xz - LZMA compression power is already in your console
Many probably already know about the utility for compression / decompression xz . But even more do not know. Therefore, I wrote this introductory topic.
xz is a data compression format, along with gzip, bzip2 included in gnu-shnye applications.
It uses the LZMA algorithm , the same as in 7z, which means that you can compress many types of data, such as text, binary data that are not yet compressed compared to the standard ones mentioned above.
xz is used in the new rpm 4.7.2 for compressing .cpio archives in rpm packages (used with Fedora 12).
ArchLinux generally uses .tar.xz as a package.
The GNU tar option has the -J --lzma options that play the same role as -z for gzip, -j for bzip2
Pros:
 High compression ratio
High compression ratio
Minuses:
high resource consumption:
 cpu time (and proper compression time)
cpu time (and proper compression time)
memory (configurable, but still more than gzip, bzip2).
In particular, xz with --best aka -9 consumes up to 700mb! with compression and 90mb during decompression
')
Features:
 Consumption of a large amount of memory is limited to a preliminary calculation of available resources.
Consumption of a large amount of memory is limited to a preliminary calculation of available resources.
GNU tar integration
work with threads
optional: progressbar via --verbose
I do not want to clutter up the introductory topic with graphs and other things, but one cannot do without it:
I made a banal gzip, bzip2, xz race for the degree of compression, time consumption. WinRar will also take part as a guest (albeit intoxicated, under wine, but it certainly showed excellent results)
We get 4 squares:
Lower left - slow and weak: gzip and winrar fastest.
Upper left: winning compression / time ratio: bzip2, xz shows itself at the 1st and 2nd compression levels a little better, and
Upper right: real press mechanism: dollars but very tight xz
In the lower right: no one, and who needs a long-working and weakly squeezing archiver?
But in general, the coordinate grid is not well chosen: how do we estimate time? categories! for example, quickly - 10–20 seconds, medium from half a minute to a minute, more than 2 minutes is a long time.
so the logarithmic scale is clearer here:

And if you evaluate them as a stream compression, on my Core2Duo E6750 @ 2.66GHz,
it turned out such a schedule:
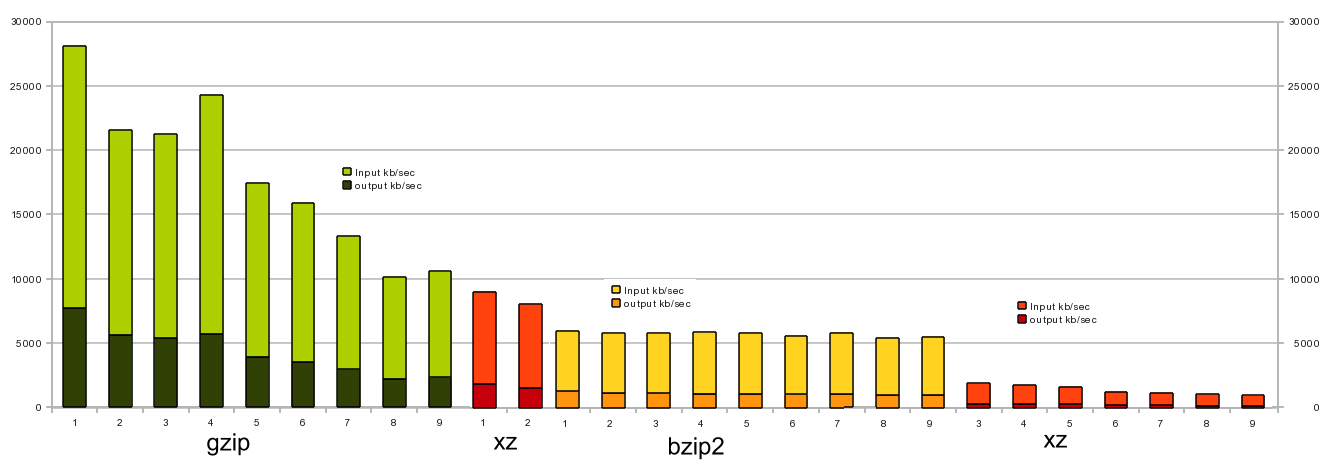
those. using gzip -1 or gzip -4 as a szhimalki conveyor, you can drive up to 25MB / s of uncompressed data on a 100Mbit network. (I checked it several times - gzip -4 for some reason gives more profit than -3 or -5)
xz can only be used on channels <8mbit,
xz - in view of resource consumption, occupies a niche of compressorarchivers , where compression ratio can play a big role, and there is enough computing resources and time resources. those. various backups / archives, distributions (rpm, tar.xz in archlinux). Or the data is very easily compressed: logs, tables with text-digital data csv, tsv, which are not supposed to be changed.
PS It would not have been happy for xz, in the rationality of the effort spent WinRar Wins.
xz is a data compression format, along with gzip, bzip2 included in gnu-shnye applications.
It uses the LZMA algorithm , the same as in 7z, which means that you can compress many types of data, such as text, binary data that are not yet compressed compared to the standard ones mentioned above.
xz is used in the new rpm 4.7.2 for compressing .cpio archives in rpm packages (used with Fedora 12).
ArchLinux generally uses .tar.xz as a package.
The GNU tar option has the -J --lzma options that play the same role as -z for gzip, -j for bzip2
Pros:
High compression ratioMinuses:
high resource consumption:
cpu time (and proper compression time) memory (configurable, but still more than gzip, bzip2).In particular, xz with --best aka -9 consumes up to 700mb! with compression and 90mb during decompression
')
Features:
Consumption of a large amount of memory is limited to a preliminary calculation of available resources. GNU tar integration work with threads optional: progressbar via --verboseI do not want to clutter up the introductory topic with graphs and other things, but one cannot do without it:
I made a banal gzip, bzip2, xz race for the degree of compression, time consumption. WinRar will also take part as a guest (albeit intoxicated, under wine, but it certainly showed excellent results)
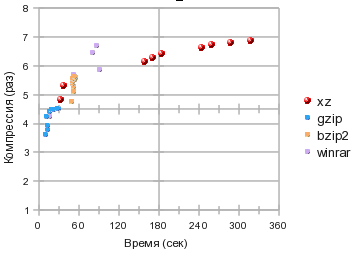 this picture has excellent clickability | As the test data, I took the unrolled branch of the 2.6.27 fedor kernel, collected it in tar - with a volume of 292mb, and took measurements. Vertical compression level (times), horizontally - the amount of time spent. xz stung this file from 4.8 to 6.9 times. gzip 3.6 - 4.5 bzip2 4.5 - 5.6 winrar 4,5 - 6,7 |
We get 4 squares:
Lower left - slow and weak: gzip and winrar fastest.
Upper left: winning compression / time ratio: bzip2, xz shows itself at the 1st and 2nd compression levels a little better, and
Upper right: real press mechanism: dollars but very tight xz
In the lower right: no one, and who needs a long-working and weakly squeezing archiver?
But in general, the coordinate grid is not well chosen: how do we estimate time? categories! for example, quickly - 10–20 seconds, medium from half a minute to a minute, more than 2 minutes is a long time.
so the logarithmic scale is clearer here:
And if you evaluate them as a stream compression, on my Core2Duo E6750 @ 2.66GHz,
it turned out such a schedule:
those. using gzip -1 or gzip -4 as a szhimalki conveyor, you can drive up to 25MB / s of uncompressed data on a 100Mbit network. (I checked it several times - gzip -4 for some reason gives more profit than -3 or -5)
cat /some/data | gzip -1c | ssh user@somehost -c "gzip -dc > /some/data"xz can only be used on channels <8mbit,
The obvious conclusion (With the assistance of KO)
xz - in view of resource consumption, occupies a niche of compressor
PS It would not have been happy for xz, in the rationality of the effort spent WinRar Wins.
Source: https://habr.com/ru/post/101953/
All Articles