CUBRID
 Recently, in the field of databases, attention has been focused on the rapidly developing NoSQL solutions. There is a deceptive impression that in the relational DBMS sector there is a lull: the main products have long been known, all niches are occupied. It would seem that a new player is not so easy to get here. Only if we are not talking about a project with a fifteen-year history, not a developed open source object-relational DBMS optimized for use in web applications, not a system that has stored procedures support, partitioning, high availability options, replication and distributed transactions . The name of this “dark horse” is CUBRID. And, judging by the statements of the creators, it claims the laurels of MySQL.
Recently, in the field of databases, attention has been focused on the rapidly developing NoSQL solutions. There is a deceptive impression that in the relational DBMS sector there is a lull: the main products have long been known, all niches are occupied. It would seem that a new player is not so easy to get here. Only if we are not talking about a project with a fifteen-year history, not a developed open source object-relational DBMS optimized for use in web applications, not a system that has stored procedures support, partitioning, high availability options, replication and distributed transactions . The name of this “dark horse” is CUBRID. And, judging by the statements of the creators, it claims the laurels of MySQL.The horse was “hidden” in South Korea, where it gained popularity and began to be used in projects of state structures and such giants as NHN corporations. At the end of 2008, source codes were opened, but the international face found the project (with the launch of the official site and publication on sourceforge) only at the end of 2009.
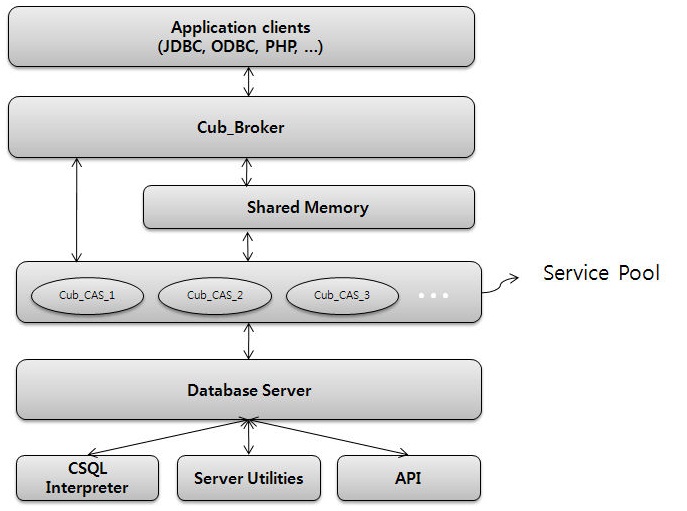
With MySQL, this DBMS is related only to the scope, they do not have a common code base and differ in the approaches used, starting with ideas and ending with the API. High performance for web applications is embedded in the three-tier CUBRID architecture.
- The server subsystem is presented as a set of processes, each of which solves a narrow set of tasks:
- allocation of free space
- logging
- lock management
- transaction management
- processing objects and requests
- The client subsystem includes APIs for C, PHP, Python and Ruby, as well as support for JDBC, ODBC and OLEDB and takes over
- parsing and query optimization
- caching objects and locks
- management of objects, transactions and triggers
- Intermediate subsystem (Broker) implements
- queue of tasks
- connection pool
- monitoring
- logging
')
The CUBRID architecture is focused on scaling broker links that take on the task of optimizing queries and pooling connections, unloading the database server, and also increase system security by isolating query processing. In addition, on June 7, 2010, a project on clustering the database itself started (by the end of the year, a stable version is planned to be released).
Also, this DBMS has a number of unique features that are relevant specifically for web applications. I will give an example. Imagine that your database is used to store a large number of articles. There are users who view them. Consider the generally accepted sequence of actions when requesting an article for viewing:
SELECT header, text FROM articles WHERE article_id = :requested_id;
UPDATE articles SET read_count = read_count + 1 WHERE article_id = :requested_id;Now remember what happens under high load. True, locking due to updates will significantly reduce performance. In CUBRID, this problem is solved as follows:
SELECT header, text, INCR(read_count) FROM articles WHERE article_id = :requested_id;A lock is not created. Another original extension is the DO directive, which instructs the database not to return any query results, be it a function output, a sample, or an error message. As a confirmation of the effectiveness of these solutions, the site provides performance testing results . Despite the fact that the names of competitors are hidden, you can easily guess who is who.
The DBMS is written in C and C ++, the administration interface is in Java, and Linux and Windows are supported. Already implemented support for SQL-92, JDBC, ODBC and OLEDB.
CUBRID uses an object-relational approach to data storage. Therefore, there are no columns in it - there are attributes, there are no tables - there are classes, there are no rows - there are instances of classes, there are no data types - there are domains, there are no procedures - there are methods. This allows instead of generating DDL for the existing class structure, just take the compiled jar-file, load it into the database:
loadjava db_name MyClass.classcsql> create function Sample() return string as language java name 'MyClass.Sample() return java.lang.String';
csql> ;xrunAnd so, when using the object approach, attributes change:
CUBRIDResultSet rs = (CUBRIDResultSet) stmt.executeQuery( "select object_name from object_name" );
rs.next();
CUBRIDOID oid = rs.getOID(1);
oid.addToSet( "set_name" , new Integer(10));
oid.addToSequence( "list_name" , 1, new Integer(30));
oid.putIntoSequence( "list_name" , 99, new Integer(99));
oid.removeFromSet( "set_name" , new Integer(1));
oid.removeFromSequence( "list_name" , 1);
con.commit();
rs.close();For Java developers, there is support for Eclipse through QuantumDB and a driver for Hibernate, although, after the examples above, it is hardly useful.
In addition to all the differences listed above, CUBRID has quite good administration tools, good implementation of high availability (failover, DBMS and OS upgrades without downtime), backup (hot backups, compression). Migration tools are also ready: Scriptella and Apache DdlUtils. MediaWiki, phpBB, Wordpress and several smaller projects can already be used as storage for CUBRID.
The disadvantages include: so far, a small community of developers and users, lack of support for Solaris, Mac OS X and FreeBSD, as well as some features of the SQL dialect, although the documentation and video tutorials remove almost all the questions.
It is surprising that there is practically no information on this topic in RuNet, except for a couple of mentions in the Ruby community and translation of an English-language article in Wikipedia, where it is mistaken ( proof ) that the database has been developed since 2006. I think that this review will give readers some food for thought.
Source: https://habr.com/ru/post/101354/
All Articles