Overview of index types Oracle, MySQL, PostgreSQL, MS SQL
In one of the comments there was a request to tell more about the indices, and since, in RuNet, there is practically no summary of the supported indices of various DBMSs, in this review I will look at which types of indices are supported in the most popular DBMS
The B-Tree index family is the most commonly used type of index, organized as a balanced tree, of ordered keys. They are supported by almost all DBMS, both relational and non-relational, and for almost all types of data.
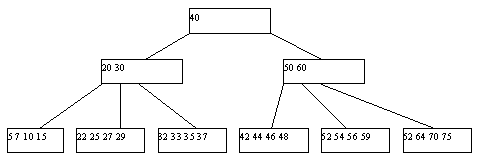
Since most probably know them well (or can read about them, for example, here ), the only thing that should perhaps be noted here is that this type of index is optimal for a set with a good distribution of values and high power (cardinality -number of unique values).
')
Currently, all DBMS data has spatial data types and functions for working with them, for Oracle it is a set of types and functions in the MDSYS schema, for PostgreSQL it is point, line, lseg, polygon, box, path, polygon, circle, in MySQL - geometry, point, linestring, polygon, multipoint, multilinestring, multipolygon, geometrycollection, MS SQL - Point, MultiPoint, LineString, MultiLineString, Polygon, MultiPolygon, GeometryCollection.
In the scheme of work of spatial queries, usually there are two stages or two stages of filtering. DBMS with weak spatial support work out only the first stage (coarse filtering, MySQL). As a rule, an approximate, approximate representation of objects is used at this stage. The most common type of approximation is the Minimum Bounding Rectangle (MBR) [100].
For spatial data types, there are special indexing methods based on R-trees (R-Tree index) and grids (Grid-based Spatial index).
Spatial grid (spatial grid) index is a tree-like structure similar to a B-tree, but is used to provide access to spatial (Spatial) data, that is, to index multi-dimensional information, such as geographic data with two-dimensional coordinates (latitude and longitude). ). In this structure, the nodes of the tree are the cells of space. For example, for a two-dimensional space: first, the entire parent area will be divided into a grid of strictly defined resolution, then each grid cell in which the number of objects exceeds the maximum set of objects in the cell will be divided into the next level subgrid. This process will continue until the maximum nesting is reached (if set), or until everything is divided up to cells that do not exceed the maximum objects.

In the case of three-dimensional or multidimensional space, these will be rectangular parallelepipeds (cuboids) or parallelotopes.
Quadtree is a subspecies of the Grid-based Spatial index, in which there are always 4 descendants in the parent cell and the grid resolution varies depending on the nature or complexity of the data.

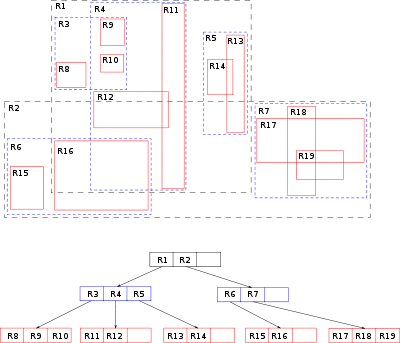
R-Tree (Regions Tree) is also a tree-like data structure similar to the Spatial Grid, proposed in 1984 by Antonin Guttman. This data structure also divides the space into many hierarchically nested cells, but which, unlike the Spatial Grid, do not have to completely cover the parent cell and can intersect.
Various algorithms can be applied to splitting overflowed vertices, which causes the division of R-trees into subtypes: with quadratic and linear complexity (Guttman, of course, described with exponential complexity — Exhaustive Search, but naturally he is not used anywhere).
The quadratic subtype is divided into two rectangles with a minimum area covering all objects. Linear - in the division by maximum distance.
Hash indices were proposed by Arthur Fuller, and they do not preserve the values themselves, but their hashes, thereby reducing the size (and, accordingly, their processing speed) of indices from large fields. Thus, when querying using HASH indexes, the hash from the desired value will not be compared with the field hashes, but with the hashes of the fields.
Due to the non-linearity of hash functions, this index cannot be sorted by value, which leads to the impossibility of using more / less and “is null” in comparisons. In addition, since hashes are not unique, collision resolution methods are used for matching hashes.
Bitmap index - the bit index method consists in creating separate bitmaps (sequence 0 and 1) for each possible value of the column, where each bit corresponds to a row with an indexed value, and its value equal to 1 means that the entry corresponding to the bit position contains the indexed value for this column or property.
Bit cards
The main advantage of bit indices is that on large sets with low power and good clustering by their values, the index will be less than B * -tree. (Read more here or here )
Reverse index is also a B-tree index but with a reversed key, used mainly for monotonously increasing values (for example, an auto-incrementing identifier) in OLTP systems in order to remove competition for the last leaf block of the index, since due to the reversal of the value, two adjacent index entries fall into different index blocks. It cannot be used for range search.
Example:
As you can see, the value in the index changes much more than the value in the table itself, and therefore in the b-tree structure, they will fall into different blocks.
An inverted index is a full-text index that stores for each key token a sorted list of addresses of table entries that contain the given key.
In simplified form, it will look like this:
Partial index is an index built on the part of the table that satisfies a specific condition of the index itself. This index was created to reduce the size of the index.
The very flexible type of index is a functional index, that is, an index whose keys store the result of user-defined functions. Functional indexes are often built for fields whose values are pre-processed before comparison in a SQL command. For example, when comparing string data with case-insensitive characters, the UPPER function is often used. Creating a functional index with the UPPER function improves the efficiency of such comparisons.
In addition, a functional index can help to implement any other missing index type of this DBMS (except, perhaps, a bit index, for example, Hash for Oracle)
It is worth mentioning that in PostgreSQL GiST allows you to create an index based on R-Tree for any of your own data types. For this you need to implement all 7 functions of the R-Tree mechanism.
Additionally, you can read here:
Oracle Spatial User Guide and Reference
Spatial data in MS SQL
MS SQL: Spatial Indexing Overview
Hilbert r-tree
PostgreSQL spatial types
PostgreSQL Spatial Functions
Indexing spatial data in Microsoft SQL Server 2000 DBMS
Papadias D., Theodoridis T. Spatial Relations, Minimum Bounding Rectangles and Spatial Data Structures // Technical Report KDB-SLAB-TR-94-04,
Faloutsos C., Kamel I. Hilbert R-Tree: An Improved R-Tree Using Fractals // Department of CS, University of Maryland, Technical Research Report TR-93-19,
Wikipedia: Hilbert R-tree
External Memory Search Methods
Arthur Fuller. Intelligent database design using hash keys
Ps. Maybe I forgot to mention something, write on a personal or in a comment - I will add.
B-tree
The B-Tree index family is the most commonly used type of index, organized as a balanced tree, of ordered keys. They are supported by almost all DBMS, both relational and non-relational, and for almost all types of data.
Since most probably know them well (or can read about them, for example, here ), the only thing that should perhaps be noted here is that this type of index is optimal for a set with a good distribution of values and high power (cardinality -number of unique values).
')
Spatial indices
Currently, all DBMS data has spatial data types and functions for working with them, for Oracle it is a set of types and functions in the MDSYS schema, for PostgreSQL it is point, line, lseg, polygon, box, path, polygon, circle, in MySQL - geometry, point, linestring, polygon, multipoint, multilinestring, multipolygon, geometrycollection, MS SQL - Point, MultiPoint, LineString, MultiLineString, Polygon, MultiPolygon, GeometryCollection.
In the scheme of work of spatial queries, usually there are two stages or two stages of filtering. DBMS with weak spatial support work out only the first stage (coarse filtering, MySQL). As a rule, an approximate, approximate representation of objects is used at this stage. The most common type of approximation is the Minimum Bounding Rectangle (MBR) [100].
For spatial data types, there are special indexing methods based on R-trees (R-Tree index) and grids (Grid-based Spatial index).
Spatial grid
Spatial grid (spatial grid) index is a tree-like structure similar to a B-tree, but is used to provide access to spatial (Spatial) data, that is, to index multi-dimensional information, such as geographic data with two-dimensional coordinates (latitude and longitude). ). In this structure, the nodes of the tree are the cells of space. For example, for a two-dimensional space: first, the entire parent area will be divided into a grid of strictly defined resolution, then each grid cell in which the number of objects exceeds the maximum set of objects in the cell will be divided into the next level subgrid. This process will continue until the maximum nesting is reached (if set), or until everything is divided up to cells that do not exceed the maximum objects.
In the case of three-dimensional or multidimensional space, these will be rectangular parallelepipeds (cuboids) or parallelotopes.
Quadtree
Quadtree is a subspecies of the Grid-based Spatial index, in which there are always 4 descendants in the parent cell and the grid resolution varies depending on the nature or complexity of the data.
R-tree
R-Tree (Regions Tree) is also a tree-like data structure similar to the Spatial Grid, proposed in 1984 by Antonin Guttman. This data structure also divides the space into many hierarchically nested cells, but which, unlike the Spatial Grid, do not have to completely cover the parent cell and can intersect.
Various algorithms can be applied to splitting overflowed vertices, which causes the division of R-trees into subtypes: with quadratic and linear complexity (Guttman, of course, described with exponential complexity — Exhaustive Search, but naturally he is not used anywhere).
The quadratic subtype is divided into two rectangles with a minimum area covering all objects. Linear - in the division by maximum distance.
HASH
Hash indices were proposed by Arthur Fuller, and they do not preserve the values themselves, but their hashes, thereby reducing the size (and, accordingly, their processing speed) of indices from large fields. Thus, when querying using HASH indexes, the hash from the desired value will not be compared with the field hashes, but with the hashes of the fields.
Due to the non-linearity of hash functions, this index cannot be sorted by value, which leads to the impossibility of using more / less and “is null” in comparisons. In addition, since hashes are not unique, collision resolution methods are used for matching hashes.
Bitmap
Bitmap index - the bit index method consists in creating separate bitmaps (sequence 0 and 1) for each possible value of the column, where each bit corresponds to a row with an indexed value, and its value equal to 1 means that the entry corresponding to the bit position contains the indexed value for this column or property.
| Empid | Floor |
|---|---|
| one | Male |
| 2 | Female |
| 3 | Female |
| four | Male |
| five | Female |
Bit cards
| Value | Start | the end | Bit mask |
|---|---|---|---|
| Male | Address of the first line | Last line address | 10010 |
| Female | Address of the first line | Last line address | 01101 |
The main advantage of bit indices is that on large sets with low power and good clustering by their values, the index will be less than B * -tree. (Read more here or here )
Reverse index
Reverse index is also a B-tree index but with a reversed key, used mainly for monotonously increasing values (for example, an auto-incrementing identifier) in OLTP systems in order to remove competition for the last leaf block of the index, since due to the reversal of the value, two adjacent index entries fall into different index blocks. It cannot be used for range search.
Example:
| Field in the table (bin) | Reverse index key (bin) |
|---|---|
| 00000001 | 10,000,000 |
| ... | ... |
| 00001001 | 10010000 |
| 00001010 | 01010000 |
| 00001011 | 11010000 |
Inverted index
An inverted index is a full-text index that stores for each key token a sorted list of addresses of table entries that contain the given key.
| one | Mom washed the frame |
| 2 | Dad washed the frame |
| 3 | Dad was washing a car |
| four | Mom polished car |
In simplified form, it will look like this:
| Mama | 1.4 |
| Soap | one |
| Rama | 1.2 |
| Dad | 2.3 |
| Polished | four |
| Car | 3.4 |
Partial index
Partial index is an index built on the part of the table that satisfies a specific condition of the index itself. This index was created to reduce the size of the index.
Function-based index
The very flexible type of index is a functional index, that is, an index whose keys store the result of user-defined functions. Functional indexes are often built for fields whose values are pre-processed before comparison in a SQL command. For example, when comparing string data with case-insensitive characters, the UPPER function is often used. Creating a functional index with the UPPER function improves the efficiency of such comparisons.
In addition, a functional index can help to implement any other missing index type of this DBMS (except, perhaps, a bit index, for example, Hash for Oracle)
Summary Table of Index Types
| Mysql | PostgreSQL | MS SQL | Oracle | |
| B-Tree index | there is | there is | there is | there is |
| Spatial indexes supported | R-Tree with quadratic splitting | Rtree_GiST (linear split is used) | 4-level Grid-based spatial index (separate for geographic and geodetic data) | R-Tree with quadratic partitioning; Quadtree |
| Hash index | Only in tables of type Memory | there is | Not | Not |
| Bitmap index | Not | there is | Not | there is |
| Reverse index | Not | Not | Not | there is |
| Inverted index | there is | there is | there is | there is |
| Partial index | Not | there is | there is | Not |
| Function based index | Not | there is | there is | there is |
It is worth mentioning that in PostgreSQL GiST allows you to create an index based on R-Tree for any of your own data types. For this you need to implement all 7 functions of the R-Tree mechanism.
Additionally, you can read here:
Oracle Spatial User Guide and Reference
Spatial data in MS SQL
MS SQL: Spatial Indexing Overview
Hilbert r-tree
PostgreSQL spatial types
PostgreSQL Spatial Functions
Indexing spatial data in Microsoft SQL Server 2000 DBMS
Papadias D., Theodoridis T. Spatial Relations, Minimum Bounding Rectangles and Spatial Data Structures // Technical Report KDB-SLAB-TR-94-04,
Faloutsos C., Kamel I. Hilbert R-Tree: An Improved R-Tree Using Fractals // Department of CS, University of Maryland, Technical Research Report TR-93-19,
Wikipedia: Hilbert R-tree
External Memory Search Methods
Arthur Fuller. Intelligent database design using hash keys
Ps. Maybe I forgot to mention something, write on a personal or in a comment - I will add.
Source: https://habr.com/ru/post/102785/
All Articles