CouchDB today

What is CouchDB for you? Probably anyone who is even slightly interested in the popular NoSQL theme today knows the general details very well: it’s such a pretty toy with map / reduce queries that are written in JavaScript, which you can work with, driving JSON using the HTTP protocol, and also, heard that it is fault-tolerant, tobish does not break at all. This is usually not the case, as a result, CouchDB is sent to a delicious pile with all sorts of MongoDB, Cassandra, Hadoop, etc.
About this opinion, I adhered to until recently, until there was an urgent need to rethink the architecture of the current project (resting its forehead on its relational database) and transfer to a document database that could map / reduce. After looking more closely at CouchDB, I realized that it is unique in its class, it should not be put on a par with the products mentioned. The ideas that are inherent in CouchDB are so conceptual that they are able to radically change the concept of web application development.
')
That I so impressed, I will try to tell under a cat.
Just want to say that if you already have a certain experience of using CouchDB, then it’s likely that you yourself already have a “mustache” and this article is not for you. But as for the rest, after reading it, there will be a desire and an opportunity to lie down on such a red sofa and relax, as the developers of Couch recommend.
It should be said that the hype around CouchDB until recently has subsided somewhat, on HabrE, references to this database rarely skip, although over the last month, Twitter literally exploded with the news about the release of CouchDB 1.0 and Cloudant's release from the closed Beta-testing phase (I will tell you A little more below. The search says that this event really was not covered in Habré, while the output of MongoDB 1.6 was marked with a separate post. This injustice must be corrected, because if you remember CouchDB as a raw alpha with slow inserts and furious memory and processor consumption, then forget it - this is all already in the distant past. Today it is a production-ready system with commercial support available and real-life examples of production use in companies like the BBC, for example.
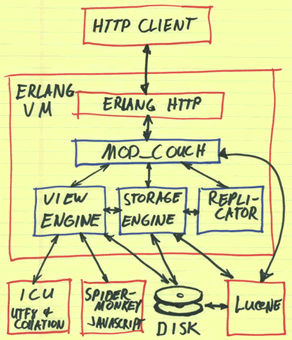
I will not describe in detail the main features that you can read about on the project site if you wish. I will try to talk about what was not obvious to me until I decided to look at this product closer, as a result of which I did not pay enough attention to this product, whereas I could save myself a lot of time and nerve cells.
map / reduce
It would seem that it is difficult to surprise someone with something. Many NoSQL databases use exactly this paradigm of access to data that does not have a strictly defined scheme. Plus, it is also alarming to use JavaScript to describe map / reduce-functions. The first impression is that it should be scary slowly, because at least
map() must be performed for each document in the database. Plus, the SpiderMonkey engine is far from a V8 in speed. What is the catch?The keen eye will see that just in CouchDB is used not a map / reduce of pure form, but the so-called. incremental map / reduce. The whole idea is that CouchDB does not calculate its views (the so-called views are the results of functions like
map() and reduce() ) each time. This is done only at the first access to the new view, after which the result is quietly indexed and the ID of the documents quietly fall into the B + tree according to the key we need with additional information in the nodes (as well as the results of intermediate reductions). Then everything is simple: when a new document gets into the database (or the old one changes), map() is called for it once, after which it is placed in the index tree. Those. there is no need to recalculate the index entirely, the tree is simply incrementally completed.When we need results, Kouch simply gives us what is already calculated in advance, there is no need to re-bypass the documents by executing
map() . In contrast to indexing several separate columns to speed up the search, as most databases do, we indexed all the query results in one go. Imagine MySQL, which just doesn’t need to "execute" a query - it can immediately get all its results from a single index.The only analogue that comes to mind is the materialized views from the “big” RDBMS like Oracle, but only much more lightweight. Do not forget that only the results index is stored and only the values you need - the redundancy is not that big compared to conventional databases with a bunch of indexes, because only the map / reduce results are indexed - the data you need in the context of this query, and not all columns. And the screws are now cheap relative to the potential that this method offers.
I need more power ©
The fact that
map() is essentially executed only once for each new / modified node is very interesting. This allows you to perform quite heavy operations on a new document; anyway, this is done once. And if it seems to you that with the built-in JavaScript runtime you will not accelerate too much, then another interesting feature of CouchDB pops up - in fact, it is not tied to any particular language, but uses abstraction in the form of a View server. Those. you simply connect the view server for your favorite programming language and write map() and reduce() for example in Python, using its rich standard library.By and large, when you add a new document directly from
map() , no one bothers you to geocode the address of your client being added to the database using an external service (Google Maps API for example) and calculate the geoindex for it with another external library. Or just take and index your document using Sphinx, getting another super-fast full-text index of your database (if not good integration with Apache Lucene). In general, the scope for creativity is limited only by fantasy.If you need more speed, then all of your view-functions can be rewritten in C, using the fact that the interface of the view-server is as simple as a spade, and the view in CouchDB is exactly the same document, or rather a design-document with a special ID. Therefore, it is not at all necessary for him to directly contain the function code — you can put in it, including any identifier that will be understandable to your view server. In general, it is noticeable that this ideological unity of data and instructions for their processing in the form of exactly the same data is akin to the Lisp ideology.
Let it be said that the map / reduce paradigm does not provide such power as SQL queries, but in practice you just need to learn to think of its categories. So for example, the fallacy that JOIN cannot be done without SQL, since joins don't scale and so on. All this is not without meaning, however, the statement is too general. Firstly, the document can contain not only key-value pairs, but also collections, other objects and everything else that can be described using JSON, and secondly, even more complex joins can be implemented, knowing the basic patterns - map / reduce implementation in CouchDB is very powerful and at the same time clear and logical.
Web as it is
Unlike most alternatives, CouchDB was developed primarily as a database for the needs of web applications. Hence the roots of such a non-trivial solution as access to the database through a REST interface. Yes, HTTP is pure, it has an overhead, but it is fully compensated by how elegant this solution is. Firstly, you do not need to look for a driver for your favorite programming language - any HTTP client will cope (all examples are most often curl directly from the command line). Moreover, such a client could be a web browser. You can write a web application just do not use any middleware on the server - you can work with the database using JavaScript via Ajax (for example, CouchApp is a jQuery framework from the creators of CouchDB).
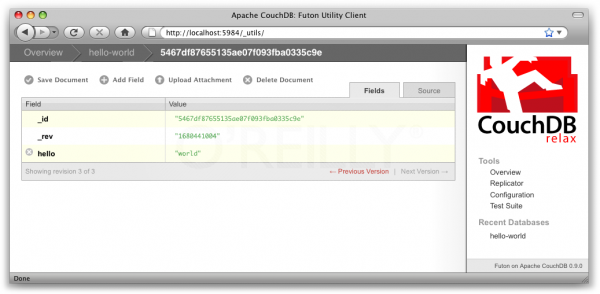
After the start, Kouch behaves like a normal HTTP server, you can access it using your browser and perform GET requests simply by using your browser address string, getting JSON as a result. Futon, the administrative interface of the CouchDB instance, will be immediately available. By the way, it is implemented entirely in JavaScript without server middleware, we expand and can do a lot of interesting things despite its simplicity.
It is hardly worth saying that the HTTP protocol is implemented correctly, caching is supported, and Kouch knows when to give 304. Similarly, a document may contain binary attachments (attachments - the equivalent of (B) LOB), which Kouch stores by native files and gives as static content . Design documents can also contain
show() and list() , which allow you to convert the returned results as you please, for example into HTML pages and give them directly to the browser. And if earlier you were of the opinion that it’s bad to store user avatars and pictures from your online store products directly in your [relational] database, then with CouchDB everything is different - sometimes even without a rigid scheme, the data may be more structured. and holistic.As you know, all ingenious is simple. In CouchDB, the mass of such simple things that were made with the calculation on the Web application, and not on the abstract data that needs to be somehow processed. In the end, everything looks so consistent that now it’s not even clear how this could be done differently.
Scaling
About CouchDB used to be said that it does not scale. Indeed, not so long ago it was true, but only half. Everything in order.
One of the key and most interesting features of CouchDB is its replication. The reader may wonder how replications can be interesting in principle, perceiving them as a kind of crutch. In Cauche, everything is wrong; its replications were designed initially when creating a database. First of all, they know how to master-to-master, which allows you to make all instances equally functional, and not to divide them into master / slave. The problem of such replication in "normal" databases are potential conflicts. Therefore, Kauch (possessing the MVCC property), in the event of a conflict, retains all conflicting versions and is able to resolve these conflicts according to configured rules (or handing this matter over to your application - how you choose to use it depends only on your imagination). By itself, replication comes down to jerking a URL from the CESTDB REST API (or by using Futon, you can simply enter the URL of another database and click a button), this is how difficult it is.
So here you eat in transport, write something there to all sorts of tweeters from your Nexus One (did I not mention that CouchDB is fully functional on Android phones, as well as Maemo / MeeGo?), And then you enter the tunnel - connect is lost. You can safely continue to use the application, which upon the return of the connection will be able to merge new messages and fill in what you have written with one API call, without inventing bicycles. For example, if you are using Ubuntu One, then you are already using CouchDB in exactly this way.

But we will not be distracted from the topic. Such replications are nice (especially in light of the CouchDB HTTP nature: you can put a regular balancer in front of the Cluster cluster), but this is not a “real” scaling. Replications and relational databases can scale (albeit not so elegantly), but what about sharding? After all, everyone wants to smear the data on the cluster and simply by adding a node to increase the amount of available disk space, maximum load, peak number of users, and so on, without losing speed. CouchDB can't do this out of the box. Until. But it is only a matter of time.
But Cloudant can. Cloudant is a new service that just a few days ago completed Beta testing and is now available to everyone. This is hosting your CouchDB database (on the cloud from Amazon), or even the entire application, given that CouchDB can serve not only the database, but also middleware. The guys took advantage of the potential in CouchDB and develop their fork (which soon has a chance to become part of the trunk), which is unlimitedly scaled by a sharding, in which you can add a new node at any time, it also provides redundancy - each document is stored in triplicate on different nodes in case one of the nodes falls off. Moreover, in addition to the full support of the standard API, Cloudant allows you to map / reduce the results of another map / reduce and has many more interesting features.
All code is open, so you can raise and use Cloudant on a private cloud. You can also register a free account (up to 250 megabytes of disk space without taking into account old revisions of documents) and try CouchDB live - all the basic features are available, incl. Futon.
Today
CouchDB in July has grown to version 1.0, and the developers emphasize its stability and readiness for production-use. Also, the release of Cloudant is a landmark for the entire CouchDB community. If you have not tried Couch yet, spend half an hour of your time - you can save a lot more time in the end, although this will of course depend on the specifics of your particular project. The product does exactly what it was created for, but no more. So do not expect a miracle, but I hope that after reading, someone will relax, as the developers recommend (especially if there is a red sofa).
Source: https://habr.com/ru/post/101251/
All Articles