest level. Data that does not satisfy the constraints cannot physically enter the database. In the key-value storages there are no such restrictions, therefore the integrity control of the data lies entirely on applications. However, in any code there are errors. If errors in a properly designed relational database usually do not lead to data integrity problems, then errors in key-value storages usually lead to such problems.
Another advantage of relational databases is that they force you to go through the process of developing a data model. If you have a well-designed model, then the database will contain a logical structure that fully reflects the structure of the stored data, but it is at odds with the structure of the application. Thus, the data becomes independent of the application. This means that another application can use the same data and the application logic can be changed without any changes in the base model. To do the same with a key-value type repository, try replacing the design process of the relational model with a class design that creates common classes based on a natural data structure.
And do not forget about compatibility. Unlike relational databases, cloud-oriented storage has far less common standards. Although conceptually they are not different, they all have different APIs, query interfaces, and their own specifics. Therefore, you better trust your vendor, because if something happens, you can not easily switch to another service provider. And given the fact that almost all modern key-value storages are in beta 2 , trusting becomes even more risky than using relational databases.
Limited data analytics
Typically, all cloud storage is built on the type of multiple leases , which means that a large number of users and applications use the same system. To prevent the system from “capturing”, vendors usually somehow limit the execution of requests. For example, in SimpleDB, a request cannot be executed for more than 5 seconds. In Google AppEngine Datastore for one request can not get more than 1000 records 3 .
These restrictions are not terrible for simple logic (creating, updating, deleting and extracting a small number of records). But what if your application becomes popular? You have received a lot of new users and a lot of new data, and now you want to make new opportunities for users or somehow benefit from the data. Here you can break off hard with even simple queries for data analysis. Features like tracking application usage patterns or a recommendation system based on user history can be difficult to implement at best. And at worst - simply impossible.
In this case, for analytics, it is better to make a separate database that will be populated with data from your key-value storage. Think in advance how this can be done. Will you host the server in the cloud or at home? Will there be problems due to signal delays between you and your provider? Does your repository support such data transfer? If you have 100 million records, and you can take 1000 records at a time, how much will it take to transfer all the data?
However, do not put scalability above all else. It will be useless if your users decide to use the services of another service, because it provides more features and settings.
Cloud Storage
Many web service providers offer multiuser key-value storages. Most of them meet the criteria listed above, but each has its own distinctive features and differs from the standards described above. Let's take a look at specific sample repositories, such as SimpleDB, Google AppEngine Datastore, and SQL Data Services.
Amazon: SimpleDB
SimpleDB is an attribute-oriented key-value store included in Amazon WebServices. SimpleDB is in beta; users can use it for free - until their needs exceed a certain limit.

SimpleDB has several limitations. The first is that the query execution time is limited to 5 seconds. The second is that there are no data types other than strings. Everything is stored, retrieved and compared as a string, so in order to compare dates, you will need to convert them to ISO8601 format. Third - the maximum size of any string is 1024 bytes, which limits the size of the text (for example, the description of the goods), which you can store as an attribute. However, since the data structure is flexible, you can circumvent this limitation by adding the attributes “Description of the Product1”, “Description of the Product2”, etc. But the number of attributes is also limited - a maximum of 256 attributes. While SimpleDB is in beta, the domain size is limited to 10 gigabytes, and the entire database cannot occupy more than 1 terabyte.
One of the key features of SimpleDB is the use of the eventual consistency model . This model is suitable for multi-threaded work, but it should be borne in mind that after you change the value of an attribute in a record, these changes may not be visible on subsequent read operations. The probability of such a development is quite low, however, it must be remembered. You do not want to sell the last ticket to five customers just because your data was inconsistent at the time of sale.
Google AppEngine Data Store
Google's AppEngine Datastore is based on BigTable, Google’s internal structured data storage system. AppEngine Datastore does not provide direct access to BigTable, but can be perceived as a simplified interface for interacting with BigTable.

AppEngine Datastore supports more data types within one record than SimpleDB. For example, lists that may contain collections within an entry.
Most likely you will use this particular data warehouse when developing using Google AppEngine. However, unlike SimpleDB, you cannot use AppEngine Datastore (or BigTable) outside of Google’s web services.
Microsoft: SQL Data Services

SQL Data Services is part of the Microsoft Azure platform. SQL Data Services is free, is in beta, and has a database size limit. SQL Data Services is a separate application - an add-on over a variety of SQL servers that store data. These storages can be relational, but for you SDS is a key-value store, just like the products described above.
Cloud storage
There are also a number of repositories that you can use outside the cloud by installing them. Almost all of these projects are young, are in alpha or beta, and are open source. With open source, you may be more aware of the potential problems and limitations than if you use unopened products.
Couchdb
CouchDB is a free, open source, document-oriented database. JSON is used as a data storage format. CouchDB is designed to fill the gap between document-oriented and relational databases using “views”. Such views contain data from documents in a form similar to tabular, and allow you to build indexes and execute queries.

Currently CouchDB is not a truly distributed database. It has replication functions that allow you to synchronize data between servers, but this is not the distribution that is needed to build a highly scalable environment. However, CouchDB developers are working on this.
Voldemort Project
The Voldemort project is a distributed key-value database designed for horizontal scaling across a large number of servers. It was born in the development process of LinkedIn and was used for several systems that have high scalability requirements. The Voldemort project also uses the final consistency model.
Mongo

Mongo is a database developed in 10gen by Geir Magnusson and Dwight Merriman (which you may know from DoubleClick). Like CouchDB, Mongo is a document-oriented database that stores data in JSON format. However, Mongo is more of an object base than a pure key-value store.
Drizzle

Drizzle represents a completely different approach to solving problems that key-value storages are designed to combat. Drizzle began as one of the MySQL 6.0 branches. Later, developers removed a number of functions (including views, triggers, compiled expressions, stored procedures, query cache, ACL, and some data types) in order to create a simpler and faster DBMS. However, Drizzle can still be used to store relational data. The goal of the developers is to build a semi-relational platform designed for web and cloud applications running on systems with 16 or more cores.
Decision
Ultimately, there are four reasons why you can choose a non-relational key-value store for your application:
- Your data is very document-oriented, and more suitable for a key-value data model than for a relational model.
- Your domain model is strongly object-oriented, so using a key-value store will reduce the size of additional code for data conversion.
- Data storage is cheap and easy to integrate with your vendor's web services.
- Your main problem is high scalability on demand.
However, when making a decision, keep in mind the limitations of specific databases and the risks that you will encounter when you follow the path of using non-relational databases.
For all other requirements it is better to choose good old relational DBMS. So are they doomed? Of course not. At least for now.
1 - in my opinion, the term “data structure” is more appropriate here, but left the original data model.
2 - most likely, the author had in mind that non-relational databases are inferior in their capabilities to relational databases.
3 - the data may already be outdated, the article dates back to February 2009.
Source: https://habr.com/ru/post/103021/
All Articles