Alternative implementation of the many-to-many relationship in Oracle
The benefits of nested tables, or, as they are also called, child tables (
However, I had the idea of implementing many-to-many interconnections (
Using the example, it is easier to show the proposed structure, and it is also a good way to check which method loads the system less.
Suppose there is a bus depot spherical in a vacuum. The bus fleet has several buses and several drivers. There are several drivers driving the same bus (several shifts). Features of this park are such that one driver can also ride on several buses, for example, depending on the day of the week.
')
We will create two very simple tables intended only to create relationships between them.
For creating, deleting and selecting relationships in the example, procedures will be used - for convenience of testing. In addition, it was interesting for me to test it with procedures, because from the point of view of programming it is more convenient than composing queries in the body of the program. It should be noted that there is no commit to one procedure (
At the creation of the first structure of the relationship is completed. The following relationship scheme was implemented: two tables and an additional table in which the list of relationships is stored.

Next comes the SQL code for the alternative. The second option was created on the exact same table structure, but in a different scheme. And the structure of interrelations looks like this: there are two tables, in one of them each record stores a list of interrelations.
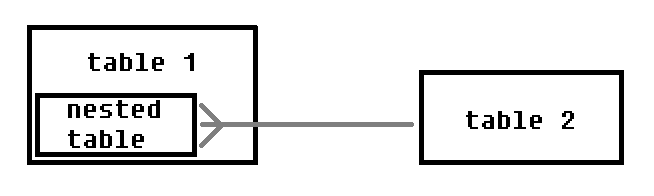
A table can be created immediately with a column of nested tables, but in this case the relationship is constructed from two tables already prepared, so another approach is used: one of the tables is changed.
To verify the correctness of the procedures, the same test values were used.
Testing was conducted several times for each option. First, the samples, procedures, and function were debugged on the above test data. Then procedures were created for each database (in fact, of course, charts), which filled the tables with data using a random number generator. In approximately the same way, a specified number of relationships were created.
Testing was conducted on data in the amount of n = 4, 1000, 100000. It is assumed that there are n records in each table, and also n relationships are created. Testing was carried out on 10 positions, the table below presents 6 of them, which have the most significant differences in time and display the most significant data.
During testing, a distinction was made between the first sample and the subsequent ones, as well as between the sample using a query or a procedure that places data on the cursor. The main measurements were made to create relationships and different variants of samples. Deleting relationships is not included in this list, since a random number generator is used and it is likely that almost all attempts to delete relationships will turn into inaction.
The time is in seconds.
Sample 1: sample of one relationship from an anonymous block to the cursor, using linked variables.
Sample 2: sampling one relationship by procedure, using related variables.
Sample 3: selection of relationships from an anonymous block to the cursor.
Sample 4: The first sample of all relationships by procedure in the cursor.
Sample 5: the subsequent sampling of all relationships by the procedure in the cursor.
Add: time to add n relationships.
I would like to say that if we are talking about 1-2 seconds, then the time is not important at all, but here it should be taken into account that it is assumed that either the real database will be large or the server will be weaker. The fact that the server on which both options were tested is quite powerful also has its drawback: side operations take too much time, which makes it difficult to make comparisons on a small amount of data.
So, adding an interconnection in an alternative variant takes much more (6 times) time than in the standard one, which definitely indicates that the alternative variant is not suitable for cases when a lot (more than 500) links need to be created and destroyed a day. If there are fewer such actions, then from a person’s point of view, the difference will be simply invisible, despite unnecessary actions, such as replacing the verification of a foreign key.
Now about the sample. Sampling from an anonymous block takes just over half a second in all cases. Probably the fact is that most of the time goes to work with the cursor itself. But when sampling a large amount of data (for example, all), the nested table becomes more efficient: it takes almost less time and the only option when the alternative is slower is the first sample of all data.
And finally, the last comparison: query comparison. Personally, I do not see any noteworthy differences.
In general, the idea of creating many-to-many relationships using nested tables was not as hopeless as it seemed at first. Despite the fact that the operations of creating and deleting relationships take an order of magnitude longer, the sampling of even large queries becomes faster, and the structure of the query is approximately the same in complexity. In terms of the complexity of the sample code, both approaches are equally simple, but for creating or deleting a relationship, it is more difficult for an alternative approach.
The relationship should not be implemented using a nested table if:
It makes sense to think about the implementation of the relationship in an alternative way, if
NESTED TABLE ), are rather doubtful for two reasons: you cannot create foreign keys ( FOREIGN KEY ) for types and objects, and it is very easy to implement functionality using an additional table. And it would be possible to find other advantages for nested tables, if not for the fact that after creating the main table, the column of the nested table cannot be changed. You can, of course, create a second type and use it, but this is a fairly large amount of work and, undoubtedly, a lot of concern about existing data.However, I had the idea of implementing many-to-many interconnections (
MANY-TO-MANY RELATIONSHIP ) using a nested table, because the idea is so tempting — instead of a single foreign key, you can store them for a specific record — which could be more logical from a human point of view. logic? But then the question arose - is the game worth the candle?Example
Using the example, it is easier to show the proposed structure, and it is also a good way to check which method loads the system less.
Suppose there is a bus depot spherical in a vacuum. The bus fleet has several buses and several drivers. There are several drivers driving the same bus (several shifts). Features of this park are such that one driver can also ride on several buses, for example, depending on the day of the week.
')
We will create two very simple tables intended only to create relationships between them.
CREATE TABLE tab_bus
( b_id NUMBER PRIMARY KEY
, bus_number VARCHAR2(9) NOT NULL
);
CREATE SEQUENCE seq_bus;
CREATE TABLE tab_driver
( d_id NUMBER PRIMARY KEY
, driver_name VARCHAR2(255) NOT NULL
);
CREATE SEQUENCE seq_driver;
* This source code was highlighted with Source Code Highlighter .CREATE TABLE bus_driver
( bus_id NUMBER
, driver_id NUMBER
, CONSTRAINT pk_driver_bus PRIMARY KEY (bus_id, driver_id)
, CONSTRAINT fk_bus_id FOREIGN KEY (bus_id) REFERENCES tab_bus (b_id)
, CONSTRAINT fk_driver_id FOREIGN KEY (driver_id) REFERENCES tab_driver (d_id)
);
* This source code was highlighted with Source Code Highlighter .PRIMARY KEY ) to two fields ensures that all necessary conditions are met: the contents of the fields (each separately) cannot be empty and each relationship will be unique. In addition, this approach allows you to get rid of additional fields and provides automatic indexing.For creating, deleting and selecting relationships in the example, procedures will be used - for convenience of testing. In addition, it was interesting for me to test it with procedures, because from the point of view of programming it is more convenient than composing queries in the body of the program. It should be noted that there is no commit to one procedure (
COMMIT; ). Firstly, I do it manually when testing, and secondly, the procedures for adding and deleting relationships are started in a loop during testing - in this case, the commit will only interfere.CREATE PROCEDURE add_relation
( p_bus NUMBER
, p_driver NUMBER
) AS
BEGIN
INSERT INTO bus_driver VALUES ( p_bus, p_driver );
END ;
CREATE PROCEDURE drop_relation
( p_bus NUMBER
, p_driver NUMBER
) AS
BEGIN
DELETE bus_driver WHERE bus_id = p_bus AND driver_id = p_driver;
END ;
CREATE PROCEDURE select_relation
( p_data OUT SYS_REFCURSOR
) AS
BEGIN
OPEN p_data FOR
SELECT b.bus_number, d.driver_name
FROM tab_bus b, tab_driver d, bus_driver r
WHERE (b.b_id = r.bus_id) AND (r.driver_id = d.d_id);
END ;
* This source code was highlighted with Source Code Highlighter .WHERE used as a join of the tables ( JOIN 'a). There are two reasons for this: the Oracle is all the same, it considers it a JOIN 'th, and it is more convenient for me to compare the complexity of building SQL query queries.At the creation of the first structure of the relationship is completed. The following relationship scheme was implemented: two tables and an additional table in which the list of relationships is stored.
Next comes the SQL code for the alternative. The second option was created on the exact same table structure, but in a different scheme. And the structure of interrelations looks like this: there are two tables, in one of them each record stores a list of interrelations.
A table can be created immediately with a column of nested tables, but in this case the relationship is constructed from two tables already prepared, so another approach is used: one of the tables is changed.
CREATE OR REPLACE TYPE obj_list AS OBJECT
( r_driver NUMBER
);
CREATE OR REPLACE TYPE nt_list AS TABLE OF obj_list;
ALTER TABLE tab_bus ADD
( bus_drivers nt_list NULL
) NESTED TABLE bus_drivers STORE AS nt_bus_drivers;
* This source code was highlighted with Source Code Highlighter .CREATE FUNCTION check_fk
( p_id NUMBER
) RETURN NUMBER IS
fk_count NUMBER;
BEGIN
SELECT COUNT (d_id) INTO fk_count
FROM tab_driver WHERE d_id = p_id;
RETURN fk_count;
END ;
* This source code was highlighted with Source Code Highlighter .UPDATE , i.e. actually change the whole cell of the record. But subsequent relationships are already added using the INSERT . The procedure assumes that there is already a record, and in the case of an exception it acts as if the record has no connections. It makes no sense to check before attempting to insert a relationship, since this is quite a lot of actions. If it is necessary to process other exceptions and plan to write another code for the general case, then you should clarify the exception handling, add the exception number to the variables and take action on it.CREATE PROCEDURE add_relation
( p_bus NUMBER
, p_driver NUMBER
) AS
BEGIN
IF (check_fk(p_driver) = 1) THEN
INSERT INTO TABLE
( SELECT bus_drivers
FROM tab_bus
WHERE b_id = p_bus
)
VALUES ( obj_list(p_driver) );
ELSE
RAISE_APPLICATION_ERROR(-20665, 'Record doesn' 't exist.' );
END IF ;
DBMS_OUTPUT.PUT_LINE( TO_CHAR( (DBMS_UTILITY.GET_TIME-start_time)/100, '09.99' ) );
EXCEPTION
WHEN OTHERS THEN
UPDATE tab_bus
SET bus_drivers = nt_list ( obj_list(p_driver) )
WHERE b_id = p_bus;
END add_relation;
CREATE PROCEDURE drop_relation
( p_bus NUMBER
, p_driver NUMBER
) AS
BEGIN
IF (check_fk(p_driver) = 1) THEN
DELETE TABLE
( SELECT bus_drivers
FROM tab_bus d
WHERE d.b_id = p_bus
) nt
WHERE nt.r_driver = p_bus;
END IF ;
EXCEPTION
WHEN OTHERS THEN
NULL ;
END drop_relation;
CREATE PROCEDURE select_relation
( p_data OUT SYS_REFCURSOR
) AS
BEGIN
OPEN p_data FOR
SELECT b.bus_number, d.driver_name
FROM tab_bus b, tab_driver d, TABLE (b.bus_drivers) r
WHERE (b.b_id = p_bus) AND (d.d_id = p_driver);
END ;
* This source code was highlighted with Source Code Highlighter .To verify the correctness of the procedures, the same test values were used.
INSERT INTO tab_driver VALUES ( seq_driver.NEXTVAL, 'Viktor Jeliseev' );
INSERT INTO tab_driver VALUES ( seq_driver.NEXTVAL, 'Stepan Kljavin' );
INSERT INTO tab_driver VALUES ( seq_driver.NEXTVAL, 'Marija Baranka' );
INSERT INTO tab_driver VALUES ( seq_driver.NEXTVAL, 'Arsenij Dubov' );
INSERT INTO tab_bus VALUES ( seq_bus.NEXTVAL, 'p666pp' );
INSERT INTO tab_bus VALUES ( seq_bus.NEXTVAL, 'LT-3216' );
INSERT INTO tab_bus VALUES ( seq_bus.NEXTVAL, 'zox-15' );
INSERT INTO tab_bus VALUES ( seq_bus.NEXTVAL, 'x234oo' );
BEGIN
add_relation (1, 3);
add_relation (1, 4);
add_relation (3, 3);
add_relation (3, 2);
add_relation (2, 2);
drop_relation (3, 2);
drop_relation (2, 2);
END ;
DECLARE
g_data SYS_REFCURSOR;
BEGIN
select_relation (1, 4, g_data);
select_relation (3, 3, g_data);
select_relation (2, 2, g_data);
select_relation (1, 1, g_data);
END ;
* This source code was highlighted with Source Code Highlighter .Testing
Testing was conducted several times for each option. First, the samples, procedures, and function were debugged on the above test data. Then procedures were created for each database (in fact, of course, charts), which filled the tables with data using a random number generator. In approximately the same way, a specified number of relationships were created.
CREATE OR REPLACE
PROCEDURE random_insert_data
( record_count NUMBER
) AS
start_time NUMBER DEFAULT DBMS_UTILITY.GET_TIME;
counter NUMBER;
field_value VARCHAR2(255);
BEGIN
FOR counter IN 1..record_count
LOOP
field_value := DBMS_RANDOM.STRING( 'A' , 9);
INSERT INTO tab_bus (b_id, bus_number) VALUES
( seq_bus.NEXTVAL
, field_value
);
END LOOP;
FOR counter IN 1..record_count
LOOP
field_value := INITCAP(DBMS_RANDOM.STRING( 'L' , 6))|| ' ' ||INITCAP(DBMS_RANDOM.STRING( 'L' , 9));
INSERT INTO tab_driver VALUES
( seq_driver.NEXTVAL
, field_value);
END LOOP;
DBMS_OUTPUT.PUT_LINE( TO_CHAR( (DBMS_UTILITY.GET_TIME-start_time)/100, '09.99' ) );
END ;
-- for standart many-to-many relations
CREATE PROCEDURE random_insert_rel
( rel_count NUMBER
, rel_from NUMBER
, rel_to NUMBER
) AS
start_time NUMBER DEFAULT DBMS_UTILITY.GET_TIME;
rel1_value VARCHAR2(255);
rel2_value VARCHAR2(255);
counter NUMBER;
BEGIN
FOR counter IN 1..rel_count
LOOP
rel1_value := ROUND(DBMS_RANDOM. VALUE (rel_from, rel_to));
rel2_value := ROUND(DBMS_RANDOM. VALUE (rel_from, rel_to));
add_relation(rel1_value, rel2_value);
END LOOP;
DBMS_OUTPUT.PUT_LINE( TO_CHAR( (DBMS_UTILITY.GET_TIME-start_time)/100, '09.99' ) );
END ;
-- for standart many-to-many relations
CREATE PROCEDURE random_delete_rel
( rel_count NUMBER
, rel_from NUMBER
, rel_to NUMBER
) AS
start_time NUMBER DEFAULT DBMS_UTILITY.GET_TIME;
rel1_value VARCHAR2(255);
rel2_value VARCHAR2(255);
counter NUMBER;
BEGIN
FOR counter IN 1..rel_count
LOOP
rel1_value := ROUND(DBMS_RANDOM. VALUE (rel_from, rel_to));
rel2_value := ROUND(DBMS_RANDOM. VALUE (rel_from, rel_to));
drop_relation(rel1_value, rel2_value);
END LOOP;
DBMS_OUTPUT.PUT_LINE( TO_CHAR( (DBMS_UTILITY.GET_TIME-start_time)/100, '09.99' ) );
END ;
-- for alternative many-to-many system with nested table
CREATE PROCEDURE random_insert_rel
( rel_count NUMBER
, rel_from NUMBER
, rel_to NUMBER
) AS
start_time NUMBER DEFAULT DBMS_UTILITY.GET_TIME;
rel1_value VARCHAR2(255);
rel2_value VARCHAR2(255);
counter NUMBER;
BEGIN
FOR counter IN 1..rel_count
LOOP
rel1_value := ROUND(DBMS_RANDOM. VALUE (rel_from, rel_to));
rel2_value := ROUND(DBMS_RANDOM. VALUE (rel_from, rel_to));
add_relation(rel1_value, rel2_value);
END LOOP;
DBMS_OUTPUT.PUT_LINE( TO_CHAR( (DBMS_UTILITY.GET_TIME-start_time)/100, '09.99' ) );
END ;
-- for alternative many-to-many system with nested table
CREATE PROCEDURE random_delete_rel
( rel_count NUMBER
, rel_from NUMBER
, rel_to NUMBER
) AS
start_time NUMBER DEFAULT DBMS_UTILITY.GET_TIME;
rel1_value VARCHAR2(255);
rel2_value VARCHAR2(255);
counter NUMBER;
BEGIN
FOR counter IN 1..rel_count
LOOP
rel1_value := ROUND(DBMS_RANDOM. VALUE (rel_from, rel_to));
rel2_value := ROUND(DBMS_RANDOM. VALUE (rel_from, rel_to));
drop_relation(rel1_value, rel2_value);
END LOOP;
DBMS_OUTPUT.PUT_LINE( TO_CHAR( (DBMS_UTILITY.GET_TIME-start_time)/100, '09.99' ) );
END ;
* This source code was highlighted with Source Code Highlighter .results
Testing was conducted on data in the amount of n = 4, 1000, 100000. It is assumed that there are n records in each table, and also n relationships are created. Testing was carried out on 10 positions, the table below presents 6 of them, which have the most significant differences in time and display the most significant data.
During testing, a distinction was made between the first sample and the subsequent ones, as well as between the sample using a query or a procedure that places data on the cursor. The main measurements were made to create relationships and different variants of samples. Deleting relationships is not included in this list, since a random number generator is used and it is likely that almost all attempts to delete relationships will turn into inaction.
| way to write | sample 1 | sample 2 | sample 3 | sample 4 | sample 5 | creature |
| additional table 4 | 00.844 | 00.792 | 00.967 | 00.01 | 00.02 | 00.032 |
| at. table 4 | 00.694 | 00.707 | 00.026 | 00.00 | 00.00 | 00.034 |
| additional table, 1000 | 00.642 | 00.645 | 00.698 | 00.02 | 00.02 | 00.142 |
| at. table, 1000 | 00.687 | 00.695 | 00.344 | 00.00 | 00.00 | 00.721 |
| additional table, 100,000 | 00.648 | 00.697 | 01.323 | 00.14 | 00.49 | 14.613 |
| at. table, 100,000 | 00.741 | 00.829 | 01.117 | 00.00 | 00.00 | 84.630 |
The time is in seconds.
Sample 1: sample of one relationship from an anonymous block to the cursor, using linked variables.
Sample 2: sampling one relationship by procedure, using related variables.
Sample 3: selection of relationships from an anonymous block to the cursor.
Sample 4: The first sample of all relationships by procedure in the cursor.
Sample 5: the subsequent sampling of all relationships by the procedure in the cursor.
Add: time to add n relationships.
I would like to say that if we are talking about 1-2 seconds, then the time is not important at all, but here it should be taken into account that it is assumed that either the real database will be large or the server will be weaker. The fact that the server on which both options were tested is quite powerful also has its drawback: side operations take too much time, which makes it difficult to make comparisons on a small amount of data.
So, adding an interconnection in an alternative variant takes much more (6 times) time than in the standard one, which definitely indicates that the alternative variant is not suitable for cases when a lot (more than 500) links need to be created and destroyed a day. If there are fewer such actions, then from a person’s point of view, the difference will be simply invisible, despite unnecessary actions, such as replacing the verification of a foreign key.
Now about the sample. Sampling from an anonymous block takes just over half a second in all cases. Probably the fact is that most of the time goes to work with the cursor itself. But when sampling a large amount of data (for example, all), the nested table becomes more efficient: it takes almost less time and the only option when the alternative is slower is the first sample of all data.
And finally, the last comparison: query comparison. Personally, I do not see any noteworthy differences.
| SELECT b.bus_number, d.driver_name FROM tab_bus b, tab_driver d, bus_driver r WHERE (b.b_id = r.bus_id) AND (r.driver_id = d.d_id); | SELECT b.bus_number, d.driver_name FROM tab_bus b, tab_driver d, TABLE (b.bus_drivers) r WHERE (b.b_id = p_bus) AND (d.d_id = p_driver); |
findings
In general, the idea of creating many-to-many relationships using nested tables was not as hopeless as it seemed at first. Despite the fact that the operations of creating and deleting relationships take an order of magnitude longer, the sampling of even large queries becomes faster, and the structure of the query is approximately the same in complexity. In terms of the complexity of the sample code, both approaches are equally simple, but for creating or deleting a relationship, it is more difficult for an alternative approach.
The relationship should not be implemented using a nested table if:
- It is necessary to create and delete them often and much (it takes too much time);
- There are few tables in general or the structure of the database as a whole is simple (the relationship will take too much time to write the procedures for adding and deleting them);
- The data logic implies the equivalence of the objects being linked (it is impossible to decide in which table to create a column of interrelations).
It makes sense to think about the implementation of the relationship in an alternative way, if
- One table is connected by the principle of many-to-many with several others (simplifies the understanding of the structure and logic of the data);
- Relationships are created and deleted quite rarely and in one and linked tables records are deleted and added not too often (there is no loss in speed);
- To work with the database, only procedures, views, and possibly sampling are used;
- There is a need to implement a foreign key on several tables, rather than on one (a more elegant solution, in contrast to creating several columns, especially since the function of checking the field identifier correspondence is needed anyway).
Source: https://habr.com/ru/post/100050/
All Articles