Digit recognition with simplest statistics and topology analysis
The case was in the third year, the subject of IIS appeared (intellectual information systems). Since I have been interested in image recognition for a long time, I managed to get the topic of “handwriting recognition”. I decided not to bother with neural networks and come up with something of my own, simple, but quite effective.
Perhaps the simplest of the character recognition algorithms is a pixel-by-pixel comparison of the pattern with the reference images, the difference is calculated, the sample for which it is the smallest is considered the correct answer. When comparing, different tricks can be used, for example, potential functions and Hamming distance can be used for clustering. Disadvantages of this method: the need to prepare and store a large number of samples (the more the better), poor resistance to distortion, a strong dependence on the font used for reference images.
I also had the idea to directly use the statistics of the distribution of filled pixels. It was decided to use a field of 20x30 pixels, since the more points there are, the smaller the statistical error.
1. The borders of the pattern are determined, a rectangular area is cut out (to cut off the empty pixels and reduce the dimension of the working matrix).
2. The area is divided crosswise into 4 parts.
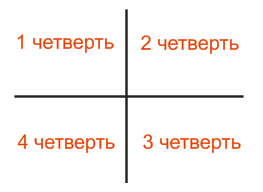
For each quarter, the number of shaded pixels that have fallen into it is calculated, the fraction is calculated relative to the entire pattern. Something like this:

3. For higher recognition accuracy, the topology is investigated. Using the recursive function, the number of closed areas is calculated. If there are two of them, this is exactly the figure of 8. If one is 0, 6 or 9 (a refinement will be made here by quarters). If there are no such areas - this is one of the other numbers.

4. Next comes the tablet, in which the approximate distributions for each figure are pre-recorded, which I calculated by conducting a small study:


For each digit (line) in the table, the total deviation is calculated, where it is minimally assumed that this figure is shown in the figure (of course, the topology calculated in step 3 is taken into account, for example, if only one closed area is detected, only 0, 6 and 9).
Here, in fact, what the program looked like in the end:
')
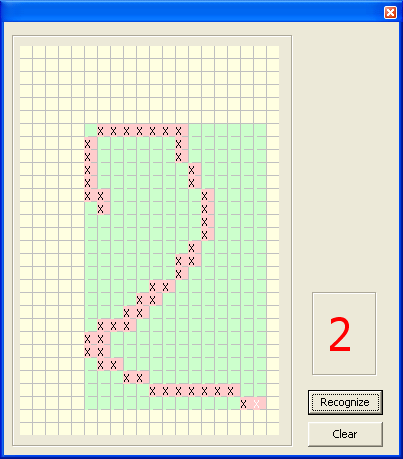

The method may seem too stupid, and yet it works! If it is not worthwhile to trick the algorithm , the percentage of correct recognitions is very high. Unlike the comparison methods with the standard, it is more resistant to vertical or horizontal stretching, changing the thickness of the pen and does not require transformation to the size of the reference images. Although when trying to take a job as a teacher, I was destroyed by his creepy handwriting and the desire to split the algorithm, I believe that for the first time the problem was solved (as hinted at by the five in the record book :)
In the future, the lab was remade under fuzzy logic, then under neural networks + GA, but all this is quite difficult and not so elegant.
You can try my solution yourself.
Perhaps the simplest of the character recognition algorithms is a pixel-by-pixel comparison of the pattern with the reference images, the difference is calculated, the sample for which it is the smallest is considered the correct answer. When comparing, different tricks can be used, for example, potential functions and Hamming distance can be used for clustering. Disadvantages of this method: the need to prepare and store a large number of samples (the more the better), poor resistance to distortion, a strong dependence on the font used for reference images.
I also had the idea to directly use the statistics of the distribution of filled pixels. It was decided to use a field of 20x30 pixels, since the more points there are, the smaller the statistical error.
The essence of the method
1. The borders of the pattern are determined, a rectangular area is cut out (to cut off the empty pixels and reduce the dimension of the working matrix).
2. The area is divided crosswise into 4 parts.
For each quarter, the number of shaded pixels that have fallen into it is calculated, the fraction is calculated relative to the entire pattern. Something like this:
3. For higher recognition accuracy, the topology is investigated. Using the recursive function, the number of closed areas is calculated. If there are two of them, this is exactly the figure of 8. If one is 0, 6 or 9 (a refinement will be made here by quarters). If there are no such areas - this is one of the other numbers.
4. Next comes the tablet, in which the approximate distributions for each figure are pre-recorded, which I calculated by conducting a small study:
For each digit (line) in the table, the total deviation is calculated, where it is minimally assumed that this figure is shown in the figure (of course, the topology calculated in step 3 is taken into account, for example, if only one closed area is detected, only 0, 6 and 9).
Software implementation
Here, in fact, what the program looked like in the end:
')
findings
The method may seem too stupid, and yet it works! If it is not worthwhile to trick the algorithm , the percentage of correct recognitions is very high. Unlike the comparison methods with the standard, it is more resistant to vertical or horizontal stretching, changing the thickness of the pen and does not require transformation to the size of the reference images. Although when trying to take a job as a teacher, I was destroyed by his creepy handwriting and the desire to split the algorithm, I believe that for the first time the problem was solved (as hinted at by the five in the record book :)
In the future, the lab was remade under fuzzy logic, then under neural networks + GA, but all this is quite difficult and not so elegant.
You can try my solution yourself.
Source: https://habr.com/ru/post/101446/
All Articles