D'Artagnan and the Internet, or work on the problem of broken links

Gentlemen, it’s enough to consider links only in the context of their quantity, purchase / sale, and count the PR of the site where they are located. It's time to take care not about robots, but about people. Work with the Internet is becoming unbearable. The farms of auto-generated sites with govnoteksta bloom and multiply, forgive me ladies. Because of them, it is impossible to find even technical materials, not to mention ordinary ones. But I would not worry about the search for technical materials, if they were correct links. Links die like flies and, reading a post a year ago in a forum or blog, there is almost no hope of clicking on the links indicated.
I consider non-working links to be a very big problem of the modern Internet, although they somehow don’t talk about it or think about it. I think it's time to do at least something. We are already doing something about it and tell you. Hopefully, the example of someone will inspire, and he also wants to take care of their users.
')
There are so many broken links on the Internet that it’s not even possible to choose something as an example. Everyone came across that after reading interesting information about something, he confidently clicked on the link and got to nowhere. Moreover, the ultimate goal is usually not a dead site, but quite alive. Moreover, it is so lively that it constantly rules without concern for redirecting users coming from external resources. However, they often do not care about transitions from internal resources. A good example of an article in MSDN.
Someone will argue that the fact that the material has moved somewhere is no big deal. It can always be easily found on Google. Firstly, even if you can, it spends a huge amount of time. And this is a big problem. A single, but useful resource, moved at the whim of a site administrator, takes time from thousands, and in some cases, millions of people. Each of them will be forced to search for the necessary material and follow the links.
In other cases, it is extremely difficult to find the material or the one who needs it cannot do it. I’ll give two examples when “go to Google” does not help.
First example. In order to release a plug-in for Microsoft Visual Studio, it is necessary for each version to receive a special key (PLK) on the Microsoft website. For several years, this key was issued on the page msdn.microsoft.com/en-us/vsx/cc655795.aspx (link does not work). A couple of months ago, someone decided that calling the “vsx” section was ideologically incorrect, and it was renamed “vstudio”, respectively, the link became new http://msdn.microsoft.com/en-us/vstudio/cc655795.aspx . But EVERYWHERE, including Microsoft sites, links were old, not new. Google search also produced only the old link, since the new one did not appear anywhere. They helped in the Microsoft forum, where they clearly indicated a new page. The question is - did someone feel better by changing the link? How many people around the world were forced to look for an answer to this question? If you so want to change the link, was it really difficult to redirect?
And here is another, more emotional example. There is such a book “C # for schoolchildren”, released with the support of Microsoft and focused on children of 12-16 years old.

I am personally not sure that at this age it is rational to study C #, but the book as a whole makes a very pleasant impression. For extremely funny explaining pictures there is very, very much.
So imagine how much effort people put in to create such a book. Someone invented a Microsoft advertising initiative to acquaint children with C # at school, a man wrote a book, then it was translated, the artist redrawn the drawings so that the text was in Russian and, probably, in other languages. A lot of money and time was spent. And what is the result? And sure that no!
I very much doubt that the child will move on "Part 1. First acquaintance", because there he is explained about the need to download and install Microsoft Visual C # 2008 Express Edition. I do not doubt the abilities of the student. Starcraft 2 they, without third-party help, deflate and install, and in different iPhones they understand me better. Everything is more banal. Just there it is proposed to download from an address that no longer exists:

The result of the transition:
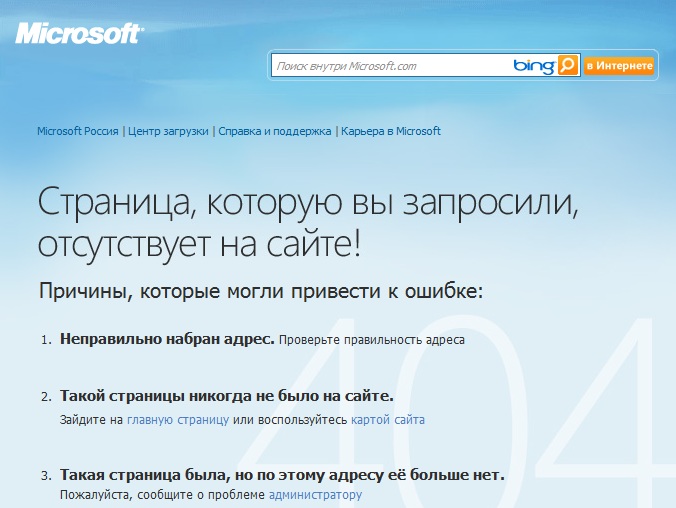
And one wonders why it was to deal with the creation of this book, if everything is broken about mindless transfer of data on the site from place to place? I very much doubt that a thirteen-year-old schoolboy will go to Google to look for the Microsoft Visual C # 2008 Express Edition miracle beast for download. With a 90% probability on this chapter with the study of C #, everything will be over.
Yes, it may seem that I criticize Microsoft. No, on other sites it is not better, just such examples turned out.
What I draw from all this conclusions?
It is very easy to spoil all your material, a blog post, a service, a book or any other project due to the fact that someone else (or you yourself) will take and change the address of the resource to which you refer. After this, the value of your creation, if it doesn’t become zero, then at least it will be much lower, since your readers / users will have to spend nerves and time to search for the right link themselves.
How do we solve this problem
We write technical articles and often refer to various documentation, tools, and entries in third-party blogs. As a result, we also often encounter the problem of moving materials and articles to third-party sites. Especially for some reason, such sites of large companies as Microsoft, Intel or AMD sin. They move entire sections and as a result, for example, seek help in Microsoft / Intel employee articles that have turned a very ignoble matter for at least a year. Which link do not click - you get to nowhere. I think that many programmers will understand my experiences.
I am sure many do not care, the transition does not work somewhere, well, okay. Actually it is, since there are so many dead links on the Internet. However, we write articles for people, not for search engines. And I declare it with pride. Although millions have not earned so far, but at least for a moment I want to feel like d'Artagnan.
So, it is important for us that the articles have correct links not only to the materials on our own site, but also to external sites. Consequently, we need to correct those links that are starting to lead nowhere. The task is complicated by the fact that we publish our articles on many other sites. And it is natural to edit the references in them there are no forces, and sometimes a technical possibility.
The natural solution is to create a redirect system. I will tell you how it all works, maybe someone wants to do something similar. I even really want someone to be interested, so tired of the road to nowhere!
The system consists of a database that stores a short link - a link to an external resource. The user interface for adding links is quite simple and is shown in the figure below.
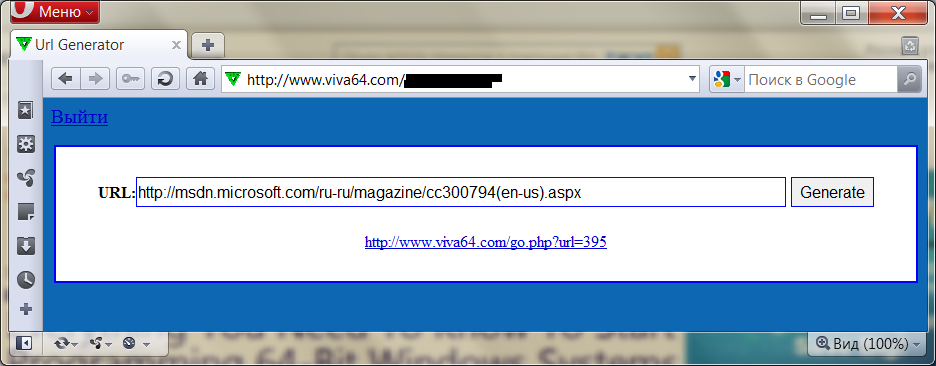
Just enter the link on the external resource and get a short link to insert into articles, blogs and so on. If the address of the external resource is already in the database, then the short link already created earlier is returned:
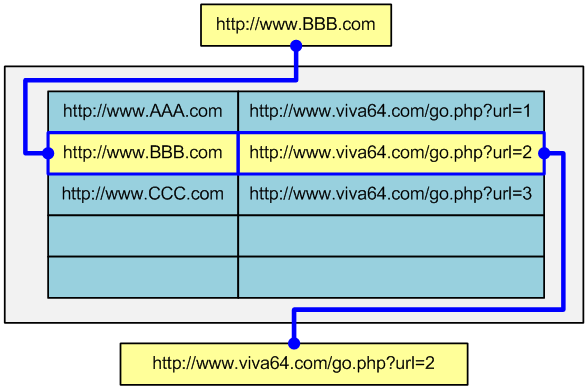
If there is no such link in the database, a new pair is created and a new short link is generated:
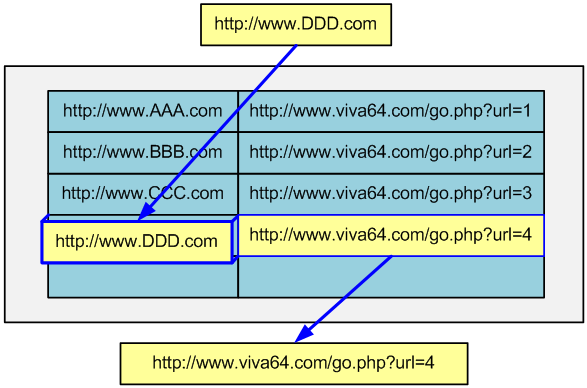
Technically, a record is stored in a database in the links table and is a set of the following fields:
- id - primary key
- num is the reference number; it is this number that determines which link the qwerty.php script retrieves from the database
- link - the link text itself
- link_category_id is the number of the category in which the link is located; this field is not essential for the script to work, but for the user's convenience, the categories of links are entered
When you click the “Generate” button, a request is sent to the viva64.com website containing the address of the link you want to add. The script processing request looks like this:
$ sql = "select * from links where link = '". $ add_url. "'";
$ link = mysql_query ($ sql);
if (mysql_num_rows ($ link)) {
$ row = mysql_fetch_array ($ link, MYSQL_ASSOC);
$ new_url = "http://www.viva64.com/qwerty.php?url=".$row['num '];
}
else {
$ sql = "select * from links order by num desc";
$ link = mysql_query ($ sql);
$ row = mysql_fetch_array ($ link, MYSQL_ASSOC);
$ last_num = $ row ['num'] + 1;
$ sql = "insert into links (num, link) values
(". $ last_num.", '". $ add_url."') ";
$ link = mysql_query ($ sql);
$ new_url = "http://www.viva64.com/qwerty.php?url=".$last_num;
} The script gets this address of the $ add_url variable and checks if the database has the following address:
$ sql = "select * from links where link = '". $ add_url. "'"; $ link = mysql_query ($ sql);
If it does, then the $ new_url variable will simply contain a link to call the redirect script with the address identifier obtained from the database:
if (mysql_num_rows ($ link)) {
$ row = mysql_fetch_array ($ link, MYSQL_ASSOC);
$ new_url = "http://www.viva64.com/qwerty.php?url=".$row['num '];
} If the address is not found, the maximum unique address identifier from those contained in the links table will be calculated and the new record will be added to the database with an incremented maximum identifier, after which the value of the new link to call the redirect script will be written to the $ new_url variable:
else {
$ sql = "select * from links order by num desc";
$ link = mysql_query ($ sql);
$ row = mysql_fetch_array ($ link, MYSQL_ASSOC);
$ last_num = $ row ['num'] + 1;
$ sql = "insert into links (num, link) values
(". $ last_num.", '". $ add_url."') ";
$ link = mysql_query ($ sql);
$ new_url = "http://www.viva64.com/qwerty.php?url=".$last_num;
} After that, the user receives a redirect link, regardless of whether a new address was added to the database or just one of the existing ones was obtained.
Redirection mechanism
The redirect script on viva64.com is not complicated. In essence, all he does is take the reference number as a parameter, then get the link with that number from the database and redirect it by reference. In the code, it looks like:
$ s = substr ($ HTTP_GET_VARS ['url'], 0, 15);
$ u = "http://www.viva64.com/";
$ isConnect = mysql_connect ($ sqlserver, $ sqluser, $ sqlpassword);
if ($ isConnect) {
$ isSelectDatabase = mysql_select_db ($ database);
if ($ isSelectDatabase) {
$ currentLink = $ s;
$ sql = "SELECT * FROM links WHERE num = '". $ currentLink. "'";
$ link = mysql_query ($ sql);
if ($ link && mysql_num_rows ($ link)) {
$ row = mysql_fetch_array ($ link, MYSQL_ASSOC);
$ u = $ row ['link'];
}
}
}
print Header ('Location:'. $ u); Find and fix broken links
The task of finding broken links is solved by means of the Fast Link Checker program. The program bypasses all pages of the site and tries to go through all the links found. Then the results are filtered and, to predefined e-mail addresses, a letter is sent with a list of broken links. The launch of the program is automated; once a week, a link health check is performed.
After defining a broken link manually, a search for the material referred to is performed. Usually you can easily determine the new address at which material is available. On sites like Microsoft, Intel, AMD, they like to just transfer the material to another section.
If it is impossible to find this or almost identical resource, which is extremely rare, then the link is removed from the articles of the site. On external sites, the link in our article will point to nowhere, but nothing can be done here. Once some material / site has disappeared, it means that it has disappeared.
When a new link is defined, it is entered into the database and thus in all articles of the site the link is again working.
To change the link through the administrator interface, a request will be executed like
UPDATE 'links' SET 'link' = 'http://msdn.microsoft.com/en-us/isv/bb190527.aspx' WHERE 'links'.' numn = 341 LIMIT 1;
I didn’t write at all about the work of the system in detail; I, to be honest, the user is a system, not a developer. But if there is interest from readers, then my colleague Anton Dubrovin will describe everything in more detail and answer questions.
Intel Initiative
I myself am not an employee of Intel, but I know that many of the company's employees read this blog. That is why I am writing here because I want to propose an initiative. I know that Intel constantly conducts various programs and summer schools, where students are trained, performing various interesting tasks. If someone from Habrahabr’s readers doesn’t know, then here are some links on this topic: 1 , 2 , 3 , 4 .
I would like to suggest, as one of the tasks, to reflect on the implementation of the system, which will allow keeping the available links on the Intel website in adequate condition. Unfortunately, non-working links on the Intel site, perhaps no less than on the Microsoft site. You can start with a small part. For example, think about the support of the Russian part of the ISN (articles, forums, blogs). What I described in the article is still some handicraft that solves only one task and is very narrow. And the problem of invalid references requires more serious research and work.
Thanks in advance to those who want to improve the world a little too.
Source: https://habr.com/ru/post/101957/
All Articles